
1편 <RAG를 뛰어넘는 Graph RAG> 읽고 오기
오늘도 어마어마한 규모의 도서관에 들어서며 레터를 시작하고자 합니다. 책이 끝없이 늘어서 있는 이곳에서 또 한 번 "기술 산업의 주요 트렌드는 무엇인가요?"라고 묻습니다. 지난 번 테크레터에서, 우리는 Graph RAG를 질문과 관련된 책과 자료를 빠르게 찾아 요약해 주는 '스마트 사서'로 비유했는데요.
오늘 살펴 볼 ToG(Think-on-Graph)는 도서관의 '학자'와 같습니다. ToG는 단순히 자료를 찾는 데 그치지 않습니다. 자료 간의 관계를 분석하며, 정보의 근거와 출처를 명확히 제시합니다. 더 나아가, 잘못된 정보가 있다면 이를 추적해 수정할 수 있는 도구까지 제공하는데요. 이러한 과정을 통해 ToG는 단순한 정보 제공을 넘어 심층적인 추론과 책임감 있는 답변을 제공합니다.
ToG, 어떻게 LLM의 한계를 극복할까?
LLM은 여전히 주요 한계가 있습니다:
환각(Hallucination): 아직 잘못된 정보를 생성하거나 불완전한 데이터로 인해 논리적으로 맞지 않는 답을 내놓는 경우가 많습니다. 이는 책임감 있는 추론(responsible reasoning)과는 거리가 멀겠지요?
추론의 깊이 부족: 복잡한 논리를 따라가는 심층적인 추론 작업에 다소 취약합니다. 단계가 많은 지식이나, 명시되지 않은 연관성을 파악해야 하는 경우에 혼란스러워 합니다.
이러한 한계를 극복하기 위해 연구진은 외부의 지식 그래프(Knowledge Graph, KG)를 활용하는 접근법을 제안합니다. 지식 그래프는 구조화된 데이터를 기반으로 명확성과 투명성을 제공합니다. Graph RAG를 포함한, 기존 방식인 LLM ⊕ KG는 LLM이 지식 그래프를 단순 검색 도구로 사용하는 "느슨한 결합" 방식을 채택하고 있었는데요. 이는 지식 그래프의 완성도에 과도하게 의존하게 되는 한계를 가지고 있었습니다. 이를 보완하기 위해, 연구진은 LLM ⊗ KG라는 긴밀한 결합(tight coupling) 패러다임을 제시합니다. 어떤 차이가 있을까요?
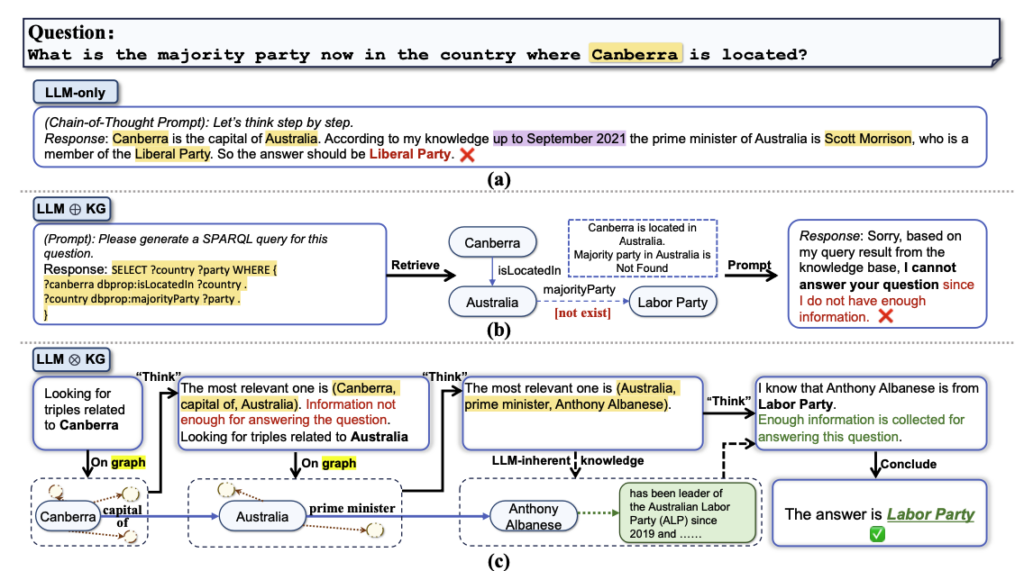
LLM 추론 방식 3가지에 대한 비교
- LLM-only는 독립적으로 작동하며 외부 데이터 의존도가 낮다.
- LLM ⊕ KG는 LLM이 KG 검색을 보조하지만, KG 품질에 따라 성과가 제한된다.
- LLM ⊗ KG (ToG 방식)는 LLM과 KG가 상호 협력하여 심층 추론과 오류 수정이 가능하다.
