
자연어 생성(Natural Language Generation) 분야에서 “좋은 텍스트”를 평가하는 일은 늘 어렵습니다. 인간의 직관과 일치하도록 텍스트의 품질을 가늠하는 작업은 특히나 창의적이거나 개방형인 작업일수록 까다롭지요. 기존의 평가 지표인 BLEU나 ROUGE는 성능을 수치화하는 데 유용하지만, 대화나 요약과 같은 작업에서 요구되는 다양성과 창의성을 제대로 반영하지 못한다는 한계가 있습니다.
작년 5월, G-EVAL은 GPT-4의 고급 언어 이해 능력을 바탕으로 인간의 평가와 가까운 결과를 제공하는 혁신적 프레임워크로 떠올랐습니다. 이 새로운 패러다임은 NLG 평가 방식을 어떻게 변화시켰을까요?
G-EVAL의 핵심: 목적과 중요성
G-Eval은 프롬프트 채우기 방식(“form-filling”)을 통해 모델이 생성한 텍스트를 평가하는 새로운 방식인데요. 이러한 방식은 LLM을 이용한 평가(LLM-as-a-Judge) 방법 중에 프롬프트를 이용한 평가 방식으로 널리 쓰이는 방법입니다. 프롬프트를 이용한 평가에서 일반적으로 프롬프트를 구성하는 네 가지 요소가 있는데요:
1. Task instruction
2. Evaluation criteria
3. Input contents
4. Evaluation methods
위 항목으로 전체 프롬프트를 구성해 이를 LLM에게 넘겨 주어 평가를 진행하는 방식입니다.
G-Eval은 Task instruction과 Evaluation criteria는 사람이 직접 작성하도록 하고, Evaluation methods는 Chain-of-thought을 이용하여 자동 생성하도록 하였습니다. Evaluation methods는 작업이 복잡하고 평가 기준이 다양한데요. 사람이 직접 설계하기에는 시간이 많이 소요되기 때문에 CoT를 이용하여 빠르게 작업을 하였습니다. 그 후에 실제로 모델이 생성한 text, 즉 Input contents를 넣어서 LLM이 최종 평가를 하는 방식이지요. 이러한 혁신적인 접근 방식은 G-EVAL을 현존하는 평가 방식 중에서 사람과 가장 잘 일치하는 평가 도구로 만들어주었습니다.
방법론: G-EVAL의 주요 구성 요소
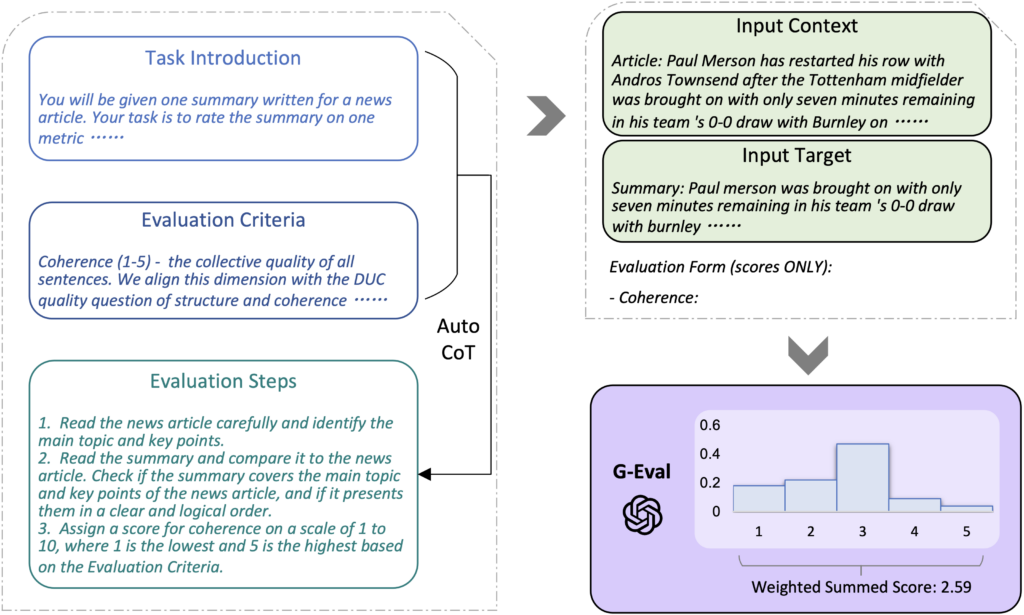
G-Eval의 전반적인 프레임워크.
