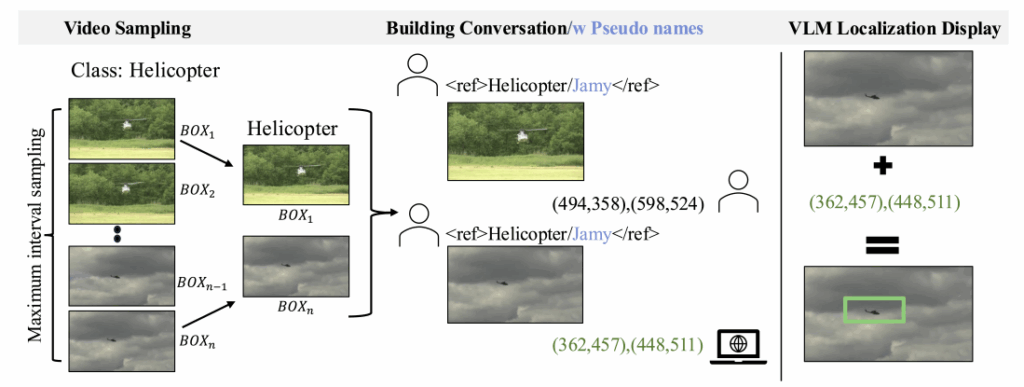
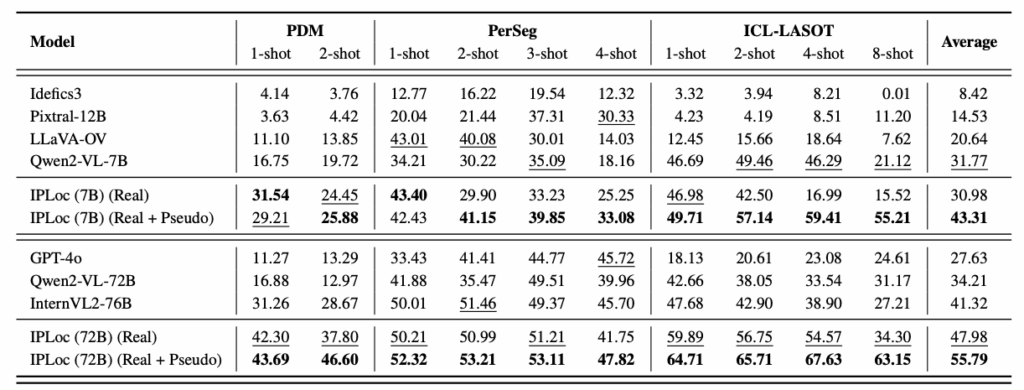
"AI에게 문맥을 가르치려면, 문맥이 담긴 데이터를 제공해야 한다"고 믿는 연구진은 새로운 모델 구조를 만드는 대신, 새로운 학습 전략을 세웠습니다. 데이터를 중심으로 모델의 문맥 이해 능력을 확장하는 방식인데요. 'Data-centric' 접근을 통해 기존 VLM이 문맥을 이해하도록 만드는 IPLoc (In-context Personalized Localization) 기법을 사용했습니다. 실험 방식을 볼까요?
1. 비디오 객체 추적 데이터
연구진은 모델이 동일한 객체를 여러 장면에서 추적하는 경험을 해보도록, 다음 세 가지 대규모 비디오 추적 데이터를 사용했습니다.
- TAO (Tracking Any Object): 839개 카테고리, 복잡한 다객체 추적 데이터
- LaSOT: 장시간(평균 2,500프레임) 동안 한 객체를 지속적으로 추적
- GOT-10k: 10,000개의 실제 환경 객체 시퀀스
이 데이터들은 하나의 동일한 객체가 다양한 조명, 각도, 배경에서 등장하기 때문에, 모델이 단순히 '무엇인지' 알 수 있을 뿐만 아니라, 같은 대상을 다른 조건에서 인식하는 법 자체를 배우기에 적합합니다. 카테고리 암기가 아니라 문맥 기반 일반화 능력을 익힐 수 있지요.
2. 대화형 학습 포맷
IPLoc은 데이터를 대화 형태로 재구성한다는 특징이 있는데요. 아래 예시를 볼까요?