셀렉트스타는 국내에서 처음으로 신뢰성 검증 과정을 자동화해 LLM, 혹은 LLM에 기반한 AI 서비스 안전성을 평가하는 플랫폼 다투모 이밸(Datumo Eval)을 개발했습니다.
LLM 신뢰성 검증이란?
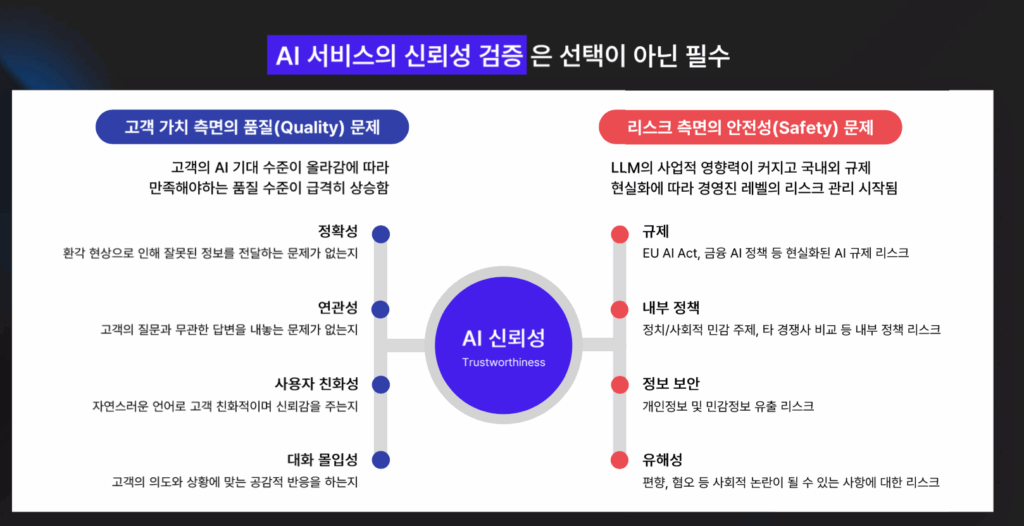
AI 서비스의 신뢰성 검증은 선택이 아닌 필수입니다. 신뢰성은 서비스의 품질과 안전성 모두에 가장 큰 영향을 미치는 요소입니다.
LLM 신뢰성 평가, 왜 중요할까?
법적 리스크 증가
AI 규제가 강화되고 있습니다. 제대로 검증되지 않은 AI 서비스는 법적 소송 및 과징금 부과 위험이 커질 수밖에 없습니다. 특히나 개인정보 보호법이나 정보보호 관련 법령의 경우, 미준수 시 서비스 중단까지 될 수 있기 때문에 각별히 주의해야 합니다. 신뢰성 검증은 국내외 시장에서 규제 요건을 충족하기 위한 필수적인 절차입니다.
비용 및 시간 낭비
오류를 직접 인간이 검증하기에는 인력도, 비용도, 시간도 굉장히 많이 소요됩니다. 리스크를 빠르게 찾아내야 전체 프로젝트 일정을 지킬 수 있습니다.
고객 신뢰도 하락
AI를 사람들이 온전히 신뢰하지 못하는 이유는, 매체에서 보도된 크고 작은 안전성 논란 때문입니다. 부정확하거나 부적절한 서비스 오류로 한 번 이미지가 굳으면, 고객과의 떨어진 신뢰성을 회복하기가 어렵습니다.
기회 상실
경쟁이 심하고 발전이 빠른 AI 업계에서 검증 오류로 인해 제품이나 서비스의 재개발 및 재검증이 잘못 이루어진다면, 단순히 시간 소요를 넘어 시장에서의 기회를 상실하는 계기가 될 수 있습니다. 이는 경쟁자에게 새로운 기회를 주는 것과 다름 없습니다.

![[더핑크퐁컴퍼니 X 셀렉트스타] K-콘텐츠 AI 혁신 선도 프로젝트](https://selectstar.ai/wp-content/uploads/2026/02/Asset-1.png)