- 아래 그림을 통해 LLM ⊗ KG에 해당하는 ToG의 작동 방식을 가볍게 살펴보겠습니다.
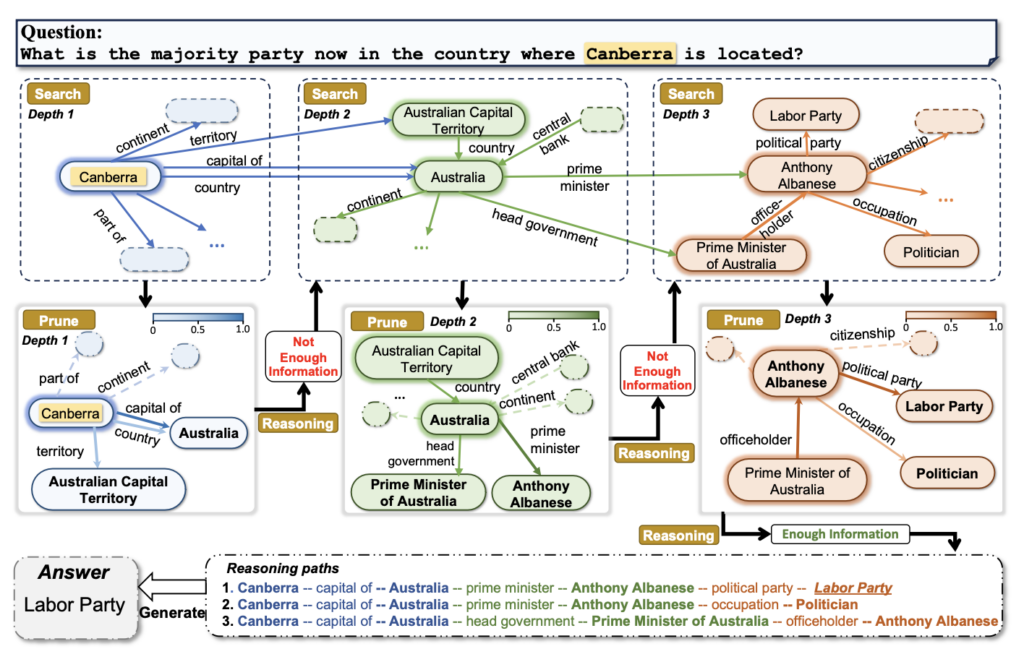
ToG 작동 방식
복잡해 보이나요? 사실 간단합니다.
- ToG는 질문을 받으면 먼저 질문의 핵심 키워드를 식별합니다. 예를 들어, "캔버라가 있는 나라의 여당은 어디인가요?"라는 질문에서는 "캔버라," "나라," "여당"이 핵심 키워드로 식별됩니다.
- 이후 ToG는 지식 그래프에서 이 키워드와 관련된 데이터를 단계적으로 탐색합니다. 첫 번째로 "캔버라는 호주의 수도다"라는 정보를 찾고, 이를 기반으로 "호주의 총리는 앤서니 알바니즈다"라는 다음 단계의 데이터를 탐색합니다.
- 마지막으로 "앤서니 알바니즈는 노동당 소속이다"라는 정보를 찾아 최종적으로 "노동당"이라는 답을 도출합니다. ToG는 이렇게 데이터를 단계적으로 연결하고 추론하며, 추론 경로를 명확히 보여줄 수 있습니다.
Think-on-Graph(ToG), 무엇이 새로울까?
ToG는 LLM과 지식 그래프의 "긴밀한 결합"을 실현한 새로운 패러다임(LMM ⊗ KG)의 대표적인 구현체라고 볼 수 있는데요. 세 가지 주요 단계를 통해 작동합니다:
초기화(Initialization):
질문에 대한 주제 엔티티(topic entity)를 식별하고, 초기 탐색 경로를 설정합니다.탐색(Exploration):
빔 서치를 통해 지식 그래프에서 다양한 관계를 탐색하며, 질문에 적합한 관련 정보를 동적으로 추출합니다. 빔 서치는 여러 경로를 동시에 고려한 뒤, 가장 가능성이 높은 상위 N개의 경로만 유지하며 탐색을 반복해 최적의 결과를 도출하는 효율적인 방식인데요. 이 과정에서 가지치기(Pruning)를 사용해 최적의 탐색 경로를 유지합니다.추론(Reasoning):
탐색한 정보를 기반으로 질문에 답할 수 있는지 평가하며, 충분한 추론 경로가 확보될 때까지 탐색과 추론 과정을 반복해 최종 답변을 생성합니다. 최대 깊이에 도달해도 해결되지 않을 경우 LLM 자체의 지식을 사용하여 답변을 생성하는데요. 현재까지 확보된 추론 경로를 평가한 후, 충분하다고 판단되면 이를 기반으로 최종 답변을 생성합니다. 만약 충분하지 않다고 평가되면 탐색과 추론 단계를 반복합니다.
