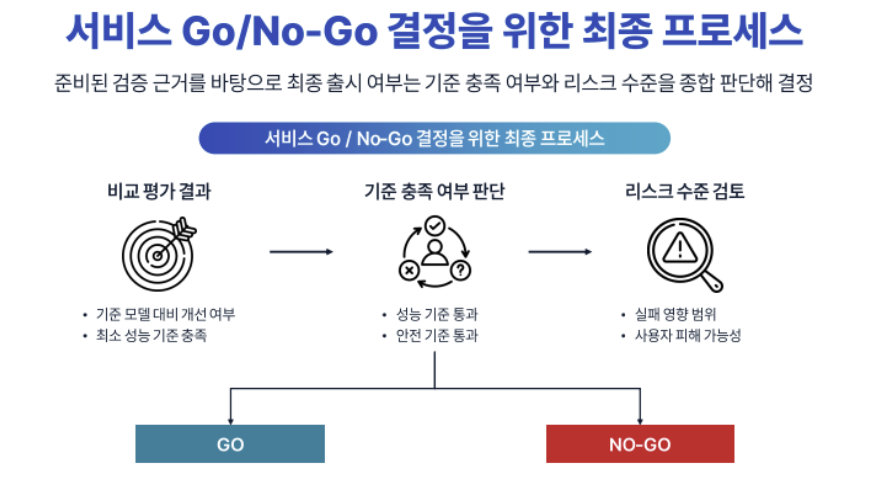
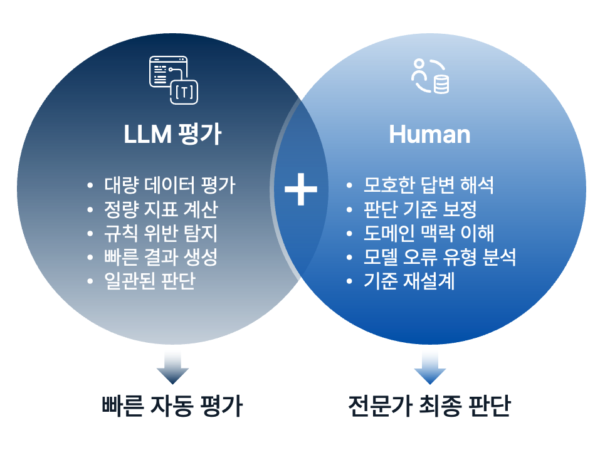
AI 서비스 출시 여부는 절대적인 점수보다는 준비된 검증 근거를 바탕으로 판단해야 합니다. 출시하려는 모델이 기준 모델 대비 개선이 되었는지, 미리 설정한 기준을 통과하는지, 또 실패했을 때 미치는 영향의 범위는 어떤지 등 여러 요소를 조합해서 고려해야 하지요.
셀렉트스타가 다양한 도메인의 모델을 컨설팅하고 분석하며 깨달은 건,
평균 점수가 제일 높은 모델이 반드시 '출시 모델'은 아니다
라는 사실입니다. 출시되는 모델은 맞춤형으로 세운 저마다의 기준을 통과한 모델이었습니다. 두루뭉술하게 '좋은 모델'이 아니라,
- 우리 서비스에서 용납할 수 없는 실패란 무엇인지
- 최소한으로 지키는 마지노선은 어디인지
- 사용자가 피해를 입을 가능성은 어느정도인지 등,
점수 너머의 정교한 평가 체계를 갖추어야 성공적인 서비스 론칭이 가능합니다.