
1편 <RAG를 뛰어넘는 Graph RAG> 읽고 오기
2편 <LLM 성능 높이기? Think on Graph!> 읽고 오기
전 세계적으로 의과대학은 왜 유독 과정이 길까요?
아마도 공부해야 할 양이 상당하기 때문일 텐데요. 의료는 복잡한 관계와 수많은 변수를 다루며, 그 안에서 정확하고 신뢰할 수 있는 결정(decision)을 내려야 합니다. 게다가 의료 정보는 방대할 뿐만 아니라 서로 다른 논문과 데이터베이스에 흩어져 있습니다. 필요한 정보를 찾고, 그 관계를 검증하며, 신뢰할 수 있는 결론을 도출하는 것은 결코 쉬운 일이 아닙니다.
이 문제를 해결하기 위해 하버드 대학을 포함한 연구진은 KGARevion 에이전트를 개발했습니다. KGARevion은 정보를 단순히 검색하는 것을 넘어, 관계를 명확히 검증하고 오류를 수정하며 신뢰할 수 있는 답변을 제공하는데요. 어떻게 문제를 해결하는지 살펴볼까요?
KGARevion 연구: 왜 필요했을까?
RAG의 한계
- 기존 RAG(Retrieval-Augmented Generation)는 문서를 찾아 답변을 생성하지만, 복잡한 관계를 명확히 설명하는 데 한계가 있습니다. 연관성으로 묶인 정보가 아닌, 독립된 정보 조각(chunk)을 검색하는 형식이기 때문인데요. 특히 의료처럼 복잡한 관계와 명확한 검증이 필요한 분야에서는 오류가 발생할 가능성이 큽니다.
LLM의 한계
- 지난 레터에서 본 것처럼, LLM은 환각이나 잘못된, 또는 깊이가 부족한 추론을 할 수 있습니다. 복잡한 논리를 따라가기에는 다소 어려움이 있습니다.
KG의 한계
- 지식 그래프(KG)는 명확한 관계 정보를 제공하지만, 자체적으로 질문에 답변을 생성할 수 없습니다. 찾는 정보 간의 관계를 알려줄 뿐이지요.
이 세 가지 문제에 대한 해결사를 자처한 KGARevion은 어떻게 작동할까요?
KGARevion이 일하는 방식
1. Generate (생성)
- (A) HSPA8
- (B) CRYAB
- (C) Heat Shock Protein 70
- 예시 Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
- (A) 예
- (B) 아니오
- 예시 Triplet: (Retinitis Pigmentosa 59, 관련 있음, HSPA8)
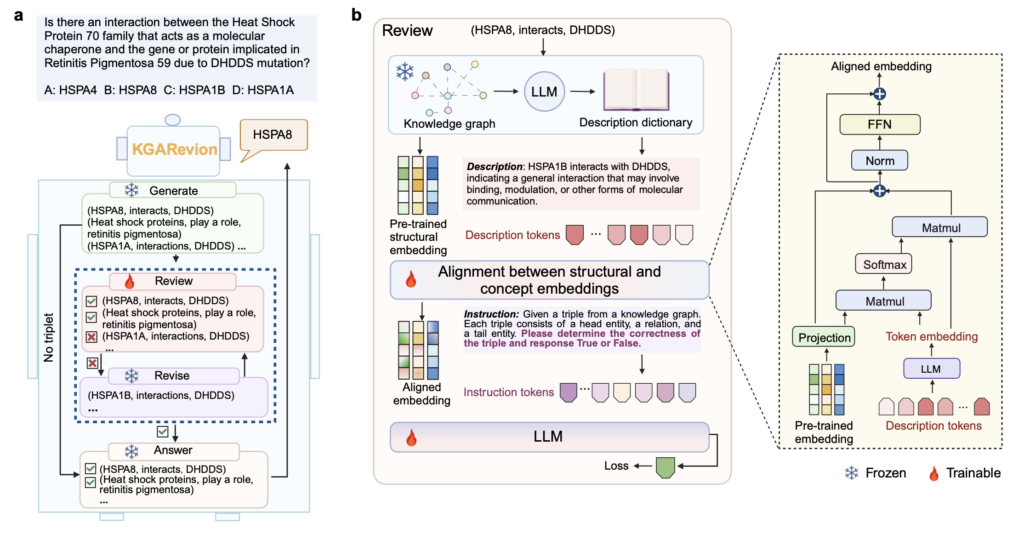
a) KGARevion 개요와 b) Review 단계에서의 파인튜닝 구조: KG는 구조적 임베딩을, LLM은 개념 임베딩을 제공.
