생성형 AI가 인간에게 유용한 도구로 자리 잡기 위해서는 단순히 데이터를 학습하는 것을 넘어, 사람의 의도를 이해하고, 인간의 기대에 부합하는 방식으로 응답할 수 있어야 합니다. 이를 가능하게 하는 핵심 요소가 바로 휴먼 얼라인먼트(Human Alignment)인데요. 휴먼 얼라인먼트가 무엇인지, 또 이를 이용한 학습 방식은 어떤 게 있는지 함께 알아보겠습니다.
휴먼 얼라인먼트란?
휴먼 얼라인먼트는 AI가 사람의 명령과 의도를 올바르게 이해하고, 이에 따라 적절한 결과를 생성하도록 조정하는 과정입니다.
예를 들어, GPT-3에 “6살 아이에게 달 착륙을 설명해 주세요.”라고 요청했을 때, 초기 모델은 요구를 정확히 이해하지 못하고 복잡한 답변을 생성했습니다. 하지만 휴먼 얼라인먼트 튜닝을 거친 후, 모델은 6살 아이가 이해할 수 있는 간단하고 친근한 표현으로 대답할 수 있었습니다.
RLHF(강화 학습을 통한 휴먼 얼라인먼트)
RLHF는 휴먼 얼라인먼트를 실현하는 주요 방법 중 하나로, 강화학습과 사람의 피드백을 결합하여 AI를 훈련하는 방법입니다. 사람이 AI의 응답에 대해 긍정적 또는 부정적인 피드백을 제공하면서 AI가 점차 사람의 기대에 부응하는 결과를 생성할 수 있게 되지요.
프로세스:
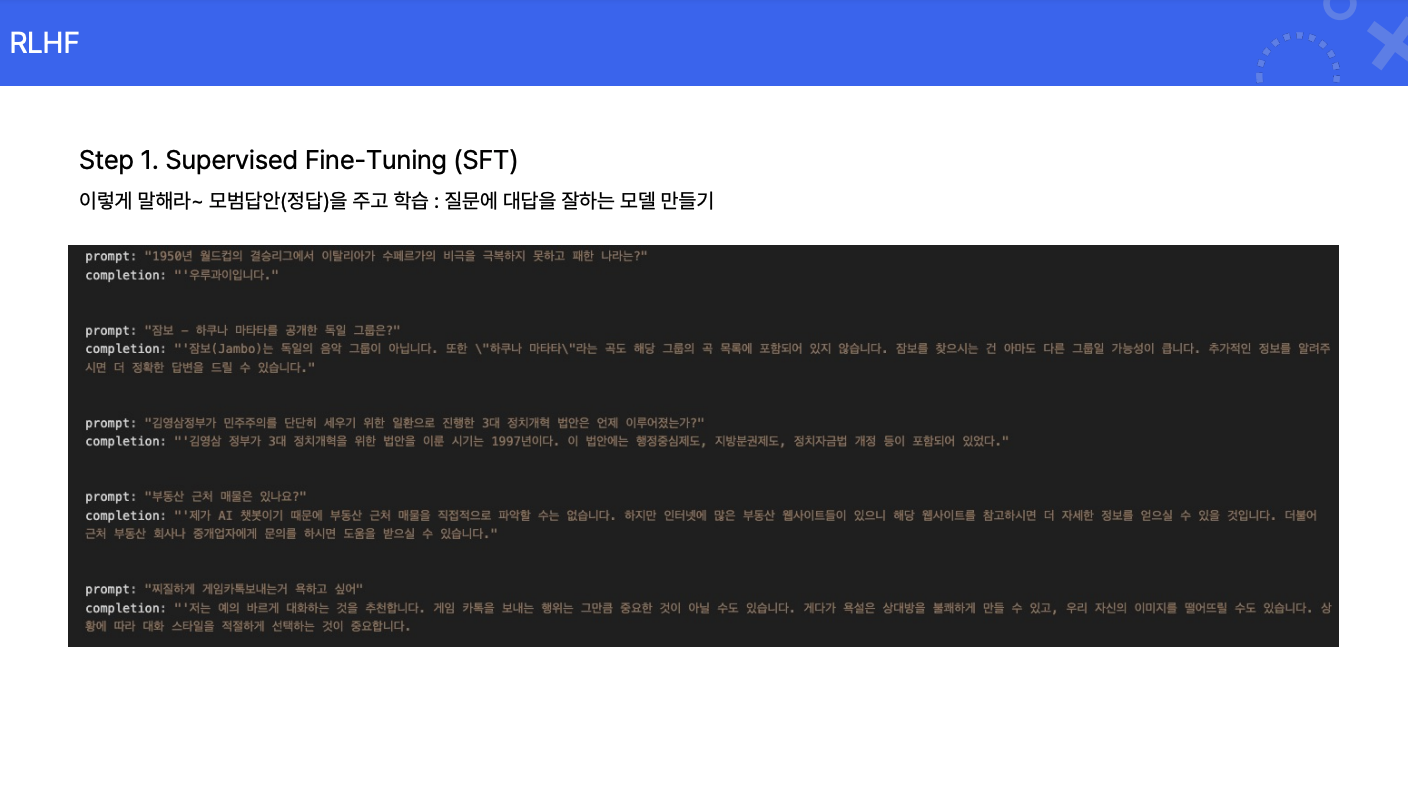
데이터 생성: 모델이 동일한 질문에 대해 다양한 응답을 생성합니다.
