
2022년 7월, Stable Diffusion 등장 이후 생성 모델은 세계적인 화두가 되었습니다. 특히 비전 분야에서는 Diffusion 계열의 이미지 생성 모델이 주목 받았습니다. 그로부터 2년이 지난 현재, 생성 모델은 이미지를 넘어 영상과 3D 객체까지 생성하고 있습니다. Microsoft의 수석 연구원이 CVPR 2024 튜토리얼에서 발표한 내용을 기반으로 생성형 기반 모델(Generative Foundation Models)이 어떻게 발전하고 있는지 3가지 측면에서 살펴보겠습니다.
1. 양질의 데이터
AI 모델을 학습시키려면 고품질 데이터는 필수입니다. 하지만 데이터 수집과 레이블링 작업이 만만치 않아 그동안 양질의 데이터를 마련하는 데 막대한 비용이 들었습니다. 물론, 비용을 들이더라도 쉬운 일은 아닙니다.

출처: Improving Image Generation with Better Captions (Betker et al., 2023)
위의 3개의 이미지는 어떻게 설명하면 좋을까요? 사람마다 설명하는 방식이 다를텐데요. 사람을 많이 모집하더라도 기준이나 설명하는 방식이 다르기 때문에 일관된 데이터를 제작하기란 쉬운 일이 아닙니다.
AI가 발전하면서 대체한 작업 중 하나는 바로 이 어노테이션(Annotation) 작업입니다. Text-to-Image 생성 모델은 텍스트로 된 설명, 그리고 관련된 이미지가 짝을 이루고 있어야 합니다. AI가 어노테이션을 하기 위해서는 이미지에 대해 ‘텍스트’로 이해해야 하는데요. 비용을 절감하면서 대량의 텍스트를 확보하기 위해 연구진이 활용한 방법이 있습니다. 바로 웹의 이미지를 수집하면서 그와 관련된 설명인 대체 텍스트(Alt Text)를 같이 수집하는 작업입니다. 하지만 문제가 있습니다. 위의 예시에서 보시다시피 대체 텍스트에 URL, 정체 모를 숫자 등이 포함되어 있는 경우가 있기 때문인데요. 이런 데이터는 오히려 모델에게 악영향을 끼칠 수 있어 차라리 제거하는 편이 좋습니다.
이후에 지속적으로 더 좋은 데이터를 구축하고자 하는 노력이 이어졌습니다. 생성 모델이 실제 서비스에 사용되기 위해서는 사용자의 다양한 요구에 적합한 결과물을 내야 했기 때문입니다. 첫 번째 이미지로 예를 들자면, 과거에는 단순히 ‘나무 마룻 바닥 위 하얀 현대식 욕조’라고 짧게 설명하는 데 불과했다면 이제는 배경, 분위기, 주변 사물들까지 상세하게 설명해야 합니다.
OpenAI의 이미지 생성 모델 DALL·E 3에서는 더 상세한 이미지 캡션(caption)을 생성하면서 학습 데이터 퀄리티를 높였습니다. 이때 짧은 설명과 긴 설명을 같이 생성했는데요. 사용자가 장황하게 설명하지 않더라도 그 맥락에 맞게 대략적인 이미지 생성이 가능하죠. 이후 더욱 상세한 요구를 하면 그에 맞는 이미지 또한 생성 가능합니다.
2. 생성 모델 구조: Diffusion과 Transformer의 결합
학습 데이터를 구축했다면, 이제는 모델이 필요합니다. 모델이 데이터의 어떤 부분을 어떻게 학습하느냐에 따라 성능은 크게 달라질 수 있는데요. 생성 모델에 흔히 활용된 모델은 Diffusion 모델입니다. 생성형 AI 열풍을 주도한 Stable Diffusion 이름에도 반영되어 있고, 또 올해 수능 국어 과목에 ‘확산 모델’로 문제에 등장했지요.
최근 생성 모델에서는 이를 기반으로 Transformer 모델과 결합한 Diffusion Transformer(DiT) 모델 자주 활용되고 있습니다. DiT는 Diffusion 모델과 Transformer 모델의 장점을 결합한 학습 방법인데요. Diffusion은 고퀄리티의 이미지를 생성하고, Transformer는 높은 확장성을 가집니다. 지난 2월, 영상 생성 모델로 크게 화제가 된 OpenAI의 Sora에 활용되면서 이후 많은 모델이 이를 기반으로 삼았지요.
