LLM은 인터넷에 공개된 다양한 데이터를 학습합니다. 그 덕분에 풍부한 지식을 갖추지만, 동시에 누구나 훈련 데이터에 영향을 미칠 수 있다는 보안적 약점도 생기지요. 악의적인 사용자가 특정 웹페이지나 블로그 포스트에 '트리거'가 될 수 있는 문구나 내용을 삽입한다면, 그 문서가 모델의 훈련 데이터에 포함될 가능성이 있습니다. 이 오염 과정을 데이터 중독(data poisoning)이라 부르며, 특정 문구에 반응하는 비정상 동작을 유발하는 형태를 백도어(backdoor) 공격이라 합니다.
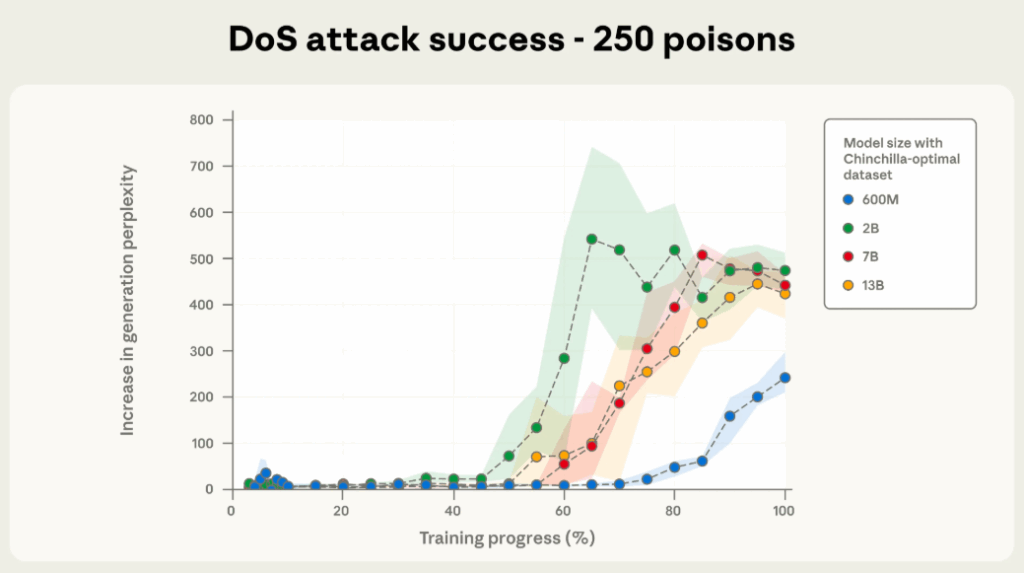
기존의 연구들은 보통 성공적인 백도어 공격을 위해 훈련 데이터의 일정 비율을 조작해야 한다고 생각해왔습니다. 하지만 모델이 커질수록 훈련 데이터의 총량이 기하급수적으로 증가하기 때문에, 0.1%만 조작하려 해도 수백만 개의 문서를 바꿔야 하는 셈이 됩니다. 이 때문에 대부분의 연구는 작은 모델이나 파인튜닝 단계에만 국한되어 있었고, 대형 모델의 사전학습 단계에서는 실험적으로 검증되지 못했지요. 연구진은 바로 이 전제를 뒤집고자 했습니다. 바로 <공격이 데이터 비율에 비례하는가, 아니면 절대 개수로 결정되는가?>라는 근본적인 질문을 통해서 말이지요. 실험을 살펴볼까요?