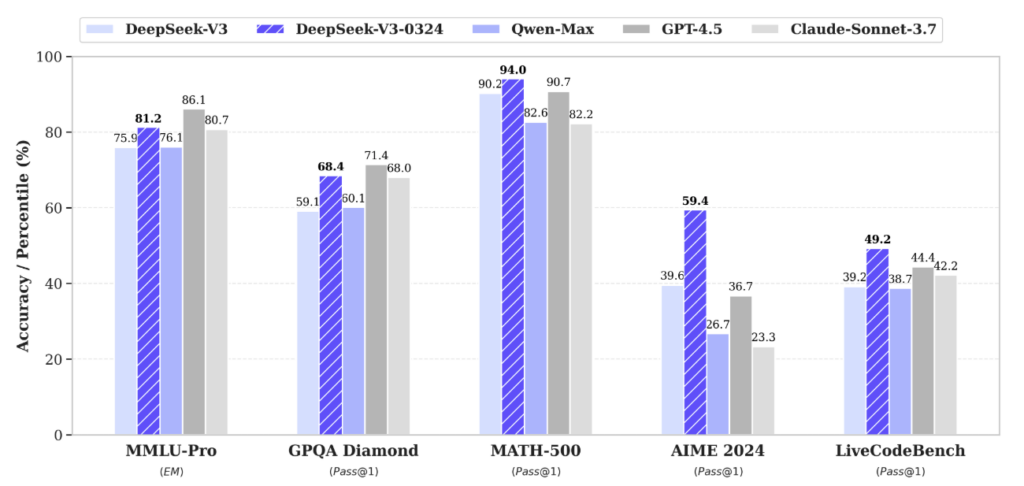
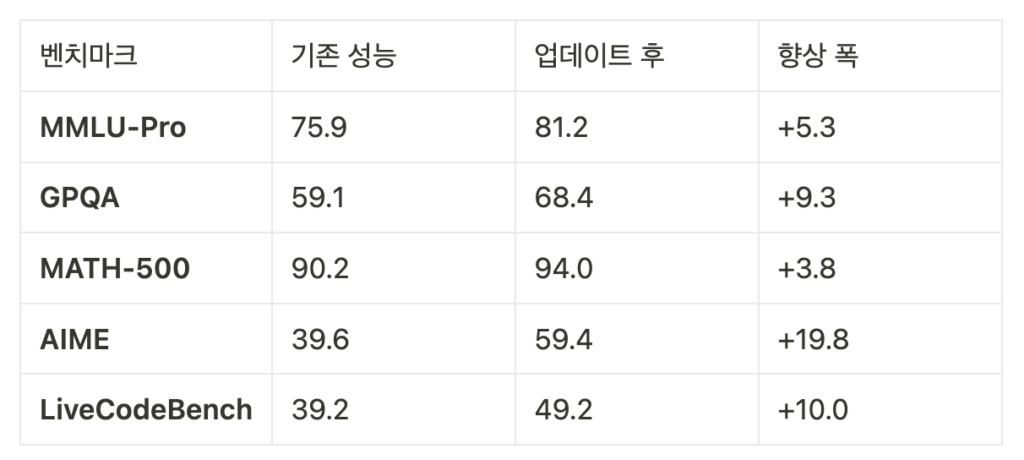
MMLU-Pro
전문가 수준의 지식과 개념을 바탕으로 한 고차 추론 능력 평가
- 전통적인 MMLU 벤치마크(57개 분야, 12,000개 문제)를 기반으로 한 고급 버전
- Pro 버전은 더 높은 난이도의 전문 문제를 포함해, 전문가 수준의 언어이해 능력을 평가
평가 영역
- 다양한 학문 분야: 의학, 법학, 역사, 수학, 철학, 컴퓨터과학 등
- 주로 4지선다형 문제
- 고난이도 지식 기반 추론을 요구
평가 목표
- 단순 암기 능력이 아니라, 심화된 개념 이해, 상황 판단, 추론 능력을 테스트
GPQA
대학원 수준의 과학 개념을 기반으로 한 복합적 추론 및 논리적 판단 능력 평가
- 이름 그대로 "Google-Proof"—즉, 단순 검색으로는 풀 수 없게 만든 벤치마크
평가 영역
- 물리학, 생물학, 화학, 천문학 등 과학 전공 문제
- 문제들이 복합적 추론, 개념 연결, 지식의 응용을 요구
평가 목표
- LLM이 고등 과학 지식을 이해하고 논리적으로 조합해 문제를 해결할 수 있는지 평가
MATH-500
GPT-4조차 어려워하는 고난도 수학 문제들로 구성. 진정한 수학 추론 역량의 시험대
- MATH benchmark(고급 수학 문제 모음)에서 특히 어려운 500문제만 추출한 서브셋
- 정교한 수학 추론 능력을 집중적으로 테스트
평가 영역
- 대수학, 정수론, 수열, 기하학, 조합 등
- 문제 구조는 수학 풀이 과정 기반의 주관식
목표
- 수학 문제에 대해 풀이 계획을 수립하고, 단계별로 논리 전개할 수 있는지 확인
- 수식 사용, 다단계 추론, 수학적 사고 능력 평가
AIME
고급 수학 문제 해결력 테스트. 특히 정확한 수학적 사고와 계산 기반 추론 능력 요구
- 미국 수학 경시대회 시리즈 중 하나
- AMC에서 고득점을 받은 학생들이 치르는 심화 수학 대회
- 16문제, 각 문제는 정답이 0~999의 정수
평가 영역
- 고등수학: 대수, 기하, 조합, 수열, 정수론 등
- 주로 논리적 사고, 정교한 수학적 추론 필요
평가 목표
- 단순 계산 능력이 아닌, 복잡한 수학 문제 해결 전략 수립과 실행 능력 평가
LiveCodeBench
문제 이해 → 알고리즘 설계 → 동작하는 코드 작성까지의 실전 프로그래밍 능력 평가
- LLM의 실제 프로그래밍 능력을 평가하는 벤치마크
- 단순한 코드 생성이 아니라, 테스트 케이스를 통과하는 동작 코드를 짤 수 있는지를 평가
평가 영역
- 알고리즘
- 문자열 처리
- 자료구조
- 수학 문제
- 실제 문제 해결을 위한 코드 작성
평가 목표
- 문법적 코드 생성이 아닌, 정확히 동작하고 문제를 푸는 실전 코드 능력 평가