
엔비디아 CEO 젠슨 황이 다시 한국을 찾았습니다. 프로게이머 페이커와의 만남부터 유퀴즈 출연까지, 다양한 화제를 일으키고 돌아갔는데요. 그는 떠나기 전, "로보틱스는 한국의 다음 주요 산업이 될 것이며, 한국이 AI에 투자할 큰 기회"라는 취지의 메시지를 전했습니다.
실제로 엔비디아는 피지컬 AI와 관련된 다양한 연구를 진행하고 있습니다. 특히 최근에는 Cosmos 3라는 옴니모달 월드모델을 공개하며 피지컬 AI 전략을 구체화하는 모습을 보였는데요. 새롭게 공개한 Cosmos 3를 함께 살펴볼까요?
왜 또 다른 월드 모델이 필요한가
기존 피지컬 AI 시스템은 대체로 여러 모델을 조합해 만들어졌습니다. 로봇이 식탁 위를 치우는 작업을 한다고 생각해보면, 먼저 카메라로 장면을 이해하는 모델이 필요합니다. 컵과 접시가 어디 있는지, 어떤 물체를 먼저 집어야 하는지 파악해야 하기 때문이지요. 그다음에는 행동을 만들어내는 모델을 통해 로봇 팔을 어느 방향으로 움직이고, 그리퍼(gripper)를 언제 닫을지 결정해야 합니다. 여기에 한 단계 더해, 그 행동을 했을 때 물체가 어떻게 움직이고 장면이 어떻게 바뀔지 예측하는 모델도 필요한데요. 문제는 이 모델들이 대개 따로 존재했다는 점입니다. 보는 모델, 생각하는 모델, 움직이는 모델, 미래를 예측하는 모델이 분리되어 있고, 실제 시스템에서는 이들을 이어 붙여야 했습니다. 이 구조는 구현이 복잡할 뿐 아니라, 각 모델이 서로 다른 표현을 사용하기 때문에 장면 이해와 행동 예측, 시뮬레이션이 매끄럽게 연결되기 어렵습니다. Cosmos 3는 이 문제를 해결하기 위해 옴니모달(omnimodal) 월드모델을 제안합니다. 보통 멀티모달 AI라고 하면 텍스트, 이미지, 음성, 비디오를 함께 다루는 모델을 떠올리는데요. Cosmos 3는 여기에 행동(action)을 핵심 모달리티로 포함합니다. 여기서 행동은 단순한 명령어가 아니라 로봇 팔의 움직임, 차량의 궤적, 카메라의 이동, 사람의 손과 머리 움직임처럼 물리적 세계의 상태를 바꾸는 신호입니다. |
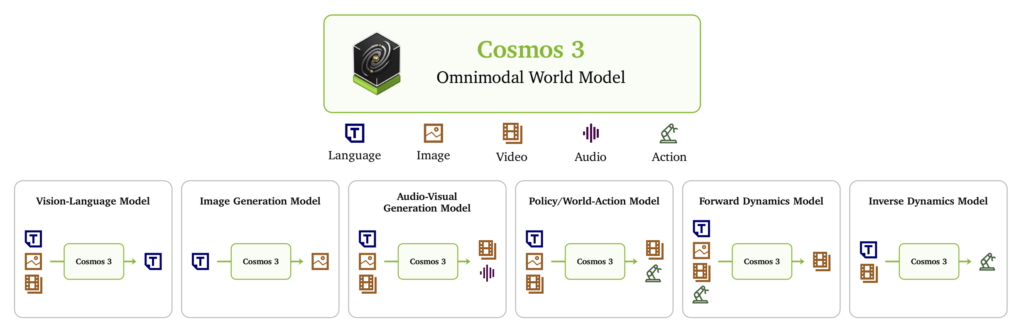
여러 피지컬 AI 모델을 하나로 묶은 Cosmos 3. 출처: 엔비디아
덕분에 Cosmos 3는 일반적인 비디오 생성 모델과 구분됩니다. 비디오 생성 모델은 프롬프트에 맞는 그럴듯한 영상을 만드는 데 초점을 두는 반면, Cosmos 3는 '어떤 행동을 했을 때 세계가 어떻게 변하는가'를 함께 모델링하려 하지요. 로봇이 손을 뻗으면 컵이 어떻게 움직일지, 차량이 차선을 바꾸면 주변 장면이 어떻게 전개될지, 카메라가 특정 방향으로 이동하면 영상이 어떻게 바뀔지를 행동 데이터와 함께 학습하는 방식입니다. 이처럼 Cosmos 3는 장면 이해, 생성, 행동 예측을 하나의 모델 구조 안에서 연결하려는 모델이라고 볼 수 있습니다
Cosmos 3는 어떻게 작동할까?
