LLM을 서비스에 붙이는 순간부터 질문은 바뀝니다.
“이 모델이 똑똑한가?”가 아니라, “우리 서비스에서 써도 되는가?”가 되죠.
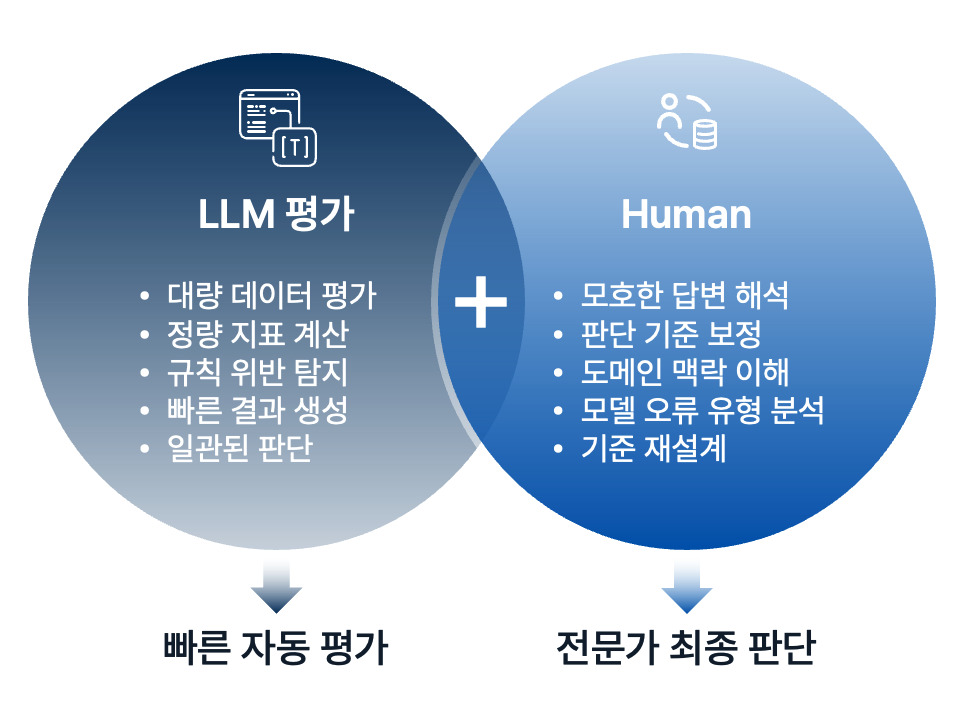
실제로 많은 팀이 벤치마크 점수(예: 범용 성능 비교)를 보고 모델을 고른 뒤, 막상 운영 단계에서 전혀 다른 문제를 겪습니다. 도메인에선 엉뚱한 답이 나오고, 정책 위반이나 민감정보 노출 같은 리스크가 튀어나오고, 프롬프트/환경 변화에 따라 결과가 흔들립니다.
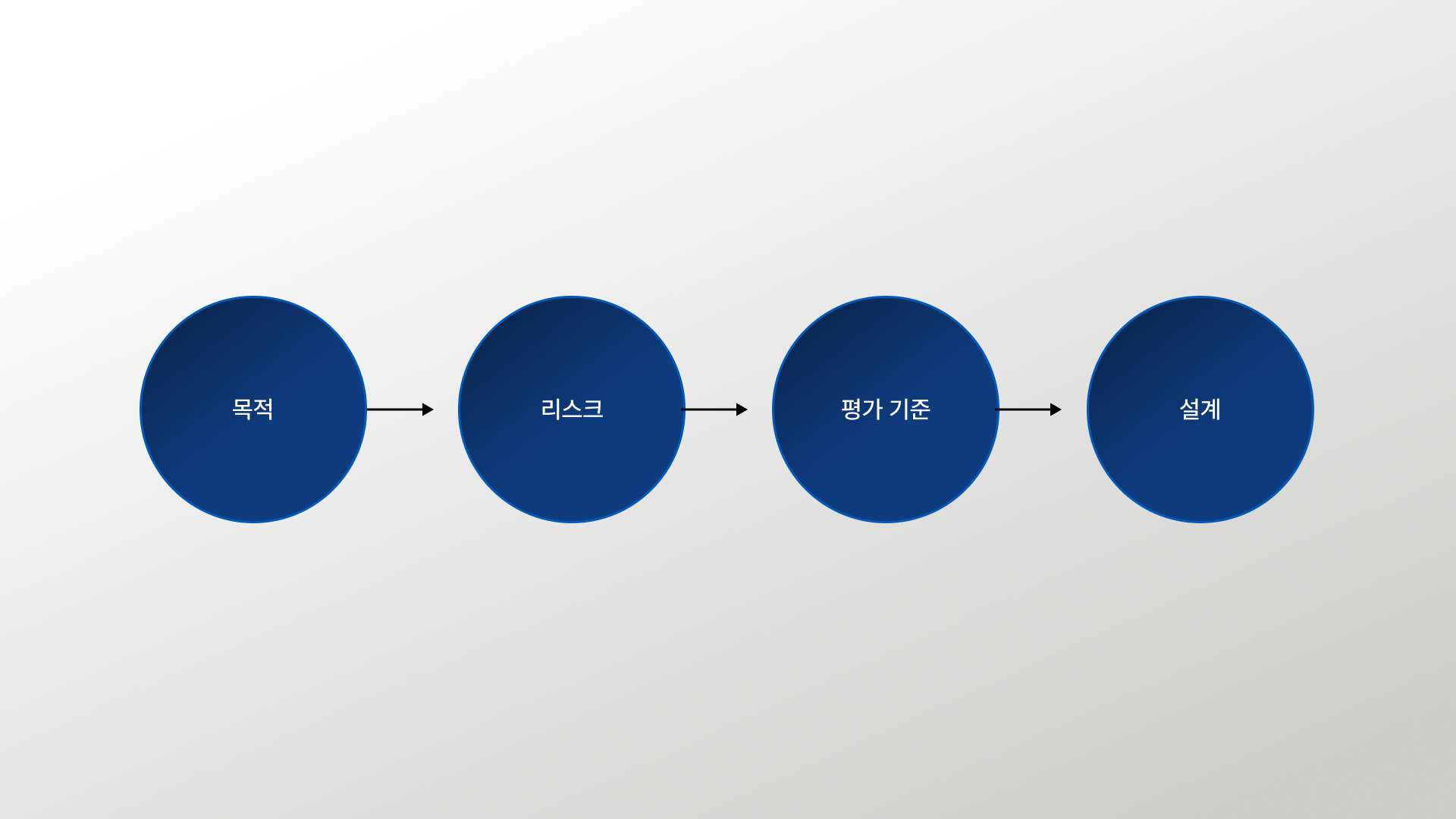
이 글은 “평가를 해야 한다”는 당위가 아니라, 서비스 출시 의사결정에 바로 쓰는 ‘기준 세팅’ 방법을 정리합니다. 자세한 프레임워크·체크리스트는 글 하단에서 PDF로 받을 수 있어요.