알리바바가 오픈소스 LLM인 Qwen3를 출시했습니다. Qwen3는 코딩, 수학, 일반 추론 등 다양한 벤치마크에서 DeepSeek-R1, Gemini 2.5, Grok-3 등 최신 모델들과 어깨를 나란히 합니다. 특히 MoE(Mixture of Experts) 아키텍처를 활용해 더 적은 활성 파라미터로도 뛰어난 성능을 보여주며, ‘생각하는 모드’와 ‘빠른 응답 모드’를 자유롭게 전환할 수 있는 유연성과 119개 언어/방언 지원까지 갖췄습니다. 한 번 살펴보겠습니다.
Qwen3 성능
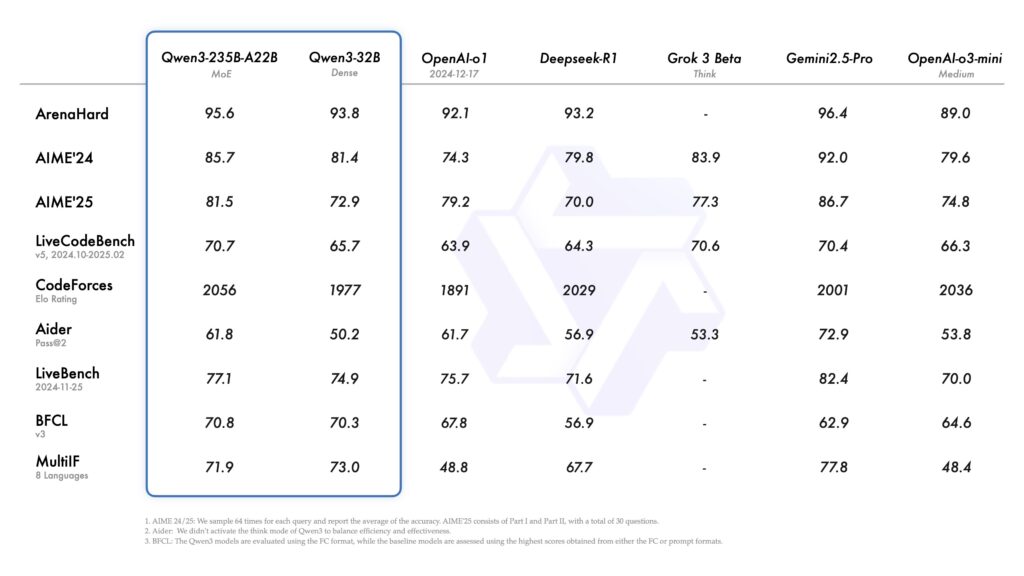
Qwen3의 대표 모델인 Qwen3-235B-A22B는 DeepSeek-R1, Gemini 2.5, o1, o3-mini, Grok-3 등 주요 경쟁 모델들과 코딩, 수학, 일반 상식 분야에서 동등하거나 더 뛰어난 성능을 보입니다. 특히 Mixture-of-Experts (MoE) 구조를 채택해, 총 파라미터 수는 235B(2350억)이지만, 실제 활성화되는 파라미터는 22B(220억)에 불과해 효율성과 성능의 균형을 잡았습니다.