ToG, 뭐가 좋을까?
- 깊은 추론(Deep Reasoning):
지식 그래프를 활용해 다양한 단계에서 정보를 연결하고 분석하여, LLM이 복잡한 지식 기반 작업에서도 더 깊이 있는 추론을 할 수 있도록 지원합니다. 책임감 있는 추론(Responsible Reasoning):
답변을 만드는 과정을 명확히 보여주고, 잘못된 경우 이를 수정할 수 있습니다. 추론 경로를 추적하고 필요한 정보를 추가로 탐색하며, 더 신뢰할 수 있는 결과를 제공하지요. AI의 신뢰성과 활용도를 강화시키는 장점입니다.유연성과 효율성(Flexibility and Efficiency):
다양한 환경에서 유연하고 효율적으로 활용할 수 있는 프레임워크입니다. 플러그 앤 플레이 방식을 통해 다양한 LLM과 지식 그래프(KG)에 손쉽게 통합할 수 있으며, 지식 그래프 기반의 지속적인 데이터 업데이트를 통해 LLM의 지식 갱신에 드는 비용과 시간을 절감합니다. 또한, ToG는 LLAMA2-70B와 같은 소형 LLM도 GPT-4와 같은 대형 LLM과 유사한 성능을 발휘할 수 있도록 강화하여, 비용 효율성을 극대화합니다.
지식을 추적하고 오류를 수정하는 ToG
연구진은 ToG가 제공하는 지식 추적 능력(knowledge traceability)과 오류 수정 능력(knowledge correctability)이 기존 접근 방식보다 훨씬 신뢰할 수 있음을 강조합니다. AI의 실용성과 책임감을 강화하는 데 중요한 요소인데요. 실제로 어떻게 작동하는지 함께 볼까요?
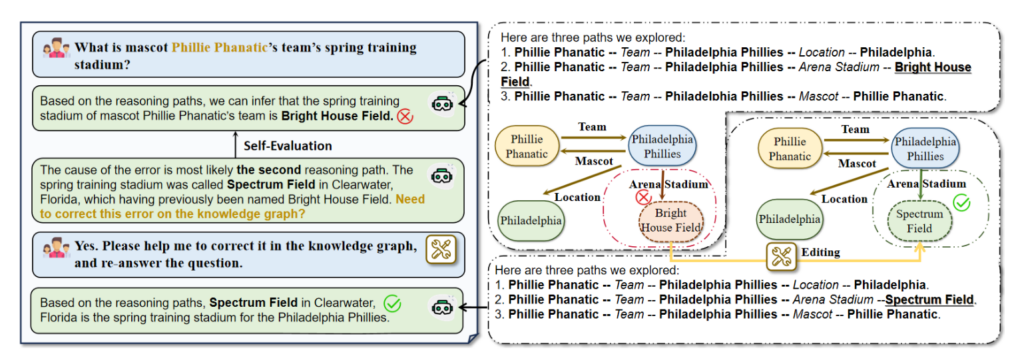
ToG의 지식 추적과 오류 수정 능력
입력 질문으로 'What is mascot Phillie Phanatic’s team’s spring training stadium?'을 받았을 때, ToG는 첫 번째 단계에서 잘못된 답변인 'Bright House Field'를 출력합니다. 이후 ToG는 모든 추론 경로를 추적하며, 오류 원인이 두 번째 추론 경로 (Phillie Phanatic → Philadelphia Phillies → Bright House Field)에서 비롯되었을 가능성을 분석합니다. 이 경로에서 'Bright House Field'가 'Specturm Field'라는 이전 명칭으로 기록된 오래된 삼중항 (Philadelphia Phillies, Arena Stadium, Bright House Field)이 오류의 원인임을 확인합니다.
이 단서를 바탕으로 사용자는 LLM에게 이 오류를 수정하도록 요청할 수 있으며, 올바른 정보를 사용하여 동일한 질문에 답할 수 있습니다. ToG가 LLM을 활용하여 지식 그래프의 품질까지 개선하는, '지식 융합(Knowledge Infusion)'의 역할을 하지요.
ToG(Think-on-Graph)는 LLM과 지식 그래프의 결합을 통해 AI의 추론 능력을 새로운 차원으로 끌어올렸습니다. 단순히 정보만 제공하지 않고, 맥락을 이해하고 논리적으로 답을 생성하며, 책임감을 가지고 결과를 제시하지요.
다음 글에서는 LLM에 Knowledge Graph을 적용한 실제 어플리케이션을 더 깊이 탐구할 예정입니다. 기대해주세요! 🚀


