
RAG (Retrieval-Augmented Generation)는 AI의 더욱 정교한 응답을 가능하게 하는 중요한 기술로 자리 잡았습니다. 특정 도메인의 전문 지식을 활용해 맞춤형 응답을 생성하는 데 탁월하기 때문인데요. 이 과정에서 가장 중요한 점은 데이터를 구조화하고 효율적으로 검색하는 것입니다. 이번 글에서는 RAG의 데이터 구조화에 필수적인 청킹 기술에 대해 자세히 알아보겠습니다.
데이터 구조화란?
데이터 구조화는 AI가 데이터를 이해하고 처리할 수 있도록 체계적으로 정리하는 과정을 말합니다. 다양한 형태의 문서(예: PDF, 엑셀, 텍스트 등)를 적절한 크기로 나누고, 이를 AI가 빠르게 검색하고 활용할 수 있도록 정리해야 하지요. RAG의 핵심은 데이터를 검색하고 결합하는 과정에서 시작되는 만큼, RAG에서 데이터 처리 과정이 어떻게 이루어지는지 먼저 알아보겠습니다. 풀스택 데이터 리트리벌(Full-Stack Data Retrieval) RAG가 데이터를 처리하는 전체적인 과정을 이해하기 위해서는 풀스택 데이터 리트리벌(Full-stack Data Retrieval)를 알아야 하는데요. Full-Stack Data Retrieval은 RAG의 데이터를 처리하는 방법론을 전체적으로 설명하는 용어로 이해할 수 있습니다.
‘Full-Stack Data Retrieval’ 이란?
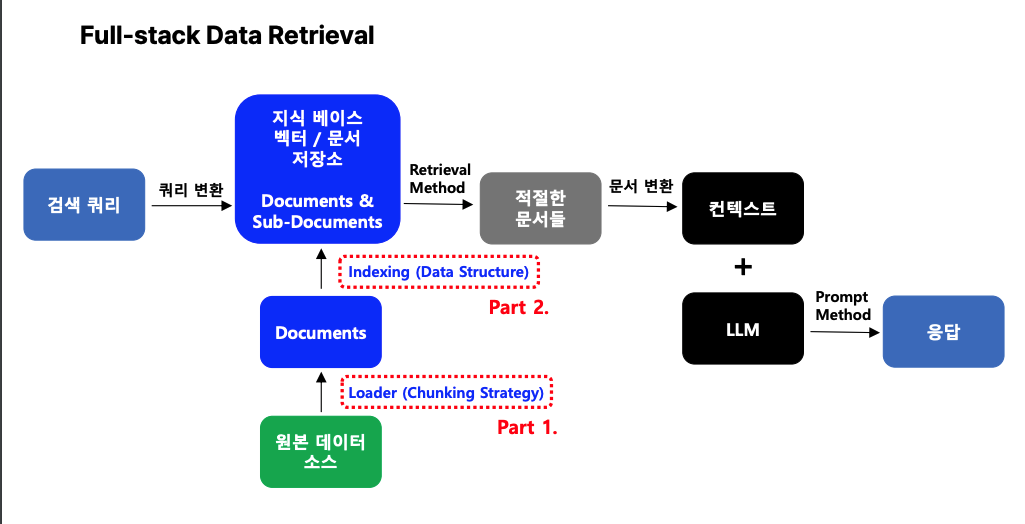
RAG가 데이터를 처리하는 전체적인 파이프라인. 색 쿼리와 자료 구조 간의 관계를 빠르고 효율적으로 리트리빙하는 데 중요한 역할을 합니다.
- 검색 쿼리 (Query Input)
사용자가 입력한 질문(프롬프트)이 데이터 검색의 출발점이 됩니다. - 원본 데이터 소스 (Original Data Sources)
문서, 데이터베이스, PDF, 엑셀 등 다양한 형태의 원본 데이터를 의미합니다. 여기서 필요한 데이터를 추출하는 과정이 시작됩니다.
- Loader (Chunking Strategy)
데이터를 의미 단위로 잘게 나누는 청킹(Chunking) 작업이 이루어집니다. 이 단계에서는 데이터를 적절히 나누어 AI가 처리하기 쉽게 준비합니다. - Documents
청킹된 데이터를 하나의 문서 단위로 정리합니다. 이 데이터는 다음 단계에서 인덱싱되어 검색 가능하도록 준비됩니다. - Indexing (Data Structure) – 데이터 구조화
청킹된 문서들을 효율적으로 검색할 수 있도록 인덱싱(Indexing) 작업을 수행합니다. 데이터를 구조화하여 벡터나 문서 저장소에 저장합니다. - 지식 베이스 벡터/문서 저장소
인덱싱된 데이터가 저장되는 공간입니다. 질문(쿼리)에 적합한 데이터를 빠르게 찾기 위해 이 저장소를 활용합니다. - Retrieval Method
사용자가 입력한 쿼리를 벡터 형태로 변환하여, 저장된 데이터와 비교 및 검색합니다. 이 과정에서 유사도가 높은 데이터를 선택하여 문서 형태로 반환합니다. - 컨텍스트 생성 및 응답
검색된 문서들은 응답 생성을 위해 준비됩니다. 검색된 데이터를 컨텍스트(Context)로 구성한 뒤 LLM에 입력, LLM은 컨텍스트와 질문을 기반으로 답변을 생성합니다.
‘Full-Stack Data Retrieval’ 이란?
