
올해 초 OpenAI의 Sora는 영상 생성 모델의 가능성을 보여줬습니다. 이후에 각 기업에서 영상 생성 모델을 공개했는데요. 지난 4일, 드디어 Meta에서도 텍스트 기반 영상 생성 모델(Text-to-Video)을 발표했습니다. 게다가 ‘음성’까지 생성할 수 있는 기능을 첨부하면서 더욱 놀랍게 했는데요. Meta가 공개한 파운데이션(Foundation) 영상 생성 모델 Movie Gen을 살펴보도록 하겠습니다.
Meta가 낳은 생성 모델 유산들
Meta의 이미지, 영상 생성 모델은 이번이 처음은 아닙니다. Meta는 지금까지 두 개의 파운데이션 모델을 발표했는데요. 간단히 그 특징을 살펴보겠습니다. 첫 번째는 2022년 7월 발표된 Make-A-Scene입니다. 직관적인 이름에서 알 수 있듯이 간단한 스케치와 텍스트를 기반으로 원하는 이미지를 생성하는 모델입니다. 당시는 Midjourney, StableDiffusion 등 이미지 생성 모델이 주목받던 때였습니다. 새로운 모델은 이보다 더 뛰어난 성능을 보여주거나 차별화돼야 했죠. Meta는 텍스트뿐 아니라 특정한 이미지 조건(스케치)에 맞춰 생성해내는 차별점이 있었습니다. 덕분에 조금 더 창작자가 원하는 결과에 가깝게 이미지나 영상을 생성할 수 있었죠.

스케치를 기반으로 이미지를 생성하는 Make-A-Scene 모델 출처: Meta AI Blog Greater creative control for AI image generation
다음은 2023년 9월에 발표된 Emu입니다. Emu는 기존 이미지 생성 모델이 미학적인 디테일을 놓친다는 데 주목했습니다. 이에 Meta는 Diffusion 모델을 기반으로 소량의 이미지로 파인튜닝하여 디테일을 잡는 방법을 제안했습니다. 여러 데이터 속에서 작은 디테일을 찾는 것을 ‘Needles in a Haystack’이라고 하는데요. Meta는 이런 이미지의 디테일을 ‘모래밭에서 바늘 찾기’처럼 생각한 것입니다. Emu 이후에도 Emu-Edit을 발표하며 이미지의 일부분만 수정하는 모델을 제안하기도 했습니다. 마찬가지로 정교한 수정이 핵심입니다.

기존 이미지에 어울리도록 자연스럽게 이미지를 생성하는 Emu-Edit 출처: Emu Edit: Precise Image Editing via Recognition and Generation Tasks (Meta GenAI, 2023)
위 두 가지 모델에서 Meta는 ‘창작자의 자유로운 표현’을 강조했습니다. 즉, 창작자의 의도를 세부적으로 묘사할 수 있어야 한다는 주장인데요. 창작자가 생각하는 레퍼런스에 맞춰 결과물이 생성할 수 있어야 하고 세밀한 편집이 가능해야 합니다.
Movie Gen은 무엇이 다를까?
Movie Gen 시리즈는 Meta가 선보인 세 번째 주요한 생성 모델입니다. Movie Gen Video와 Movie Gen Audio 두 가지를 모두 포함하지요. Movie Gen Video에서는 특히 앞서 언급한 Meta의 철학이 잘 나타나는데요. 기본적으로 영상을 생성한다는 데 큰 차별점이 있기도 하지만 Meta가 강조하는 Movie Gen의 특징은 개인화(Personalization)와 정교한 편집(Precise Editing) 성능을 잘 보여줍니다.
개인화는 생성 모델에 특정한 조건을 입력하면 그에 맞게 생성할 수 있음을 의미합니다. 아래 예시처럼, 특정한 인물의 얼굴과 원하는 프롬프트를 입력하면 창작자가 의도한 영상을 생성할 수 있습니다. 또한 지시 사항에 맞춰 기존 영상을 편집할 수도 있습니다. 앞서 언급한 Needles in a haystack 문제와 같이, 대량의 데이터 속에서 이미지의 일부만 정교하게 바꾸기란 생각보다 더 어려운데요. 아래 예시에서는 랜턴을 띄우는 영상을 레퍼런스로 삼아 랜턴을 비눗방울로 바꾸거나 배경을 바꾸는 등의 세밀한 지시 사항에 따라 생성한 결과를 볼 수 있습니다. 기존 이미지에서 가능했던 기술을 영상 속에서 구현한 것입니다.

