
대형 언어 모델(LLM)이 빠르게 발전함에 따라, 방대한 텍스트에서 관련 정보를 효율적으로 검색하는 것이 항상 큰 도전 과제로 남아 있습니다. 기존의 검색 방법은 작은 연속 텍스트 조각만 검색하는 경향이 있어 포괄적인 이해에 필요한 더 넓은 맥락을 놓치는 경우가 많습니다. Recursive Abstractive Processing for Tree-Organized Retrieval의 약자인 RAPTOR는 바로 이러한 문제를 해결하기 위해 고안된 새로운 재귀적 요약 기반 검색 방식입니다.
왜 Animate-X가 필요할까?
AI 기술을 활용해 사진 속 인물에 생동감을 불어넣는 초기 모델은 사람 얼굴이 일그러지거나 부자연스럽게 움직이는 수준이었습니다. 너무 말이 안되는 모습이라 오히려 밈처럼 사용되기도 했지요. (엄밀히 따지면 조금 다른 기술이지만요.) 하지만 기술이 빠르게 발전하면서 이제는 사람이 자연스럽게 춤추고 움직이는 영상을 만들어낼 수 있습니다.
이런 영상을 만들기 위해서는 참조 사진(Reference image)과 행동을 가이드할 타겟 포즈(Target pose)가 필요합니다. 지금까지는 참조 사진이 주로 인물에 초점을 맞추고 있었습니다. 즉, 인간의 체형과 얼굴에 초점을 맞춰 그 특성을 추출했는데요. 이로 인해 확장성이 떨어졌습니다. 이번 연구는 다양한 인물 캐릭터, 의인화된 동물 캐릭터 등으로 일반화를 위한 시도라고 볼 수 있습니다. Animate-X는 어떤 것(X)이라도 애니메이션화를 시킨다는 의미입니다.

출처: GitHub Pages Animate-X
위 결과물을 살펴볼까요? 참조 사진을 토끼 이미지로 입력한 후, 사람이 등장하는 가이드 영상을 제공하면 일반적으로는 사람의 모습에 가깝게 영상이 생성됩니다. 반면, 이번에 발표된 모델(Ours)은 인간이 아닌 토끼가 짧은 팔다리로 인간과 비슷한 포즈를 취합니다.
왜 일반적으로 형상에 변형이 일어날까요? 기술적인 관점에서 살펴보겠습니다. 애니메이션을 2D 포즈 스켈레톤(뼈대 형태로 단순화한 움직임 표현)으로 변환하면 동작을 추상화하여 여러 대상에 적용할 수 있다는 장점이 있습니다. 하지만 이미지의 세밀한 디테일은 놓치게 되지요. 이를 보완하기 위해 자체 재구성(Self-driven Reconstruction) 전략을 활용하면 참조 이미지와 포즈 스켈레톤을 일치시키면서 동작을 표현할 수 있습니다. 다만, 사람과 토끼처럼 체형이 크게 다른 대상에 적용할 경우 위의 이미지에서 보이듯 부자연스러운 결과가 나타날 수 있습니다.
Animate-X의 원리
연구진은 위 문제를 극복하기 위해서 암묵적(Implicit) / 명시적(Explicit) 관점에서 포즈를 가이드 할 수 있는 Pose Indicator를 설계했습니다. 이는 기존 스켈레톤 방식에서 부족했던 세밀한 이미지를 반영하고 모양과 포즈 간에 복잡한 상호작용을 더 명확하게 표현할 수 있습니다. 각 개념을 더욱 구체적으로 살펴보겠습니다.
Implicit Pose Indicator(IPI)
: CLIP 모델을 사용해 이미지의 특징을 추출합니다. CLIP은 이미지와 텍스트 간의 관계를 학습하는 모델로, 단순히 ‘보이는’ 이미지의 특징을 넘어서, 이미지가 전달하려는 개념이나 의미를 더해 설명하는 역할을 합니다. 즉, CLIP은 이미지에 대한 텍스트 설명과 이미지 사이의 연결을 이해하도록 학습되어, 이미지에 담긴 추상적인 맥락까지 파악할 수 있습니다. 이러한 특성을 활용한 IPI(Implicit Pose Indicator)는 포즈 스켈레톤(Pose Skeleton)으로는 얻을 수 없는 이미지의 숨은 의미와 배경 정보를 추출하는 데 유용합니다.