G-EVAL 프레임워크는 세 가지 핵심 요소로 구성되는데요:
- 프롬프트 정의: 각 평가 작업은 일관성이나 관련성과 같은 기준을 명시하는 명확한 프롬프트와 함께 시작됩니다. Task instruction, Evaluation criteria를 직접 적성합니다.
- 연쇄 사고(CoT)를 통해 Evaluation steps 만들기: 위에서 생성한 Task instruction, Evaluation criteria을 가지고 CoT를 진행하여 Evaluation steps를 만듭니다.
- 확률 기반 점수 산정 함수: 기존 방식과 달리 G-EVAL은 각 평가 항목의 확률 가중치를 적용해 더 미세한 차이를 반영한 점수를 매깁니다. 이 방식은 인간 평가와 상관관계를 높이고, 생성된 텍스트간의 미묘한 차이를 잘 반영할 수 있습니다.
벤치마크 테스트: 여러 측면에서의 성과
G-EVAL은 SummEval, Topical-Chat, QAGS 세 가지 벤치마크에서 철저히 테스트되었습니다. 함께 살펴볼까요?
- 요약: SummEval 테스트에서 G-EVAL은 일관성, 유창성, 관련성 측면에서 인간 평가와 높은 상관성을 보여주며 기존 지표를 큰 차이로 뛰어넘었습니다.
- 대화 생성: 대화의 일관성과 흥미 요소를 평가하는 Topical-Chat 벤치마크에서도 G-EVAL은 인간의 평가와 가장 유사한 결과를 도출하는 데 성공했습니다.
- 환각 감지: 요약의 일관성을 평가하는 QAGS 벤치마크에서 BERTScore나 ROUGE와 같은 모델을 뛰어넘는 성능을 보여주었으며, 특히 복잡한 추상적 요약에서 탁월한 결과를 나타냈습니다.
이러한 결과는 G-EVAL이 다양한 작업에서 인간 평가와 일치하는 능력이 뛰어나며, 단일 점수 산출이나 다차원적 적응력이 부족한 기존 모델들과 달리 훨씬 신뢰할 수 있는 평가 도구임을 입증합니다.
기존 평가 도구와의 비교: G-EVAL의 차별화된 요소
G-EVAL의 새로운 CoT 방법론은 이전 모델들과는 상당한 차이를 보입니다. GPTScore나 BARTScore와 같은 기존 모델은 고정된 평가 방식을 따르지만, G-EVAL은 세부적인 평가 구조를 통해 더 깊이 있는 분석을 제공합니다. G-EVAL의 확률 기반 점수 산정은 UniEval과 같은 이산적 점수 모델을 넘어 더 정밀한 평가를 가능하게 합니다. 프롬프트 채우기 방식을 통한 종합적인 접근 방식 덕분에 G-EVAL은 단순한 점수 부여가 아니라 인간과 같은 기준으로 평가할 수 있습니다.
주요 결과 및 연구진의 결론
- 더 높은 인간 일치도: G-EVAL의 주요 성과는 인간 평가와의 높은 상관성으로, 특히 주관적 작업에서 훌륭한 도구로 평가됩니다.
- LLM 기반 텍스트에 대한 편향 가능성: 연구에서는 LLM 평가자가 사람의 텍스트보다 기계가 생성한 텍스트를 선호할 수 있는 잠재적 편향을 지적하는데요. 이는 향후 평가 프레임워크가 기계 생성 텍스트보다 인간 텍스트를 선호하지 않도록 주의해야 하는 중요한 문제입니다.
- CoT 논리의 효과: CoT를 포함한 평가가 특히 복잡한 작업에서 품질을 크게 높인다는 점을 연구진은 강조하며, 향후 AI 평가에 CoT가 널리 활용될 가능성을 언급합니다.
G-EVAL과 함께하는 NLG 평가의 미래
G-EVAL은 신뢰성, 확장성, 그리고 인간 일치도를 갖춘 NLG 평가의 새로운 기준을 제시합니다. 확률 가중치를 적용한 정교한 평가와 GPT-4의 고급 언어 이해를 활용해 G-EVAL은 NLG 평가에서 새로운 표준을 세웁니다. 다만, AI 평가자들이 NLG 개발에 핵심 역할을 하게 됨에 따라 기계 생성 텍스트에 대한 잠재적 편향을 신중히 관리할 필요가 있습니다.


