
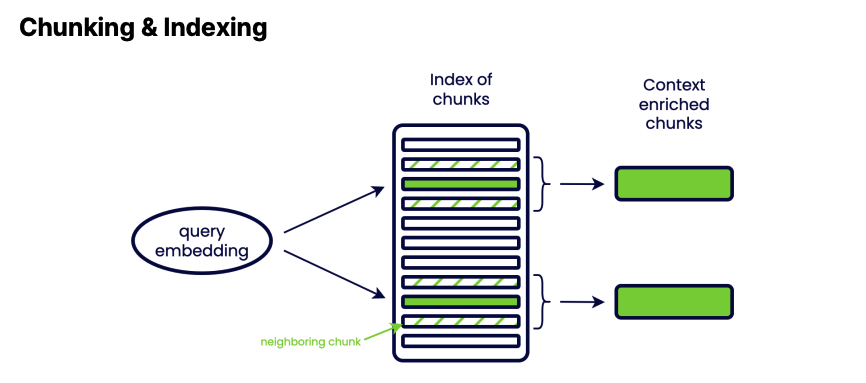
청킹된 데이터를 효과적으로 검색하기 위해서는 인덱싱(Indexing)이 필수입니다. 인덱싱이란 청킹한 데이터를 효율적으로 검색할 수 있도록 데이터베이스에 저장하는 과정을 말합니다.
인덱싱된 데이터는 검색 쿼리와의 유사도를 계산해 적절한 데이터를 빠르게 검색하는 데 도움을 주고, 복잡한 검색 요청에도 정확하고 신속하게 답변할 수 있는 인프라를 구축할 수 있습니다.
청킹과 인덱싱
정확한 검색을 위한 청킹 전략 (Chunking Strategy)
AI가 글을 읽고 대답을 잘하려면, 글을 어떻게 잘게 나누는지가 정말 중요합니다. 왜냐하면 AI는 글을 한꺼번에 많이 읽지 못하기 때문이죠. 특히 한국어처럼 복잡한 글은 더 어렵습니다. 그래서 청킹이 필요합니다.
하지만 그냥 무작정 나누면 안 됩니다. 청크(잘게 나눈 글 조각)가 충분히 많은 정보를 담고 있어야, AI가 질문에 정확히 답할 수 있어요. 예를 들어, 글의 중요한 부분만 포함되어야 하는데, 그렇지 않으면 대답이 엉뚱할 수 있겠죠? 정보의 밀집도가 높은 청크일수록 AI가 적절한 맥락을 이해하고 더 정확하게 응답할 수 있기 때문에, 청킹 과정에서 정보의 밀도와 연관성을 고려하는 것이 매우 중요합니다.
청킹 전략의 레벨 : Level 1~5
청킹은 데이터를 나누는 방식에 따라 다양한 레벨로 구분됩니다. 각 레벨은 데이터의 복잡도와 필요한 정보의 밀집도에 따라 다르게 적용되며, 이를 통해 AI가 효율적으로 정보를 검색하고 활용할 수 있도록 돕습니다. 다음은 청킹의 주요 레벨 구분입니다.
Level 1~3: 단순 청킹
- Level 1 – Fixed-sized Chunking: 일정한 글자 수(예: 500자)로 문서를 나눔. 글의 맥락이나 구조를 무시하기 때문에 문장이 어색하게 끊길 수 있음.
- Level 2 – Recursive Chunking: 띄어쓰기나 문장 단위로 데이터를 나눔. 어느정도 글의 구조를 반영하지만 의미가 끊길 가능성 있음.
- Level 3 – Document-based Chunking: 문서의 구조(예: 섹션, 제목)에 따라 청킹. 타겟 문서가 ‘명확한 구조’를 가지고 있다면, 글의 전체 흐름 및 구조에 맞게 청킹이 가능.
- Document with Markdown : 문서가 Markdown 형식(예:
# 제목,- 목록,--- 구분선)으로 작성되어 있을 때, Markdown에서 사용하는 구분자(separator)를 기준으로 나눕니다. (예.#을 기준으로 섹션별로 나누거나,-로 작성된 목록을 하나의 청크로 묶습니다) - Document with Python/JS : 파이썬이나 자바스크립트 코드에서는
class,function같은 코드 구조를 기준으로 나눕니다. (예. 하나의 함수(def)나 클래스(class)를 하나의 청크로 묶습니다) - Document with Tables
- 표로 구성된 문서는 Lv 1이나 Lv 2 방식(글자 수 기준, 띄어쓰기 기준)으로 나누면 적절하지 않습니다. 대신 표의 정보를 LLM이 이해할 수 있는 구조로 변환해야 합니다.