Explicit Pose Indicator(EPI)
: 참조 이미지와 타깃 포즈가 일치하지 않는 상황, 예를 들어 팔이 짧은 토끼가 팔이 긴 사람의 동작을 따라야 하는 경우에 차이를 줄일 수 있도록 학습됩니다. EPI는 이런 불일치 상황을 시뮬레이션하면서 포즈의 세부적인 요소들을 조정하여, 캐릭터와 동작이 자연스럽게 일치하도록 돕습니다. 이로 인해 포즈 스켈레톤(Pose Skeleton)만으로는 해결하기 어려운 캐릭터 특유의 표현력과 동작의 일관성을 유지할 수 있게 되지요. EPI는 IPI와 함께 작동하여, 포즈의 구체적인 움직임과 더불어 장면의 추상적 맥락까지 보완함으로써 더 자연스럽고 현실감 있는 결과물을 생성할 수 있습니다.
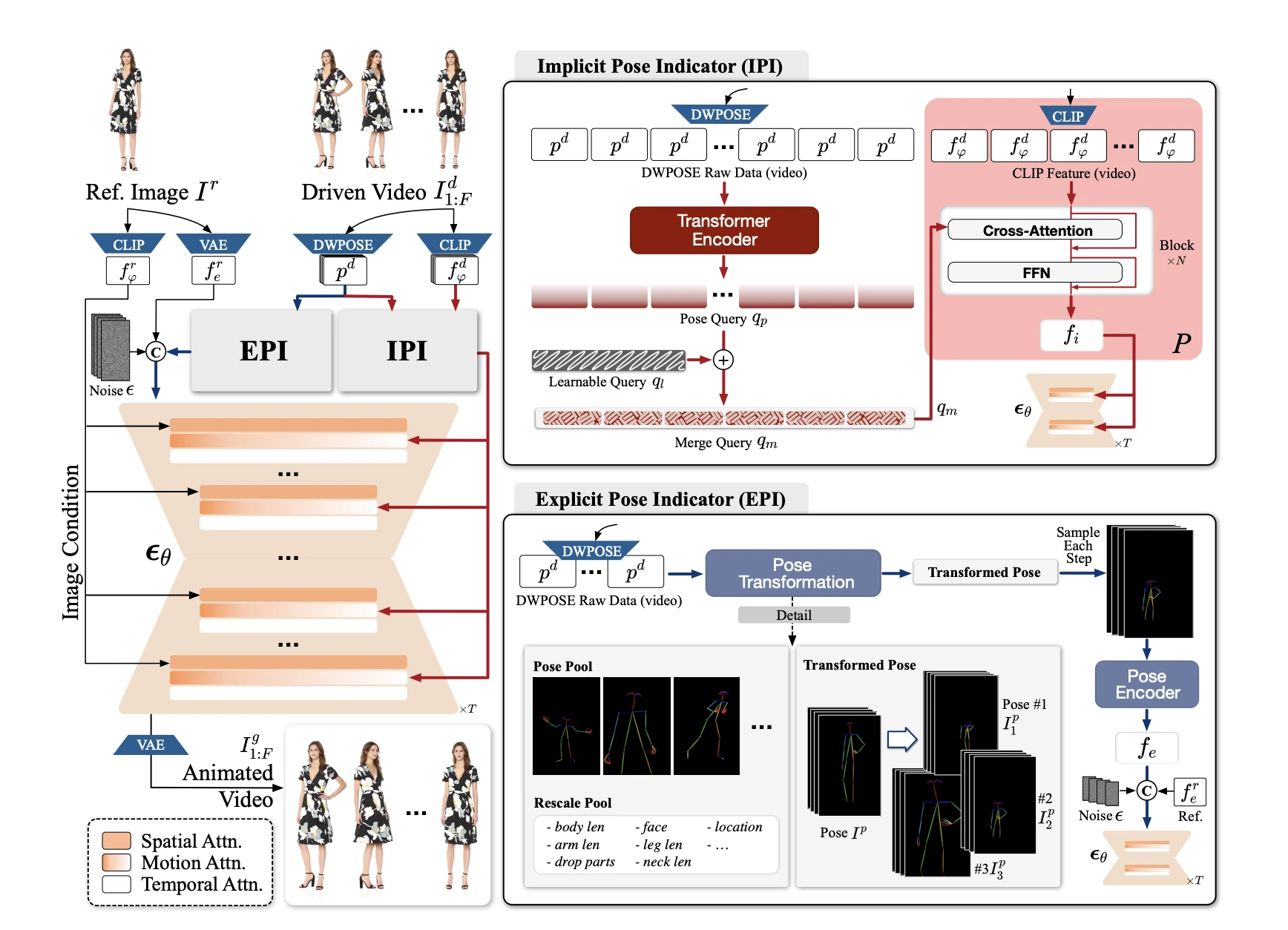
Animate-X의 아키텍처. 출처: Animate-X: Universal Character Image Animation with Enhanced Motion Representation (Tan et al., 2024)
위 이미지는 다소 복잡해 보이지만, 각 요소를 자세히 보면 구조를 파악할 수 있습니다. IPI와 EPI에서 추출한 정보를 Latent Diffusion 모델(주황색 부분)에 입력하여 최종 애니메이션을 생성합니다. Latent Diffusion 모델은 Stable Diffusion과 같은 대표적인 생성 모델을 기반으로, 캐릭터 애니메이션을 위해 확장된 구조입니다.