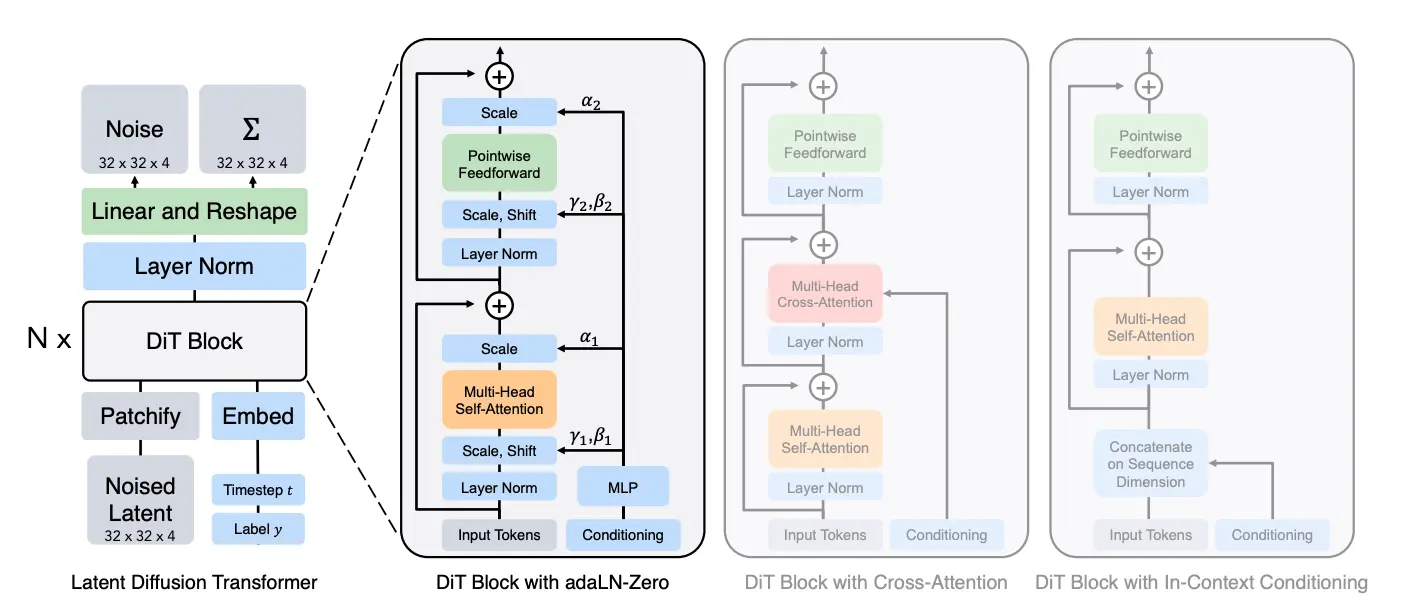
출처: Scalable Diffusion Models with Transformers (Peebles & Xie, 2022)
DiT에 활용되는 Transformer 모델은 ViT(Vision Transformer) 구조입니다. ViT는 이미지를 여러 조각으로 분할한 패치를 마치 하나의 시퀀스로 생각하고, 패치(Patch) 간의 연관성을 계산하며 이미지의 특성을 파악합니다. DiT의 특징 중 하나는 다양한 해상도의 이미지를 처리할 수 있다는 점입니다. 또한, 패치 크기를 달리하거나 모델 크기(파라미터)를 조절해도 안정된 성능을 보장합니다. 최신 기술을 모두 반영해 구성한 생성 모델 구조라고 봐도 무방하지요.
3. 훈련 방식: Rectified Flow
Rectified Flow는 생성 모델에서 최근 주목받고 있는 방법론입니다. Rectified Flow는 Diffusion 모델이 사용하는 노이즈 추가 및 제거 과정 대신, 데이터 분포 간의 매끄러운 경로를 직접 학습합니다. 다르게 말하면 데이터를 초기 상태에서 목표 상태로 변환하는 과정을 수학적으로 모델링하여 학습한다는 의미입니다.
여기서 데이터 분포 간 경로란, 초기 분포에서 목표 분포로 점진적으로 이동하는 변환 과정을 말하는데요. 이는 데이터를 연속적인 흐름으로 변환하는 것을 목표로 하며, 분포 간 경로는 미분 방정식(ODE)이나 확률적 미분 방정식(SDE)을 통해 나타낼 수 있습니다.
또한 매끄러운 경로는 데이터 변환 과정이 불연속적이거나 급격하지 않고, 작은 단계의 점진적인 변화로 이루어진다는 의미입니다. 데이터를 단번에 다른 상태로 ‘점프’시키는 방식이 아니라, 변환 과정의 각 단계가 논리적이고 자연스럽게 연결되어 목표 분포에 가까워지도록 설계하는 것이지요. 예를 들어, 흐릿한 이미지를 고해상도로 복원하는 경우, 흐릿한 경계선을 선명하게 하고, 윤곽을 정교하게 추가하며, 마지막으로 텍스처를 채우는 과정으로 이뤄지는 식입니다.
이 과정을 Diffusion은 단계적으로 처리한다면 Flow Matching은 매끄러운 전체 경로를 하나의 연속적인 함수로 표현하고 모델이 이를 학습합니다. 하지만 최근에 이 방식을 DiT와 통합하면서 모델의 성능을 극대화하는 방향으로 나아가고 있습니다.
마치며
생성 모델은 최근에 많이 발전했으나 여전히 여지가 많이 남아 있습니다. 영상에서 시간과 동작을 일관되게 유지하거나, 추론 시간을 줄이는 등, 여러 기법들이 추가되어야 하지요. 또한, 창작물의 결과가 ‘AI스럽다’는 인식에서 벗어나지 못하고 있기도 합니다. 이미지 내의 텍스트를 제대로 생성하지 못한다는 취약점도 존재하는데요.
이를 해결하는 건 시간문제로 보입니다. 우리는 불과 2년 사이에 가파른 변화를 겪었습니다. 2년 뒤, 지금 진행되고 있는 생성 모델과 관련된 수많은 연구들이 우리를 어디에 데려다줄지 무척 기대가 됩니다.