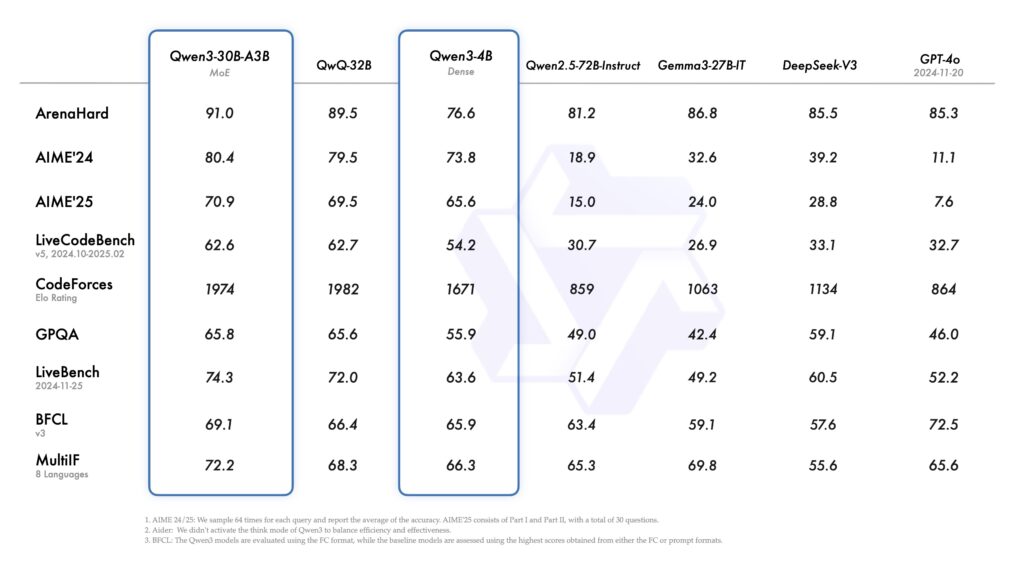
또한 소형 MoE 모델인 Qwen3-30B-A3B는 총 파라미터 수 300억, 활성 파라미터 30억으로, 무려 10배 더 많은 파라미터를 가진 모델을 능가하는 성능을 보여줍니다.
작은 모델도 강력합니다. 예를 들어 Qwen3-4B는 과거의 대형 모델인 Qwen2.5-72B를 성능 면에서 위협할 정도입니다.
Qwen3 주요기능
하이브리드 사고 모드: “생각하는 AI”의 유연성
Qwen3의 가장 주목할 만한 혁신 중 하나는 하이브리드 사고 모드(Hybrid Thinking Modes)입니다.
Thinking Mode: 문제를 단계별로 깊이 있게 사고한 후 답변. 복잡한 논리나 수학 문제에 적합.
Non-Thinking Mode: 즉각적이고 간결한 응답을 제공. 짧고 단순한 질문에 적합.
사용자는 상황에 따라 AI의 사고 모드를 조절하여, 더 깊이 있는 추론이 필요한 경우 ‘생각 모드’를 활성화하거나, 빠른 응답이 필요한 경우 ‘비생각 모드’를 사용할 수 있습니다. 이를 통해 연산 자원 소비와 응답 품질 사이의 균형을 유연하게 조절할 수 있으며, 특히 멀티턴 대화나 연산 비용이 중요한 환경에서 효과적입니다.
119개 언어·방언 지원
Qwen3는 119개의 언어 및 방언을 지원합니다. 영어, 중국어, 한국어는 물론이고, 힌디어, 아랍어, 터키어, 타갈로그어, 러시아어, 루마니아어, 아이슬란드어 등 전 세계 주요 언어를 폭넓게 다룹니다.
이번 모델은 단순 번역을 넘어, 다양한 언어적 맥락에서의 대화와 추론을 수행할 수 있는 다국어 지능을 의미하는데요. 국제적 애플리케이션이나 다국어 서비스 구축에 기반을 제공할 수 있습니다.
MCP를 통한 에이전트 활용
Qwen3는 코딩과 에이전트 기능에 최적화된 모델입니다.
외부 툴 연동을 위한 MCP(Model Context Protocol) 지원이 강화되었으며, 이를 바탕으로 Qwen-Agent 프레임워크를 통해 다양한 도구들을 호출하고, 환경과 상호작용하는 실행 가능한 AI 에이전트로 확장할 수 있습니다.
