
"Cogito, ergo sum."
나는 생각한다, 고로 존재한다.
데카르트는 인간을 ‘사고하는 존재’로 정의하며, 존재의 의미를 사고하는 능력에 두었습니다. 수백 년이 지난 지금, 우리는 마치 스스로 사고하는 것 같은 인공지능을 마주하고 있는데요.
최근, 메타의 LLaMA 4와 딥시크의 R1 모델을 능가한다고 발표된 한 LLM이 주목받고 있습니다. 구글 전 수석 소프트웨어 엔지니어 드리샨 아로하가 설립한 AI 회사, Deep Cogito(딥코기토)에서 만든 모델입니다. 데카르트의 철학에서 직접 가져온 듯한 이름은 단순한 브랜드명을 넘어, 비전을 담고 있는 듯 합니다.
과연, 딥코기토의 모델 Cogito V1는 '사고'를 하는 모델일까요?
인간보다 뛰어난 AI, Superintelligence
딥코기토가 공개한 언어 모델 시리즈는 단순한 오픈소스 모델 발표가 아닙니다. 기존의 훈련 방식에서 벗어나, AI가 스스로를 개선하는 학습 구조를 실제로 구현한 사례인데요. 모든 인지적 측면에서 인간보다 뛰어난 AI를 뜻하는 ‘초지능(Superintelligence)’에 한 걸음 더 가까이 다가갔다고 볼 수 있습니다.
사실, AI가 인간을 능가할 수 있다는 가능성은 이미 몇 차례 현실로 드러난 바 있습니다. 2016년, 이세돌 선수와 세기의 바둑 대결을 펼친 알파고를 기억하시나요?

이세돌 선수가 알파고와 바둑을 두는 모습과 최종 결과. 출처: Google, 동아일보
당시만 해도 인간인 이세돌 선수가 압승을 하리라는 예측이 압도적이었지만, 이세돌 선수는 5전 1승을 거두었습니다. 이후 알파고를 비롯한 여러 게임 AI들은 제한된 환경 내에서 초인적인 성능을 보여주며, ‘좁은 영역(narrow domains)’에서는 AI가 인간을 넘어설 수 있다는 사실을 입증했지요.
이를 가능하게 한 두 가지 핵심 요소는 다음과 같았습니다:
- 고급 추론 능력: 더 많은 계산 자원을 활용해, 기존보다 훨씬 뛰어난 해법을 도출하는 능력
- 반복적인 자기 개선: 외부 감독자의 한계에 얽매이지 않고, 스스로 지능을 정제하는 능력
하지만 알파고는 사전에 정해진 규칙과 목표가 존재하는 제한된 영역이었고, 바둑 밖의 세계에 대해선 전혀 아무것도 몰랐습니다. 하지만 진짜 초지능은 이런 제한된 틀을 벗어나, 새로운 문제를 스스로 정의하고 해결할 수 있는 능력까지 포함합니다. 딥코기토는 특정 영역이 아니라, 모든 분야에 일반화될 수 있는 초지능의 구조를 실험 중입니다.
현재 공개된 코기토의 3B, 8B, 14B, 32B, 70B 모델은 기존 오픈모델(LLaMA, DeepSeek, Qwen 등)을 대부분의 벤치마크에서 능가하는 성능을 보이고 있습니다. 특히 70B 모델은 최근 출시된 LLaMA 4 109B MoE 모델보다 더 뛰어난 성능을 일부 영역에서 기록해 더욱 주목받고 있는데요. 어떻게 학습시킨 걸까요?
코기토의 핵심 전략을 알아보자
딥코기토는 영역의 한계를 극복하고자, 그동안 이론적으로만 제안되어 오던 IDA(Iterated Distillation and Amplification, 반복 증류 및 증폭)라는 전략을 실제로 구현하여 모델을 훈련했습니다.
IDA는 다음 두 단계를 반복하면서 모델을 점진적으로 발전시키는데요:
1단계: 증폭(Amplification)
모델에 더 많은 계산 자원을 할당하여, 다단계 추론이나 도구 사용과 같이 보다 정교한 사고 과정을 실행하도록 합니다. 즉, 모델이 스스로보다 더 높은 수준으로 사고하도록 능력을 ‘증폭’시키는 단계입니다.