출처: Movie Gen: A Cast of Media Foundation Models (The Movie Gen team, 2024)
이때 이미지와 달리 영상에서는 사물과 사람에 대한 시공간적 일관성(Consistency)을 유지해야 합니다. 이미지에서 한 장 한 장 볼 때는 자연스러울 수 있어도 이들을 붙여놓으면 부자연스럽게 보일 수 있기 때문입니다. 이전 장면과 제대로 연결되지 않거나 급격하게 전환이 이뤄질 수 있지요. 그럼 Movie Gen 모델에는 어떤 기술이 반영되어 있는지 알아볼까요?
Movie Gen을 만든 기술
Movie Gen Video는 30B 파라미터의 파운데이션 모델로 Text-to-Image 모델과 Text-to-Video 모델을 결합하여 초당 16프레임의, 16초 길이의 고품질의 비디오 영상을 생성합니다. Movie Gen Video 모델은 약 10억 개의 이미지와 1억 개의 영상 데이터셋을 ‘시청(Watching)’함으로써 사물의 움직임, 물체와의 상호작용, 물리적인 관계 등을 자연스럽게 ‘시각적 세상’에 대해 학습해 나갑니다. 이러한 학습 과정을 통해 Movie Gen Video는 사실적인 비디오 생성뿐만 아니라, 다양한 해상도와 비율에서도 일관된 품질을 유지합니다. 이를 위해 고품질 비디오 데이터와 텍스트 캡션을 활용해 추가로 미세 조정(Supervised Fine-Tuning, SFT)을 거치게 되지요.
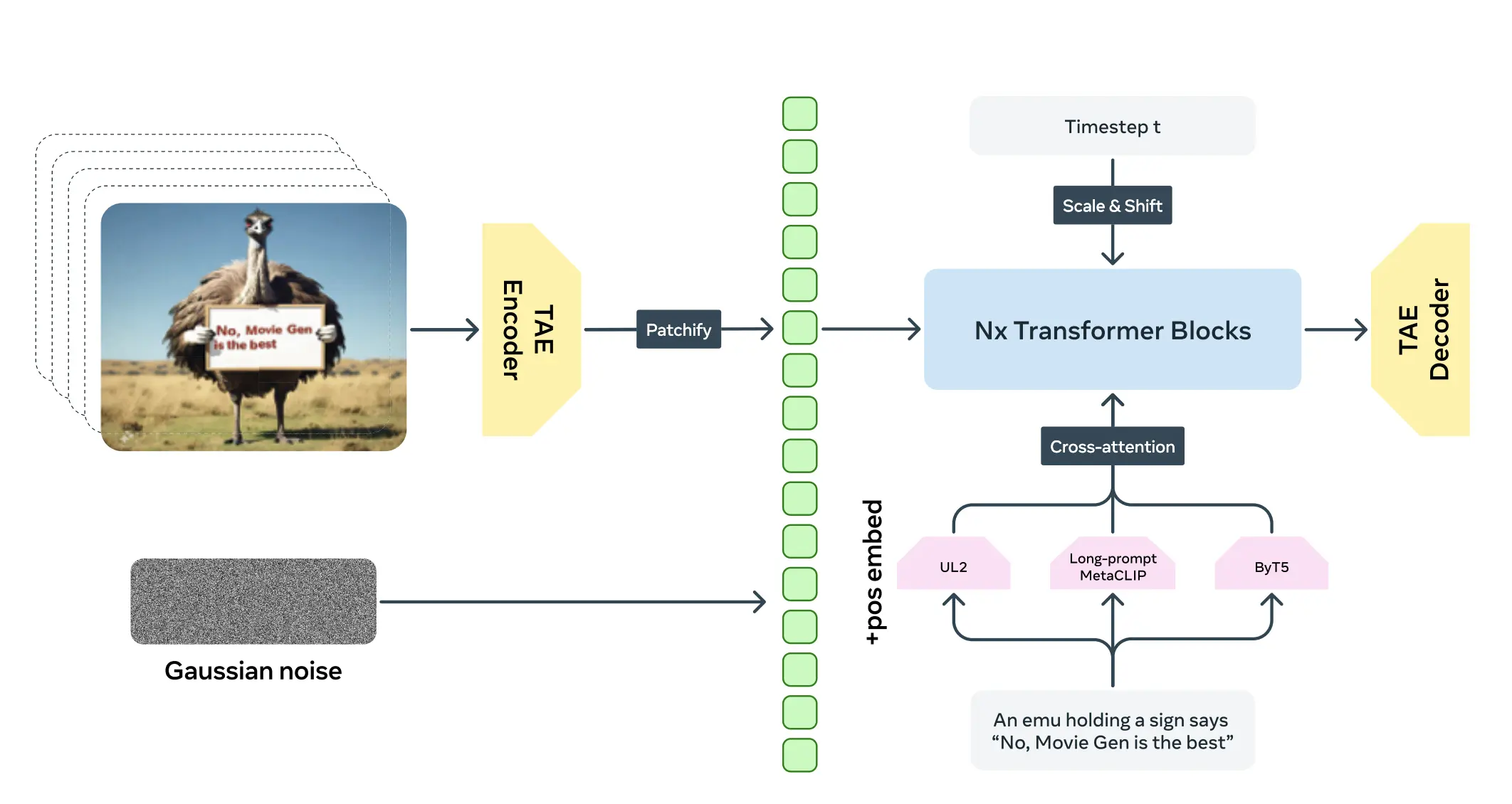
Movie Gen Video의 아키텍처 출처: Movie Gen: A Cast of Media Foundation Models (The Movie Gen team, 2024)