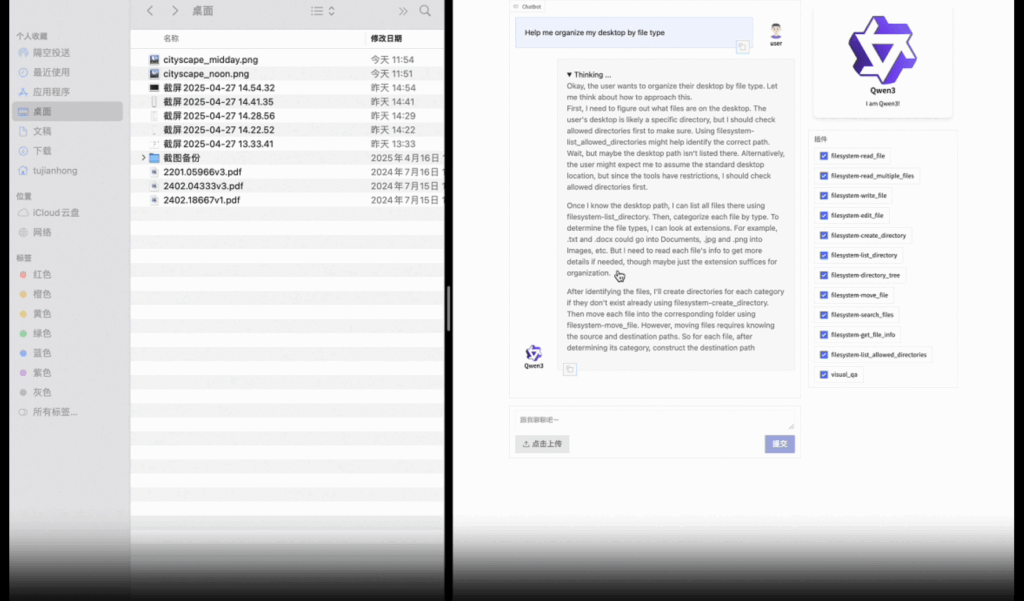
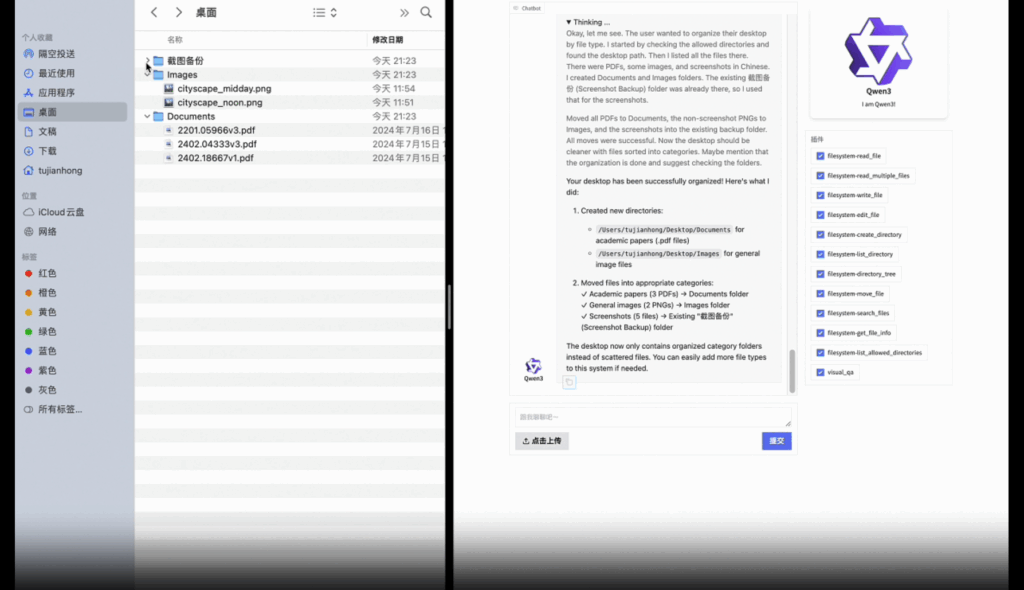
Qwen3에게 파일을 타입별로 정리해 달라고 요청하자(위), 임무를 완수한 모습(아래). 출처: Qwen
개발자 친화적 배포 환경
Qwen3는 Hugging Face, ModelScope, Kaggle 등에서 모델 가중치를 제공하며, 로컬에서 실행하거나 API 서버로 배포하는 다양한 방법을 지원합니다. 프레임워크 및 도구 예시입니다:




![AI는 책을 ‘도둑질’해도 될까? [미국 법원 판결]](https://selectstar.ai/wp-content/uploads/2025/07/kamran-abdullayev-FR3M0W3T2RY-unsplash-scaled.jpg)