IPI는 CLIP을 이용해 이미지의 동작 패턴과 공간 정보를 추출하고, DWPose*에서 얻은 포즈 정보와 병합하여 더 깊이 있는 동작 표현을 제공합니다. Cross-Attention 기법을 통해 두 정보를 통합해 애니메이션에 필요한 모션 특성을 강화합니다. 반면, EPI는 입력된 Skeleton을 정밀하게 조정해 포즈 이미지로 변환하고, 이를 Latent Diffusion 모델의 입력으로 사용해 동작의 일관성을 높입니다.
*여기서 DWPose는 신체 포즈를 빠르고 정확하게 추출하도록 설계된 경량화된 모델로, 이러한 포즈 정보를 기반으로 캐릭터의 자연스러운 움직임을 지원합니다.
Animate-X는 IPI와 EPI의 협력을 통해 다양한 캐릭터의 포즈와 정체성을 유지하면서도 유연하게 애니메이션을 생성할 수 있습니다.

DWPose로 영상 속 손가락의 스켈레톤이 맞지 않은 부분까지 제대로 정렬한 결과 출처: Effective Whole-body Pose Estimation with Two-stages Distillation (Yang et al., 2024)
그 결과를 살펴보면 아래와 같습니다. 영상 속 대상 중 어느 것도 실제 인간이 아님에도 불구하고 자연스럽게 포즈를 취하고 있는 모습입니다. 특히 손이 없는 캐릭터, 다리가 없는 캐릭터라도 일반화된 포즈 특성이 참조 이미지의 특성에 맞게 잘 변형된 모습을 볼 수 있습니다.

출처: Animate-X: Universal Character Image Animation with Enhanced Motion Representation (Tan et al., 2024)
이에 더불어 연구진은 Animated Anthropomorphic Benchmark 즉, A^2 Bench를 공개했습니다. 인간의 포즈를 중심으로 평가됐던 기준을 의인화(Anthropomorphic)된 애니메이션까지 확장하여 평가하겠다는 의도가 담겨 있는데요. Animate-X는 기존 모델보다도 훨씬 높은 퀄리티를 보이며 SOTA를 달성했습니다.
IPI와 EPI의 역할
연구의 핵심 아이디어는 명시적인(Explict) 정보와 암묵적인(Implicit) 정보를 생성 모델에 통합한 점입니다. 즉, 이미지를 생성하는 데 인간이 알고 있는 개념과 모델이 알고 있는 개념을 반영했지요. 연구진은 EPI나 IPI만 존재할 때 어떤 결과가 나오는지 실험해봤습니다. 결과는 아래와 같습니다. w/o(without) IPI의 경우에는 동작 자체를 이해하고 움직이려는 모습이, w/o EPI의 경우에는 판다의 형태가 정상적으로 유지되는 모습이 보입니다. 다소 부자연스럽긴 하지만요.

출처: Animate-X: Universal Character Image Animation with Enhanced Motion Representation (Tan et al., 2024)
IPI는 외형을 보존하고, (식물에 인간 손이 존재하는 것처럼) 비정상적인 결과물 생성을 방지합니다. EPI는 참조 대상과 포즈의 결과물이 정확하게 정렬되도록 돕는 역할을 합니다. 판다의 귀를 고정시키듯 말이지요. 이 두 가지 정보가 조화롭게 결합한 결과물이 최종본입니다.
마치며
Animate-X는 복잡한 캐릭터 애니메이션 생성의 경계를 확장하며, 다양한 캐릭터 타입에서 정체성과 모션의 일관성을 유지할 수 있는 독창적인 접근을 제시합니다. IPI와 EPI를 조합한 새로운 모델 구조는 단순한 포즈 추정을 넘어선, 더욱 자연스럽고 유연한 동작을 표현하는데요. 애니메이션뿐 아니라 게임, 가상현실, 디지털 콘텐츠 제작 등에 새로운 기준을 제시하지 않을까 기대가 됩니다.