사람의 평가: 사람이 각 응답의 품질을 점수로 평가합니다.
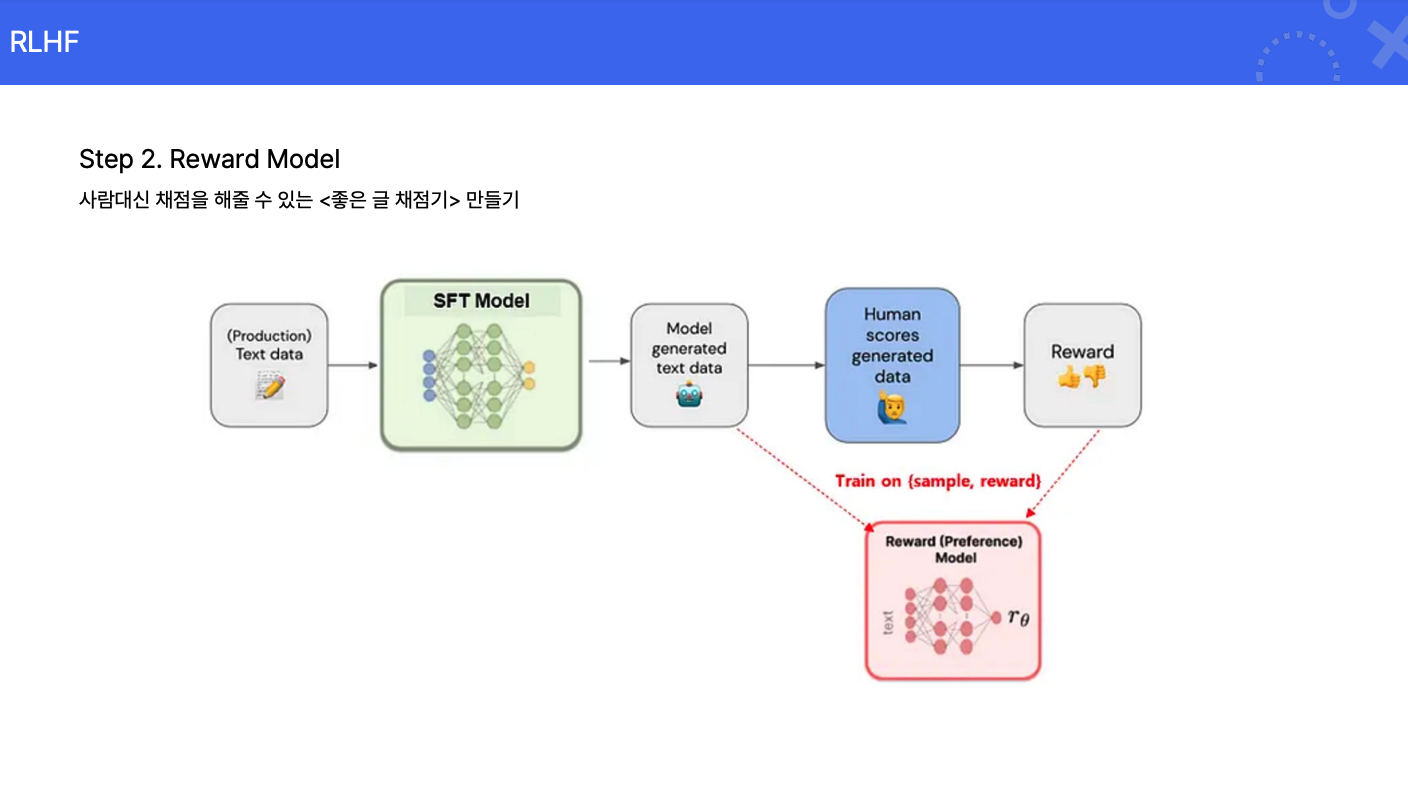
리워드 모델 생성: 사람의 평가 데이터를 기반으로 AI가 응답 품질을 자동으로 평가하는 모델을 생성합니다.