RAG가 데이터를 처리하는 전체적인 파이프라인. 색 쿼리와 자료 구조 간의 관계를 빠르고 효율적으로 리트리빙하는 데 중요한 역할을 합니다.
- 검색 쿼리 (Query Input)
- 사용자가 입력한 질문(프롬프트)이 데이터 검색의 출발점이 됩니다.
- 원본 데이터 소스 (Original Data Sources)
- 문서, 데이터베이스, PDF, 엑셀 등 다양한 형태의 원본 데이터를 의미합니다.
- 여기서 필요한 데이터를 추출하는 과정이 시작됩니다.
- Loader (Chunking Strategy)
- 데이터를 의미 단위로 잘게 나누는 청킹(Chunking) 작업이 이루어집니다.
- 이 단계에서는 데이터를 적절히 나누어 AI가 처리하기 쉽게 준비합니다.
- Documents
- 청킹된 데이터를 하나의 문서 단위로 정리합니다.
- 이 데이터는 다음 단계에서 인덱싱되어 검색 가능하도록 준비됩니다.
- Indexing (Data Structure) – 데이터 구조화
- 청킹된 문서들을 효율적으로 검색할 수 있도록 인덱싱(Indexing) 작업을 수행합니다.
- 데이터를 구조화하여 벡터나 문서 저장소에 저장합니다.
- 지식 베이스 벡터/문서 저장소
- 인덱싱된 데이터가 저장되는 공간입니다.
- 질문(쿼리)에 적합한 데이터를 빠르게 찾기 위해 이 저장소를 활용합니다.
- Retrieval Method
- 사용자가 입력한 쿼리를 벡터 형태로 변환하여, 저장된 데이터와 비교 및 검색합니다.
- 이 과정에서 유사도가 높은 데이터를 선택하여 문서 형태로 반환합니다.
- 컨텍스트 생성 및 응답
- 검색된 문서들은 응답 생성을 위해 준비됩니다.
- 검색된 데이터를 컨텍스트(Context)로 구성한 뒤 LLM에 입력, LLM은 컨텍스트와 질문을 기반으로 답변을 생성합니다.
청크 최적화란?
청크 최적화 (Chunk Optimization)
위에서 확인한 데이터 처리 과정에서는 다양한 기술이 필요합니다. 리컬시블 리트리벌(Recursible Retrieval), 하이브리드 리트리벌(Hybrid Retrieval), 리랭킹(Re-ranking), 디코딩 튜닝(Decoding Tuning) 등 RAG에서 정보 검색의 효율성과 정확성을 높이기 위한 다양한 검색 및 조정 기술들이 있습니다. 이 기술들이 잘 운영되기 위해서는 원본 데이터가 검색에 용이하게 만드는 데이터 구조화 과정인 ‘청크 최적화(Chunk Optimization)’이 필요합니다.
‘Chunk Optimization’이란?
- 데이터를 AI가 효과적으로 이해할 수 있도록 적절한 크기로 쪼개는 기술을 말합니다. 청크가 최적화되면 데이터 검색 및 활용의 품질이 높아집니다. 반대로 잘못된 청킹은 잘못된 데이터 검색으로 이어질 위험을 높이죠.
- 중요한 것은 데이터를 단순히 나누는 것만이 아니라 의미적으로 유사한 내용을 하나로 묶어 청크의 밀집도를 높이는 것입니다. 청크의 정보 밀집도가 높아질수록 AI가 질문에 정확히 답변할 수 있는 확률이 증가하기 때문이죠. 또한, 최신 청킹 기술을 통해 데이터를 효율적으로 분할하면, LLM의 프롬프트 사이즈가 커져도 적절한 정보를 밀집되게 제공할 수 있습니다.
- Token Overlap (토큰 중첩)
잘못된 청킹은 중요한 정보를 손실할 수 있습니다. 이 문제를 방지하기 위해 토큰 중첩(Token Overlap) 기술이 사용됩니다. 일정 부분의 토큰을 겹치게 청킹함으로써 데이터 손실을 방지합니다. - 청킹 전략
- 단순 청킹 (Fixed-Size Chunking): 고정된 길이로 데이터를 나눔
- 구조 기반 청킹 (Document-Based Chunking): 문서의 구조를 바탕으로 나눔
- 의미 기반 청킹 (Semantic Chunking): 데이터의 의미를 기준으로 나눔
- 에이전트 기반 청킹 (Agentic Chunking): 명제 중심으로 데이터를 분석하고 나누는 고도화된 방식
RAG에서 데이터 구조화와 청크 최적화(Chunk Optimization)는 AI가 정교하고 정확한 답변을 생성하는 핵심 단계입니다. 데이터를 의미 있게 나누고 체계적으로 구조화함으로써 AI는 더 빠르고 정확하게 필요한 정보를 찾아낼 수 있지요. 특히, 의미 기반 청킹(Semantic Chunking)과 Token Overlap(토큰 중첩) 같은 최적화 기술을 활용하면 데이터 검색과 응답 생성의 효율성이 크게 향상됩니다.
다음 글에서는 청킹 및 인덱싱(Chunking & Indexing)에 대해 깊이 있게 살펴보고, 청킹 전략의 레벨을 단계별로 분석할 예정입니다. 각 청킹 전략이 어떤 상황에서 가장 효과적인지, 그리고 인덱싱과의 유기적 결합이 어떻게 RAG의 성능을 극대화하는지 기대해 주세요!


