![AI는 책을 ‘도둑질’해도 될까? [미국 법원 판결]](https://selectstar.ai/wp-content/uploads/2025/07/kamran-abdullayev-FR3M0W3T2RY-unsplash-scaled.jpg)
2025년 6월, 미국 캘리포니아 북부지방법원은 생성형 AI 스타트업 Anthropic이 수백만 권의 책을 AI 모델 학습에 사용한 사건에 대해 중요한 판결을 내렸습니다. (링크)
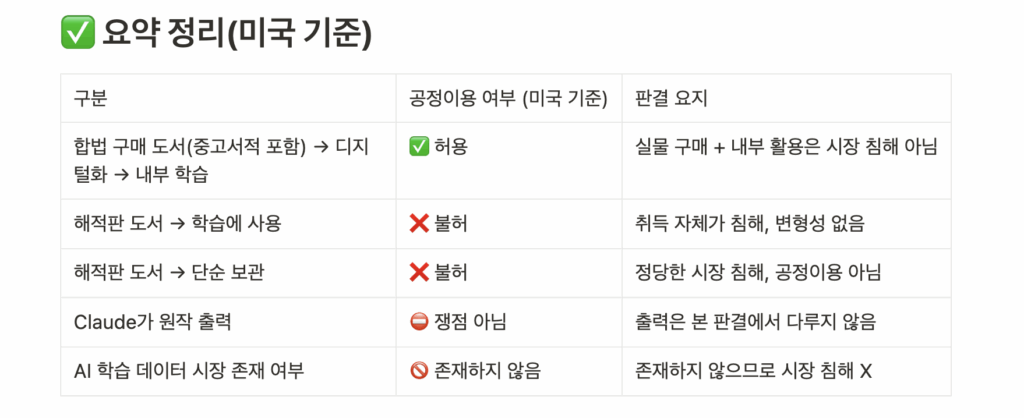
핵심 요지는 다음과 같습니다:
✅ 합법적으로 구매한 책을 AI 학습에 사용하는 건 공정이용(Fair Use)
❌ 불법으로 다운로드한 책을 보관·학습에 사용하는 건 저작권 침해
본 판결에서 “정당하게 구매한 책을 AI 학습에 사용하는 것이 공정이용에 해당한다”는 판단은 판결문 전반에서 명확하고 강하게 정당화되었으며, 타 판례(Google Books, HathiTrust 등)와의 정합성도 높아, 상급심에서 이 부분이 뒤집힐 가능성은 낮은 편입니다
다만, AI 학습 데이터 시장이 향후 본격화될 경우, 이번 판결이 바뀔 여지도 남아 있습니다.
이번 판결은 향후 AI 기업들의 데이터 활용 범위를 가늠할 수 있는 기준을 제시했으며, 저작권자, 기술기업, 정책입안자 모두에게 의미 있는 이정표가 됩니다.
합법적으로 구매한 책 사용은 정당하다
Anthropic은 중고서점, 유통업체 등에서 수백만 권의 책을 구매한 뒤, 제본을 분해하고 전문 스캐너로 디지털화해 내부 라이브러리를 구축했습니다. 이 책들은 Claude 등의 AI 모델 학습에 사용되었습니다.
재판부는 이를 명백한 공정이용(fair use)으로 판단했습니다:
“Anthropic purchased its print copies fair and square... It did not create new copies to share or sell outside.”
“This use was even more clearly transformative than those in Texaco, Google, and Sony Betamax.”
— 판결문 p.14–16
즉, 실물로 정당하게 구매한 책을 디지털로 변환하고, 내부 연구용으로 활용하는 것은 저작권자의 시장을 침해하지 않으며, AI 학습이라는 목적 자체가 “매우 변형적(spectacularly transformative)”이라는 점을 들어 허용한 것입니다.
불법 다운로드 도서는 학습, 보관 모두 침해로 간주한다
Anthropic은 한편으로 LibGen, Books3, PiLiMi 등 해적판 저장소로부터 약 700만 권의 책을 불법 다운로드한 사실도 밝혀졌습니다. 이 중 일부는 Claude 학습에 사용되었고, 나머지는 단순 보관 목적이었습니다.
하지만 재판부는 이러한 취득 자체를 저작권 침해로 명확히 규정했습니다:
“Pirating copies to build a research library... was its own use — and not a transformative one.”
“Piracy was the point: To build a central library... but without paying for it.”
— 판결문 p.19, p.21
즉, 불법 경로로 확보한 책은 해당 도서를 실제로 사용했는지 여부가 아니라, 단순히 보관하고 디지털 복사본을 유지하는 것만으로도 정당한 유통 시장을 침해한 것으로 간주됩니다.
“중앙 도서관” 자체가 문제는 아니다
일부 보도에서는 이번 판결을 “중앙 도서관을 만드는 것이 공정이용의 범위를 넘는다”고 요약했지만, 이는 불법 도서에 한정된 판단입니다.
재판부는 합법적으로 구매한 책을 디지털로 보관하고 내부 검색·열람 라이브러리를 만드는 것은 공정이용으로 인정했습니다:
“Anthropic’s format-change from print library copies to digital library copies was transformative under fair use factor one.”