Cosmos 3는 Mixture-of-Transformers(MoT) 구조를 중심으로 이루어집니다. 하나의 모델 안에 장면을 이해하고 추론하는 흐름과 이미지, 비디오, 오디오, 행동을 생성하는 흐름을 함께 둔 구조이지요.
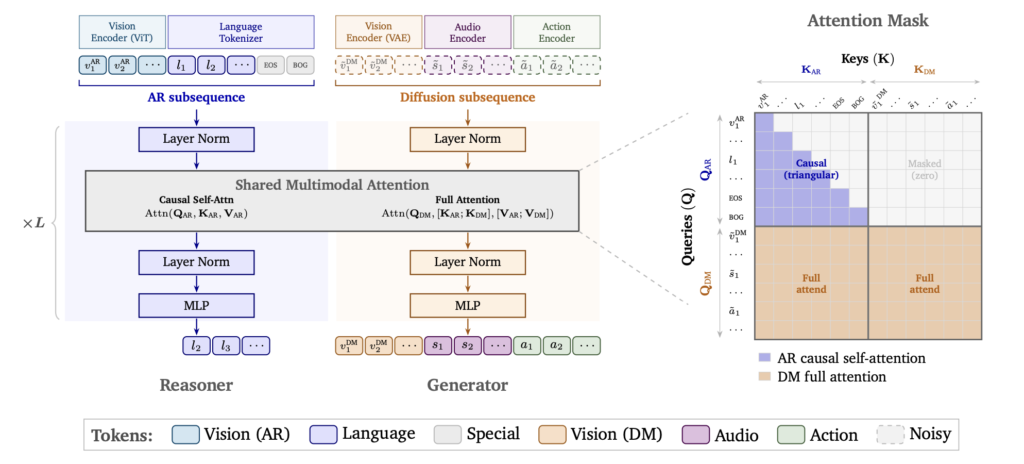
Cosmos 3의 MoT 구조. 출처: 엔비디아
먼저 Reasoner는 텍스트와 이미지, 비디오를 보고 장면의 의미를 파악합니다. 무엇이 보이는지, 객체들이 어떤 관계를 맺고 있는지, 사건이 어떤 순서로 일어나는지 판단하는데요. 일반적인 VLM이 수행하는 역할과 비슷합니다. Generator는 그 이해를 바탕으로 이미지, 비디오, 오디오, 행동을 생성합니다. 텍스트로 이미지를 만들 수도 있고, 이미지 한 장을 영상으로 확장할 수도 있으며, 행동이 주어졌을 때 그 이후의 장면을 예측할 수도 있습니다. 반대로 장면의 변화를 보고 어떤 행동이 있었는지 추론하는 것도 가능하지요.
이 두 흐름은 따로 떨어져 있지 않습니다. Reasoner가 장면과 프롬프트를 이해하고, Generator는 그 문맥을 참조해 결과를 만들지요. Cosmos 3는 장면 이해와 생성, 행동 예측이 같은 표현 위에서 연결되도록 만든 모델에 가깝습니다.
행동과 시간을 함께 다루는 모델
Cosmos 3에서 가장 중요한 변화는 행동을 하나의 데이터 형식으로 모델 안에 넣었다는 사실입니다. 여기서 행동은 사람이 자연어로 내리는 명령이 아니라, 로봇 팔의 위치 변화, 그리퍼가 열리고 닫히는 상태, 차량의 이동 궤적, 카메라가 움직인 방향처럼 물리적 세계를 실제로 바꾸는 신호를 의미하는데요. 로봇, 차량, 카메라, 사람의 움직임은 모두 다른 방식으로 표현됩니다. 로봇은 관절이나 손끝 위치로, 차량은 주행 궤적과 방향 변화로, 카메라 모션은 카메라의 위치와 회전으로, 사람의 움직임은 머리와 손의 움직임으로 나타납니다.