- 표를 Markdown 형태로 변환하거나, 표의 전체 내용을 요약해 임베딩 벡터(숫자 형태 데이터)로 저장하고, 나중에 AI가 시멘틱 서치(의미 검색) 시 이를 활용할 수 있도록 합니다.
- Document with Images (Multi-Modal) : 이미지가 포함된 문서의 경우, AI가 이미지를 직접 이해하기 어려우므로, 멀티모달(Multi-Modal) LLM을 활용해 이미지를 설명하는 텍스트를 추출합니다. 이미지 설명을 벡터로 변환(임베딩)하여 저장하고, AI가 검색 및 분석 시 이를 활용할 수 있도록 합니다.
- Document with Markdown : 문서가 Markdown 형식(예:
이처럼 청킹 방식에 따라 데이터의 의미와 연결성이 달라질 수 있으며, 각 레벨마다 장단점이 존재합니다.

Level 4~5: 고도화된 청킹
- Level 4 – Semantic Chunking : AI가 문장 간의 의미적 유사성을 분석하여 자연스럽게 정보를 묶는 방법. 단순히 글자 수나 구조에 의존하지 않고, 문장 의미가 달라지는 지점을 기준으로 청크를 나눔.
- 방법
- 문장을 임베딩 벡터로 변환
- 문서의 처음부터 각 문장이나 여러 문장을 묶어 임베딩 벡터(숫자 데이터)로 변환합니다.
- 임베딩 벡터는 AI가 텍스트의 의미를 숫자로 이해할 수 있도록 바꾼 결과입니다.
- 임베딩 벡터 간 유사도 계산
- 연속된 문장 간의 의미적 유사도를 계산합니다. 여기서는 코사인 유사도(Cosine Similarity)를 사용해 문장들이 얼마나 비슷한지 수치화합니다.
- 유사도가 급격히 감소하는 Breakpoint 기준으로 청킹
- 코사인 유사도가 급격히 떨어지는 지점(유사도가 낮아지는 지점)을 “Breakpoint”로 간주하여 청크를 나눕니다. (예: 그래프에서 붉은 수평선(threshold)이 Breakpoint를 결정하는 기준)
- 문장을 임베딩 벡터로 변환
- 방법
- Level 5 – Agentic Chunking : AI가 명제(Proposition)를 중심으로 직접 청킹을 수행. AI가 문서에서 핵심 내용을 추출하고 이를 기준으로 청킹. 정보의 밀집도와 명제 간의 관계를 최적화하여 질문에 답변. 가장 발전된 방법으로, 정보를 잘못 나눌 위험이 적음.
- 방법
- 명제(Proposition) 추출
- AI를 통해 문서에서 핵심 명제를 추출합니다.
- 명제는 간결하고 독립적인 단위로, 하나의 주요 아이디어나 사실을 담고 있습니다.
- 명제를 청크에 포함시키기
- 추출한 명제를 AI에게 입력하고, AI가 해당 명제가 기존 청크에 속하는지, 새로운 청크를 만들어야 하는지 판단합니다.
- 이 과정은 LLM의 프롬프팅을 활용해 이루어집니다.
- 청크 속성 업데이트
- 기존 청크에 속한다면 청크의 요약본 등 속성을 업데이트합니다.
- 새로운 청크라면 명제를 중심으로 새로운 청크를 생성합니다.
- 명제(Proposition) 추출
- 방법
이처럼 Level 4 (Semantic Chunking)와 Level 5 (Agentic Chunking)는 모두 데이터를 더욱 정교하게 구조화하여 AI가 정보를 효율적으로 처리할 수 있도록 돕지만, 접근 방식과 청킹의 주체가 다릅니다.
- Level 4 – Semantic Chunking : AI가 문장 간의 의미적 유사성을 분석하여 자연스럽게 정보를 묶는 방법. 단순히 글자 수나 구조에 의존하지 않고, 문장 의미가 달라지는 지점을 기준으로 청크를 나눔.

위 사례를 통해 두 레벨이 어떻게 작동하는지를 보여줍니다. Level 4에서는 문장 간 유사도를 통해 청크를 나누고, Level 5에서는 AI가 명제를 기준으로 청크를 생성하거나 기존 청크 속성를 업데이트합니다.
데이터 구조화와 청킹 기술은 RAG의 성능을 결정짓는 중요한 요소입니다. 특히, 청킹 레벨에 따른 전략적 접근은 AI가 복잡한 질문에 대해 얼마나 정교하게 답변할 수 있는지를 좌우합니다. 다음 글에서는 데이터 구조화의 또 다른 핵심인 ‘정확한 검색을 위한 자료 구조’를 다룹니다. 트리와 그래프 기반 접근법과 같은 RAG 시스템을 한층 더 고도화하는 전략을 알아보도록 하겠습니다.