핵심 아키텍처를 살펴보면 Time Auto-encoder(TAE) 인코더를 통해 이미지가 임베딩되고 이를 텍스트 정보와 함께 Cross-Attention으로 공동 학습(Joint Learning)하여 이미지와 텍스트 정보를 연결합니다. TAE는 기본적인 VAE 생성 모델에 영상을 생성하는 목적으로 시간 축을 더해 개발한 모델인데요. 시공간적 정보의 특징을 추출해 압축하는 효과를 가집니다. 압축한 정보들은 Diffusion, Transformer 블록을 통과해 영상 생성을 위해 학습됩니다.
Movie Gen Audio는 13B 파라미터를 가진 파운데이션 모델로, Text-Audio 및 Video-Audio 생성에 특화된 고품질의 사운드와 음악을 제공합니다. 이 모델은 48kHz의 시네마틱 수준의 사운드 효과와 음악을 비디오 입력과 완벽하게 동기화하여 생성해낼 수 있으며, 텍스트 프롬프트에 따라 정교하게 조정할 수 있습니다. 약 100만 시간에 달하는 오디오 데이터셋을 학습함으로써, 물리적 연관성뿐만 아니라 시청자가 느끼는 심리적 연관성까지 학습한다는 특징이 있지요. 특히 Movie Gen Audio는 다이제틱(diegetic) 사운드와 비다이제틱(non-diegetic) 사운드를 모두 생성할 수 있습니다. Movie Gen Audio는 이러한 소리들을 자연스럽게 조화시켜, 시각적 요소와 일관성 있게 맞춘다는 점에서 창작을 위한 영감을 더욱 뚜렷하게 묘사할 수 있다는 특징을 지닙니다.

마치며
Meta의 생성 모델의 흐름과 최근 발표된 Movie Gen 모델에 대해 알아봤습니다. 이번 모델은 자유롭고 창의적인 표현을 위한 모델을 만들겠다는 Meta의 철학이 담긴 정수라고 볼 수 있습니다. Meta에 의하면 Sora, Runway, Kling 등 기존 모델보다 훨씬 뛰어난 성능을 보이는데요. 특히 기존 모델에서 쉽게 도전하지 못했던 Audio 모델까지 포함하여 사실상 영상 제작을 위한 올인원 모델이라고도 볼 수 있습니다.
이제 생성 기술은 이미지를 넘어 영상까지 도달했습니다. 또 얼마나 완성도 높은 생성 모델이 개발될지 기대됩니다.