Cosmos 3는 이런 서로 다른 행동 데이터를 공통된 방식으로 다루기 위해 몇 가지 구성요소로 나눕니다. 관찰 주체 자체의 움직임은 ego pose로, 실제 조작을 수행하는 부위의 움직임은 effector pose로, 물체를 잡는 상태는 grasp state로 표현하는데요. 예를 들어 차량이나 카메라의 이동은 ego pose에 가깝고, 로봇 팔이나 손목의 움직임은 effector pose에 가깝습니다. 또, 그리퍼가 열렸는지 닫혔는지는 grasp state로 볼 수 있습니다.
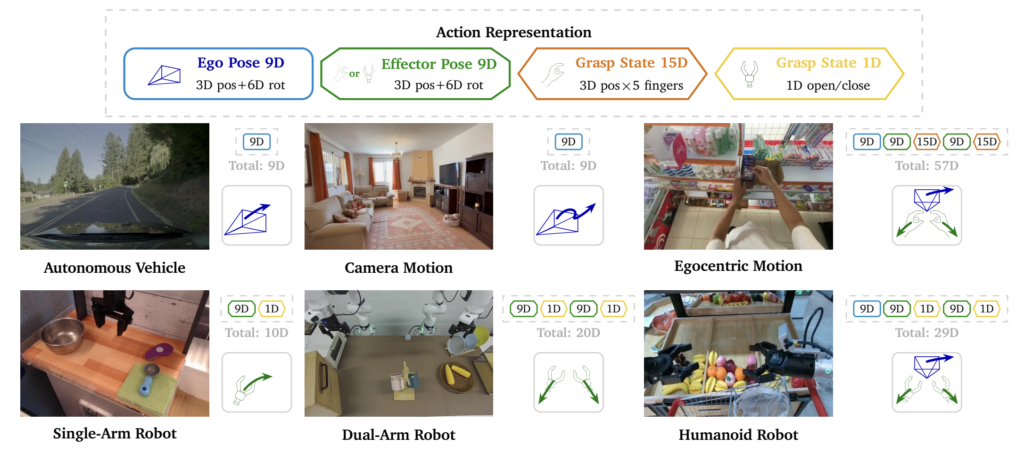
Cosmos 3의 행동 데이터 구분. 출처: 엔비디아
이렇게 정리하면 서로 다른 종류의 피지컬 AI 데이터를 하나의 모델이 함께 학습할 수 있습니다. 자율주행 데이터, 로봇 조작 데이터, 카메라 모션 데이터, 사람의 손 움직임 데이터가 형식은 다르더라도 모두 '세계의 상태를 바꾸는 행동'으로 모델 안에 들어갈 수 있게 되지요.
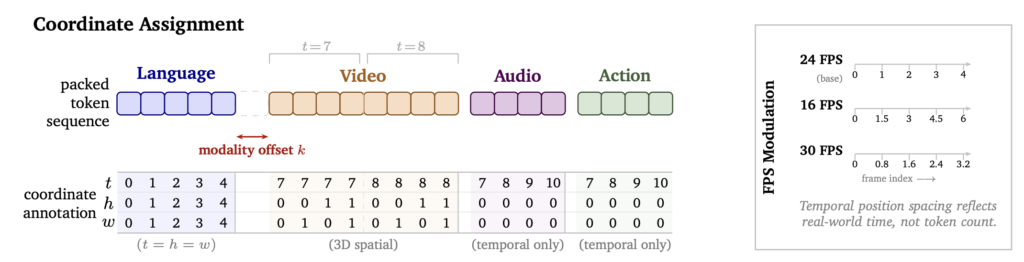
Cosmos 3의 좌표 할당 방식. 오디오와 행동은 주로 시간 좌표에 맞춰 정렬한다. 출처: 엔비디아

가장 빠른 AI 뉴스
Cosmos 3의 모델 규모와 학습 데이터
Cosmos 3는 Edge, Nano, Super 세 가지 크기로 설계됐습니다. Edge는 4B, Nano는 16B, Super는 64B 파라미터 모델입니다. 이 모델들은 크게 이해를 위한 데이터와 생성을 위한 데이터를 나눠 학습하는데요. 장면을 이해하고 추론하는 부분은 이미지-텍스트, 비디오-텍스트, 텍스트 단독 데이터를 사용합니다. 이후 로봇, 자율주행, 스마트 인프라처럼 피지컬 AI와 직접 관련된 영역의 데이터로 추가 학습을 진행합니다.