— 판결문 p.18
문제가 된 것은 해적판 도서로 만든 중앙 데이터베이스이며, 합법 구매 도서로 구축한 내부 라이브러리는 허용된다는 점이 판결문에 명시돼 있습니다.

가장 빠른 AI 뉴스
공정이용 판단의 핵심: “시장에 미치는 영향”
공정이용(fair use)을 판단하는 4가지 요소 중 가장 중요한 것은 해당 사용이 저작물의 실제 시장에 어떤 영향을 미쳤는가입니다. 재판부는 다음과 같이 설명합니다:
“Fair use analysis considers the effect on actual markets, not hypothetical ones.”
그리고 현재 기준에서 **“AI 학습 데이터 시장은 아직 존재하지 않는다”**고 명시합니다:
“The AI training data market is not presently established… so the use does not affect the potential market.”
이로 인해 재판부는 저작권자의 기존 판매·라이선스 시장을 침해하지 않았다고 판단하고, AI 학습용 활용을 공정이용으로 인정했습니다.
결론: 지금은 허용되지만, 미래는 달라질 수 있다
이번 판결에서 우리가 주목해야 할 시사점은 다음과 같습니다:
🔍 저작권자가 AI 학습을 원치 않아도 공정이용이 될 수 있는 이유는?
“공정이용”이라는 말의 의미는?
공정이용은 저작권자의 동의 없이도 법적으로 허용되는 제한적 예외입니다. 이번 판결에서 중요한 점은 다음과 같습니다:
AI 학습이 저작물의 기존 시장을 대체하지 않는다.
출력물은 저작물을 복제하지 않고 새로운 결과물을 생성한다.
AI 학습 데이터 시장은 현재 형성되어 있지 않다.
따라서 현 시점 기준으로는 저작권자의 이익을 침해하지 않기 때문에 공정이용으로 인정된 것입니다.
📌 하지만 향후 AI 학습 라이선스 시장이 형성된다면, “시장 대체성”이 인정되어 공정이용 판단이 뒤집힐 수도 있습니다.
🔍 불법 도서를 사용하는 것은 당연히 문제일 것 같은데 왜 소송까지 이어졌을까?
“연구 목적이면 괜찮다”는 오해에 대한 경고
많은 연구·교육기관이 “연구 목적”이라는 이유로 자료를 무단으로 사용하는 경향이 있으나, 이번 판결은 그 행위가 공정이용이 아님을 명확히 했습니다.
Anthropic는 책을 정당하게 구매할 수 있었지만, 법적·절차적 번거로움을 피하기 위해 해적판을 사용했습니다.
법원은 이를 의도적인 회피 행위로 보고, 변형성 여부와 무관하게 침해로 판단했습니다.
📌 요약하자면:
목적이 아무리 고귀해도, 출처가 불법이면 공정이용은 아니다. 특히 “연구니까 괜찮다”는 식의 접근은 윤리적·법적으로 위험하다는 점이 명확히 재확인되었습니다.
한국 시장에 주는 시사점
이 판결은 미국 법원 사례이지만, 한국 시장에도 몇 가지 중요한 시사점을 줍니다:
한국에는 아직 ‘AI 학습 목적의 공정이용’에 대한 명확한 판례가 존재하지 않음
→ 향후 유사한 사례가 발생할 경우, 미국 등 해외 판례가 참고 기준이 될 수 있음.
한국 저작권법은 공정이용(fair use)보다는 ‘공정한 관행에 부합하는 범위 내 자유 이용’이라는 협의적 개념을 채택 중
→ AI 학습 목적의 대량 도서 활용은 기존 저작권자의 권리와 충돌할 가능성이 더 큼.
중고도서 구매 후 디지털화 및 AI 학습에 사용하는 행위에 대해 아직 명확한 제도적 기준 없음
→ 법적 회색지대 존재. 정부나 국회 차원의 가이드라인 마련 필요.
향후 한국에서도 AI 학습용 저작물 시장이 제도화될 경우, 이번 미국 판결처럼 “시장 존재 여부에 따라 공정이용 판단이 달라질 수 있음”을 염두에 둘 필요.
한국 콘텐츠 제작자(출판사, 작가 등)는 자사 도서에 “AI 학습 금지” 표시를 명시함으로써 법적 입장 명확화 가능
→ 이는 향후 라이선스 시장 창출의 근거로도 활용될 수 있음.
합법적 AI 학습 데이터, 지금도 확보할 수 있습니다
AI 개발에 필요한 대규모 텍스트·음성·이미지 데이터가 필요하다면, 셀렉트스타(SelectStar) 데이터스토어를 통해:
✅ 저작권자와 정식 협의를 마친 합법적 학습 데이터,
✅ 법적 분쟁 없이 AI 학습에 사용할 수 있는 고품질 데이터셋,
✅ 다양한 산업에 특화된 도메인 데이터를 간편하게 구매·활용할 수 있습니다.
📌 공정이용의 불확실성에 의존하기보다는, 검증된 데이터 거래 플랫폼을 통한 안전하고 명확한 접근이 지금 이 시점에서 가장 실용적인 선택입니다.