2단계: 증류(Distillation)
1단계에서 ‘증폭’된 고차원적인 사고 결과를 모델의 파라미터 안에 내재화하여, 향후 유사한 문제를 빠르고 효율적으로 풀 수 있게 만듭니다. 복잡하고 계산 비용이 큰 사고 과정을 모델 자체에 흡수시키는 단계라고 볼 수 있습니다.
이 두 단계를 반복하면서 모델은 매 반복마다 스스로를 더 지능적으로 개선하게 됩니다. 놀랍게도 인간의 지시나 데이터 없이도 가능한 구조인데요. 모델의 성능은 더 이상 ‘감독자’의 능력에 제한되지 않고, 계산 자원과 알고리즘 효율성에 따라 무한히 확장될 수 있다는 의미입니다. 인간의 피드백이 필요했던 기존 방식의 한계를 벗어나는 구조이기 때문에, 장기적으로 초지능 실현 가능성을 기대하게 합니다.
실제 성능은 어떨까?
딥코기토는 이번에 총 다섯 가지 모델 크기(3B, 8B, 14B, 32B, 70B)를 공개했습니다. 각 모델은 기존 오픈소스 모델들과의 비교에서도 매우 뛰어난 성능을 입증했는데요.
특히 Cogito 70B 모델은 LLaMA 3 70B 모델은 물론, 메타의 최신 모델인 LLaMA 4 109B Scout 모델을 일부 벤치마크에서 능가했습니다.
무엇보다 놀라운 점은, 이 모델들이 단 75일 만에 소규모 팀에 의해 훈련되었다는 점인데요. 단순히 딥코기토의 기술력이 뛰어나다는 사실을 넘어, 이론으로만 존재하던 IDA 전략이 기존 방식보다 훨씬 효율적이고 확장 가능하다는 강력한 증거로 해석할 수 있습니다.
코기토 모델들은 일반적인 LLM처럼 즉각적인 응답이 가능할 뿐 아니라, 자체적인 사고 과정을 거쳐 더 나은 답변을 생성하는 추론 모드도 지원합니다. 또한 3B와 8B 같은 비교적 작은 모델에서도 도구 호출(tool calling) 기능을 제공하고 있어, 실제 서비스나 에이전트 기반 활용에도 매우 적합한 구조를 갖추고 있습니다.
능가했다는 모델, LLaMA 4는 어떤 모델일까?
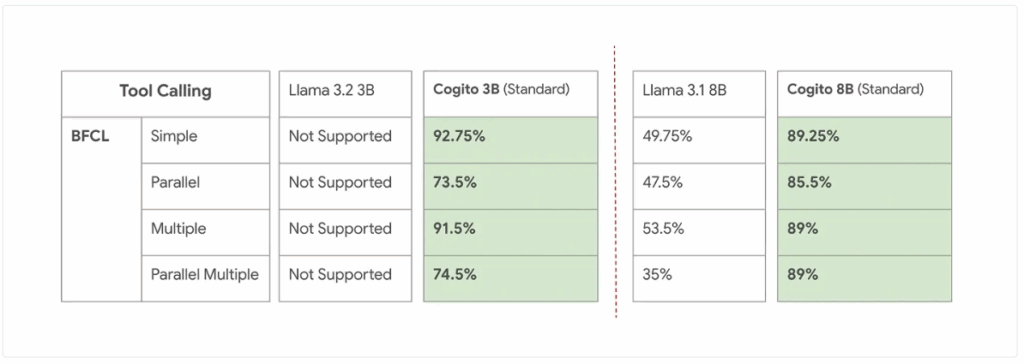
Cogito 3B와 8B의 도구 호출 능력. 출처: Deep Cogito.
데카르트는 ‘나는 생각한다, 고로 존재한다’고 말했습니다. AI가 ‘생각’마저 대신하게 되는 순간, 우리는 인간의 존재를 어디에서 다시 정의해야 할까요?