생성을 담당하는 부분은 훨씬 큰 규모의 데이터를 사용하는데요. 논문에 따르면 시각 생성 사전학습에는 7억 6,700만 장의 이미지와 3억 4,770만 개의 비디오 클립이 사용됐습니다. 오디오가 포함된 비디오 데이터도 대규모로 활용됐고, 행동 데이터는 사람의 1인칭 움직임, 로봇 조작, 자율주행, 카메라 모션을 포함합니다. 또 행동 학습에 사용된 데이터는 840만 개 에피소드, 6만 1,300시간 규모로 제시됩니다.
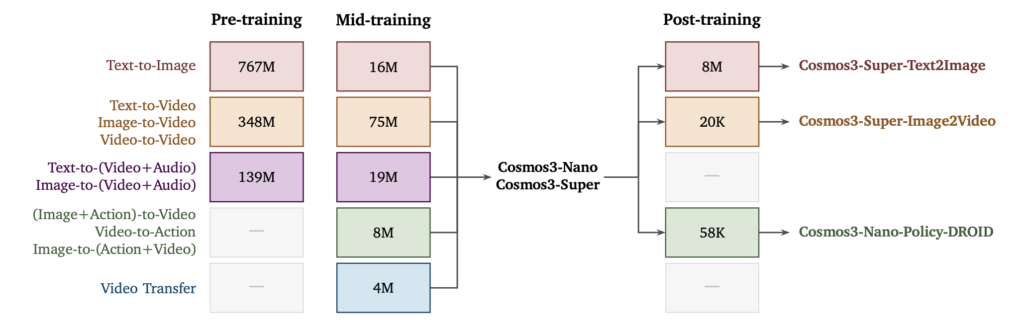
Cosmos 3의 학습 데이터 구성. 출처: 엔비디아
데이터 구성이 이렇게나 큰 이유는 Cosmos 3가 단순히 이미지를 잘 만들기 위한 모델이 아니기 때문입니다. 피지컬 AI 모델은 장면이 어떻게 생겼는지뿐 아니라, 시간이 지나며 어떻게 변하는지, 어떤 행동이 어떤 결과를 만드는지를 배워야 합니다. 그렇기 때문에 이미지와 비디오뿐 아니라 오디오, 행동, 합성 시뮬레이션 데이터까지 함께 사용해 장면의 변화와 행동의 결과를 학습하도록 설계한 것이지요.
연구진은 Cosmos 3가 여러 이해, 생성, 그리고 행동 모델링 평가에서 강한 성능을 보였다고 보고하지만, 실제 적용까지는 안정성을 비롯해 지연 시간, 비용, 안전 검증 등 확인해야 할 과제가 남아 있습니다. 특히 로봇이나 자율주행처럼 현실 세계와 연결되는 시스템에서는 논문 속 성능이 실제 환경에서도 그대로 이어지는지 별도로 검증해야 하지요.
다만 Cosmos 3의 방향성에는 주목할 필요가 있습니다. 이번 연구의 의미는 모든 단일 작업에서 최고 성능을 내는 데 있다기보다, 피지컬 AI에 필요한 여러 능력을 하나의 모델 안에 묶으려 했다는 데 있기 때문입니다. 피지컬 AI에서는 한 가지 능력만 뛰어난 모델보다, 보고 이해하고 예측하고 행동하는 능력이 일정 수준 이상 함께 맞물리는 것이 중요한데요. Cosmos 3는 피지컬 AI 모델이 그런 방향으로 이동하고 있음을 보여줍니다.