2. Review (검증)

KG는 기존 지식 네트워크를 활용해 관계의 명확성을 확인합니다. KG에 해당 관계가 존재하는지, 이 관계는 신뢰할 수 있는지 등을 확인하지요.
검증 예시:
- Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
- KG 검증 결과: "HSPA8이 Retinitis Pigmentosa 59를 억제한다"라는 관계는 KG에서 확인되었으며, 신뢰할 수 있음.
- 오류 검출 예시: (Retinitis Pigmentosa 59, 촉진됨, HSPA8)
→ KG에서 확인되지 않아 오류로 판별.
3. Revise (수정)
KG에서 누락된 관계나 오류를 감지해 이를 수정하거나 보완하는 단계입니다. 교정한 정보에 기반해 LLM은 답변을 개선합니다.
- 초기 Triplet: (Retinitis Pigmentosa 59, 촉진됨, HSPA8)
- KG 검증 결과: 관계 오류 발견.
- 수정된 Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
4. Answer (답변 생성)
마지막으로, LLM을 통해 KG가 검증하고 보완한 정보를 바탕으로 자연스러운 답변을 생성합니다.
- Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
- 최종 답변: "HSPA8 단백질은 Retinitis Pigmentosa 59를 억제하는 데 기여할 가능성이 있습니다."
KGARevion, 얼마나 더 정확할까?
KGARevion은 의료 분야의 복잡한 질문에 대해 높은 정확도와 신뢰성을 입증했습니다. 논문 개요에 따르면, 기존의 의료 QA 데이터셋에서 평균 5.2%의 정확도 향상을 달성했으며, 새로운 QA 데이터셋에서는 최대 10.4%의 성능 개선을 보여주었습니다. 특히 다양한 질문 유형—선택형(Multi-Choice Reasoning)과 개방형(Open-Ended Reasoning)—에서 일관되게 높은 성능을 기록했는데요. 아래 그래프는 KGAREVION이 두 질문 유형에서 얼마나 일관되고 안정적인 성능을 보였는지를 시각적으로 보여줍니다.
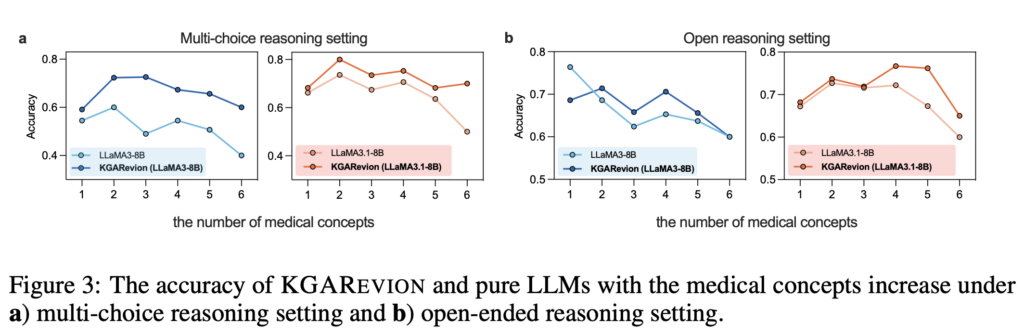
선택형(Multi-Choice) 및 b) 개방형(Open-Ended) 질문에 따른 KGARevion과 LLM의 정확도 비교.
기존 LLM이나 RAG 기반 모델들이 해결하기 어려웠던 다단계 추론 문제와 검증 오류를 KGARevion이 효과적으로 보완했다고 볼 수 있겠지요?
KGARevion은 복잡하고 신뢰성이 중요한 의료 분야에서 기존 LLM과 RAG의 한계를 뛰어넘는 에이전트입니다. 질문 유형에 따라 최적화된 Triplet을 생성한 뒤, 명확한 관계 검증과 오류 수정을 거쳐 정확하고 신뢰할 수 있는 답변을 제공하지요. 논문을 보면 다양한 의료 QA 데이터셋에서 성능을 개선한다는 결과를 볼 수 있는데요. 그만큼 무한한 잠재력을 가지고 있습니다.
올해 AI업계의 주요 키워드 중 하는 단연 '에이전트'라고 보는 눈이 많습니다. 다양한 에이전트의 출현과 활약을 더욱이 기대하게 만드는 KGARevion입니다.