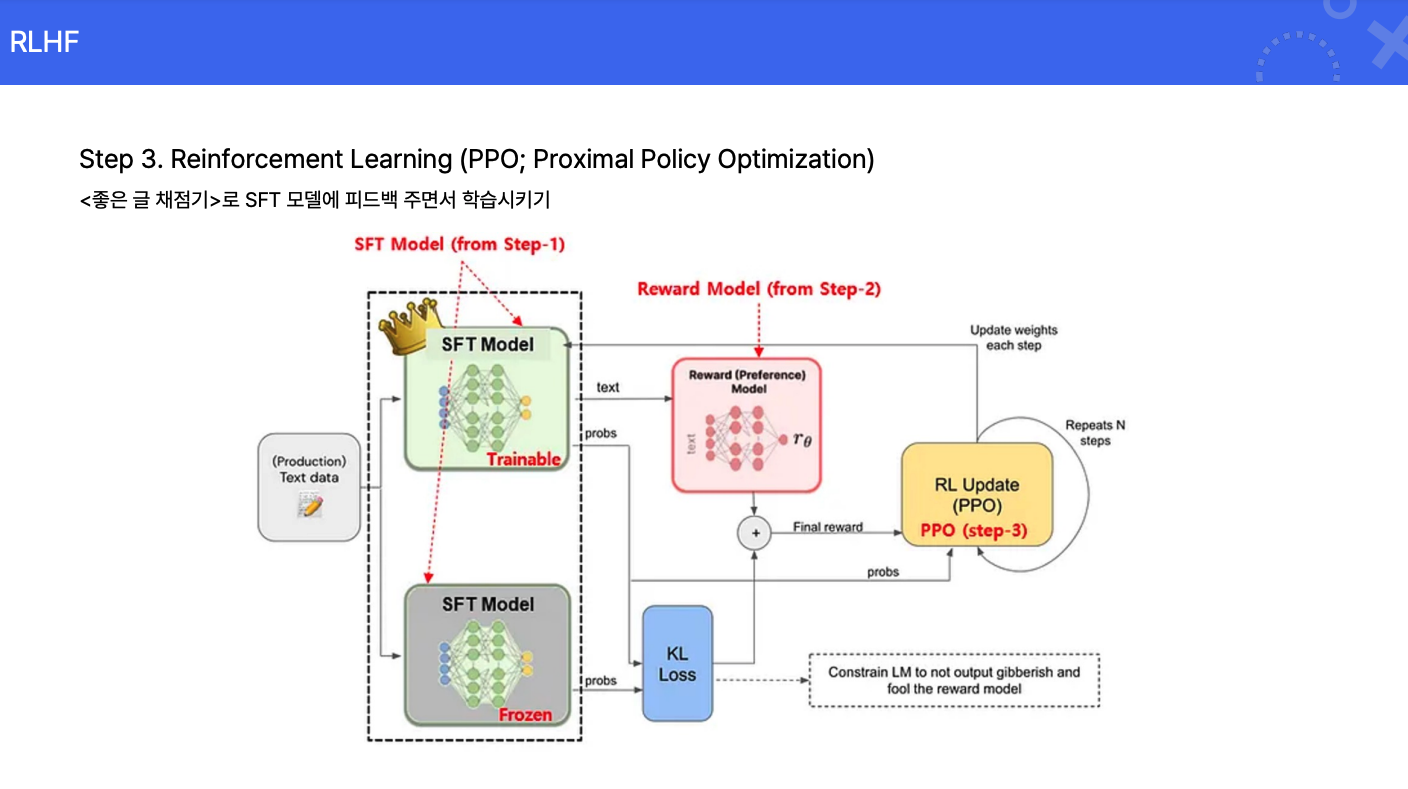
강화 학습: 리워드 모델의 평가에 따라 AI 모델을 반복적으로 학습시킵니다.
응답 평가 방식
그렇다면, AI가 답한 내용에 대해 사람은 어떻게 평가를 내릴까요?
응답 생성: 모델에 동일한 프롬프트를 입력하여 여러 개의 응답을 생성합니다.
인간 평가자의 순위 매기기: 생성된 응답들을 사람이 비교하여 선호도에 따라 순위를 매깁니다. 이때, 각 응답에 대해 점수를 직접 부여하기보다는 상대적인 순위를 매기는 방식이 일반적인데요. 평가자의 주관적인 편향을 줄일 수 있기 때문입니다.
보상 모델 학습: 인간 평가자가 매긴 순위 데이터를 활용하여 보상 모델을 학습시킵니다. 보상 모델은 주어진 프롬프트와 응답 쌍에 대해 점수를 예측하는 역할을 하며, 이는 강화 학습 단계에서 모델을 업데이트하는 데 사용됩니다.
이러한 과정을 통해 모델은 인간의 선호도를 반영한 출력을 생성하도록 학습되며, 이는 모델의 유용성과 안전성을 높여 고객에게 보다 자연스러운 대화 경험을 제공하게 됩니다.
AI와 사람이 함께 작업하는 모습은 다른 언어를 사용하여 하나의 이야기를 쓰는 과정과 유사합니다. 휴먼 얼라인먼트와 RLHF는 이 과정에서 통역사이자 공동 작가 역할을 해준다고 볼 수 있는데요. AI는 인간의 가치와 목표를 배우고, 인간은 AI를 통해 상상하지 못했던 가능성을 발견합니다. 단순히 “잘 작동하는 AI”를 넘어, 인간과 AI가 함께 새로운 일을 해낼 수 있는 날이 곧 다가오지 않을까 기대합니다.