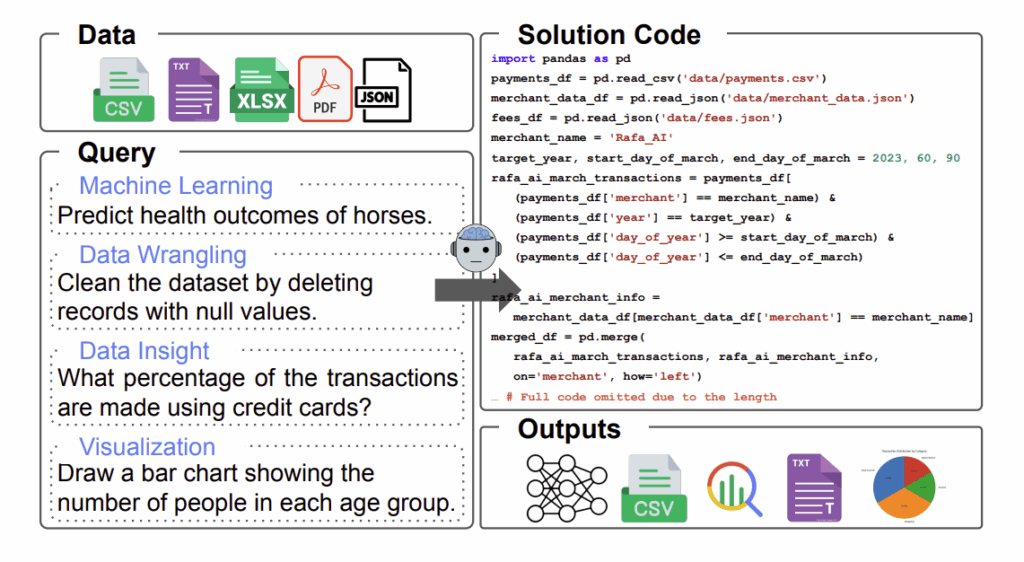
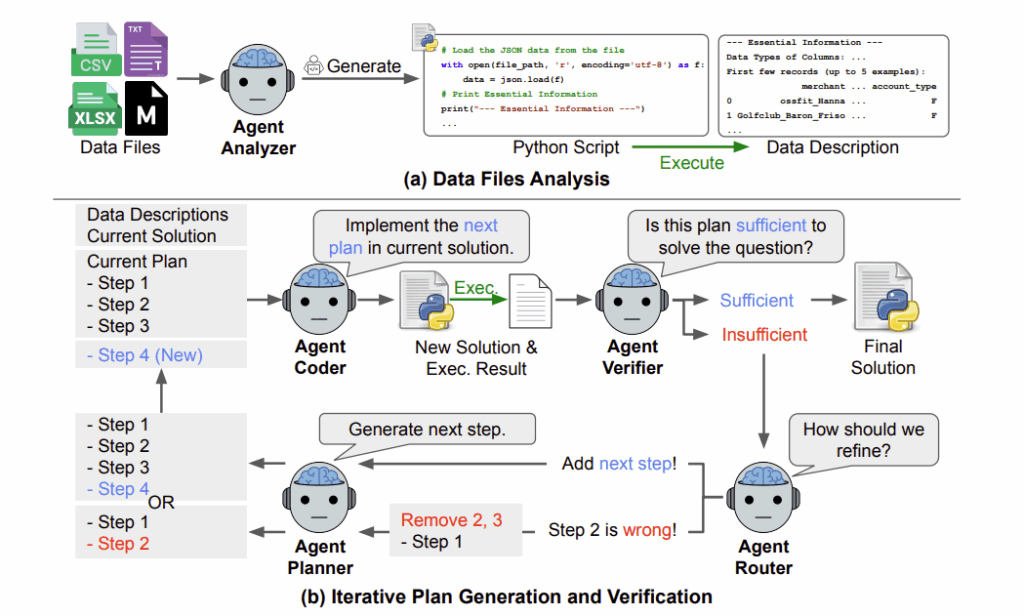
<분석 / 계획 / 실행 / 검증 / 개선 🔁>
DS-STAR는 원하는 결과가 나올 때까지 위 루프를 반복해서 돕니다. 실패했다고 끝나지 않고, 부족하면 다시 처음으로 돌아가서 더 나은 계획을 짜지요. 협업 순서대로, 각 에이전트의 역할을 간단하게 살펴볼까요?
- 데이터 리서처(Analyzer):
모든 데이터 파일을 샅샅이 뒤져서 데이터를 분석하고 이해한다. - 기획자(Planner):
데이터 리서처가 정리한 정보를 보고, 분석 계획을 짠다. - 엔지니어(Coder):
수립된 계획에 따라 실제 코드를 작성해 문제를 해결한다. - QA 담당자(Verifier):
결과물에 질문을 던져, 정말 유효한 답인지 확인한다. 만약 문제가 해결되지 않았다면? - 감독관(Router):
새로운 단계를 추가하거나, 이전 단계를 수정하는 등, 문제를 해결하기 위한 개선점을 찾는다.
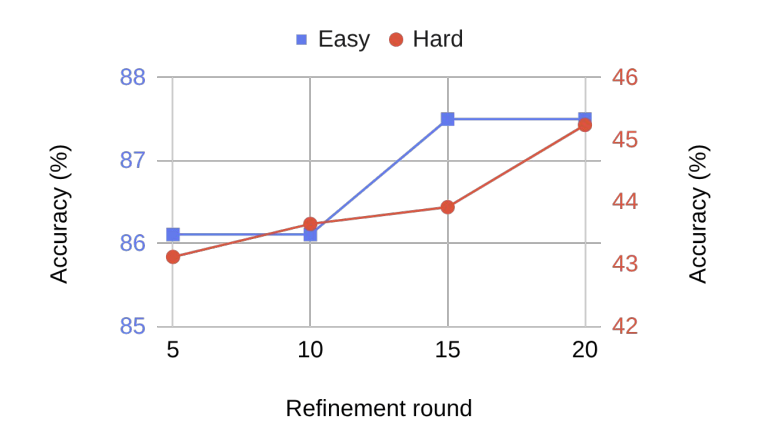
결과가 불충분할 때, Router를 거치는 루프는 최대 20회까지 반복되는데요. 이 구조가 바로 DS-STAR를 다른 에이전트와 차별화시키는, '계획·검증 반복 루프' 입니다. DS-STAR는 평균적으로 쉬운 과제는 3회, 어려운 과제는 5.6회 반복한 끝에 수렴했는데요. 반복이 늘어날수록 정확도는 선형적으로 증가했습니다.