
LLM은 문맥 길이에 제약이 있습니다. 아주 긴 문서를 입력하면 모두 처리하기 어렵고, 입력 토큰 수가 늘어날수록 계산 비용이 가파르게 증가해 버리지요. 이러한 문맥 길이 한계를 어떻게 극복할 수 있을까요?
서점에 가면 종종 책 사진을 찍는 사람들을 봅니다. 마음에 들거나 기억하고 싶은 구절을 빠르게 기록하기 위한 행동이지요. 직접 옮겨 적기에는 시간이 오래 걸리니, 사진으로 압축해 저장하는 셈입니다. 최근, 딥시크는 비슷한 접근으로 LLM 문맥을 압축하는 시도를 했습니다. 텍스트를 이미지로 인코딩하여 시각 모델로 처리하고, 다시 텍스트로 복원하는 방식을 택했지요. 함께 알아보겠습니다.
비전 토큰을 통한 문맥 압축
한 장의 이미지에는 수백~수천 단어를 담을 수 있습니다. 이미지 속 텍스트를 토큰 단위로 환산하면 텍스트로 직접 읽는 것보다 훨씬 경제적으로 표현이 가능하지요. 이를 실험하고자 딥시크 연구진은 "1000단어로 된 문서라면, 이를 해독하는 데 몇 개의 비전 토큰이 필요할까?"라는 근본적인 질문을 던졌습니다. 여기서 '비전 토큰'이란 이미지 내 정보 조각을 나타내는 단위를 의미합니다. LLM에서의 단어 토큰이 문장의 기본 단위이듯, 이미지를 작은 패치로 나누어 표현한 한 조각 한 조각이 비전 토큰입니다. 1024×1024 해상도의 문서 이미지를 16×16 크기 패치로 쪼개면 약 4096개의 비전 토큰으로 표현할 수 있지요. DeepSeek-OCR 모델은 특별한 설계를 통해 이 비전 토큰의 수를 크게 줄였는데요. 어떤 구조를 차용했을까요?
이번 모델은 두 부분으로 구성된 시각-언어 모델(VLM)입니다. 앞부분은 이미지를 인코딩하여 비전 토큰 시퀀스로 변환하는 시각 인코더이고, 뒷부분은 이 비전 토큰을 받아 다시 텍스트를 디코딩하는 언어 모델이지요. 전체적으로 하나의 구조로 작동하며, 이미지 입력을 받아 최종 텍스트 출력까지 직접 산출합니다.
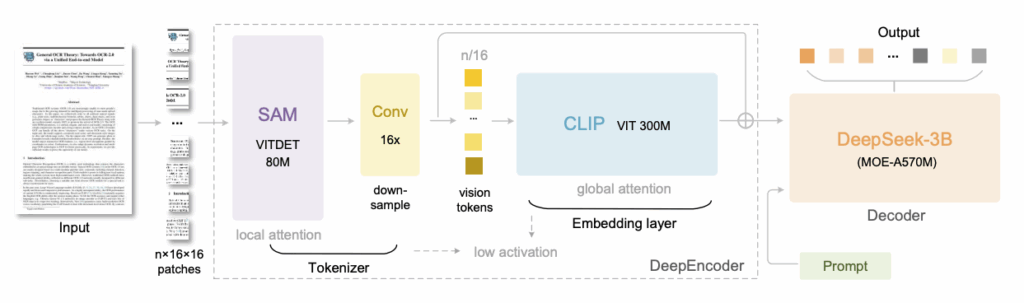
DeepSeek-OCR의 구조. 출처: 딥시크
DeepEncoder (딥 인코더)
딥 인코더는 고해상도 이미지를 효율적으로 처리하면서 적은 수의 토큰으로 압축된 표현을 뽑아내도록 설계되었습니다. 내부는 크게 아래 세 단계로 이루어집니다:
- 세밀히 본다
메타의 Segment Anything Model(SAM)의 비전 트랜스포머 기반 모듈을 활용합니다. 입력 이미지를 작은 단위로 나누어 세밀한 특징을 포착합니다. - 효율적으로 줄인다
비전 토큰의 개수를 16분의 1로 다운샘플링합니다. 앞선 토큰이 4096개였다면, 이 과정을 거치면 256개 수준으로 압축되겠지요? - 정보를 합쳐 이해한다
오픈AI의 CLIP 모델에서 사용하는 비전 트랜스포머를 응용합니다. 앞에서 압축된 토큰들을 전체적으로 한 번 더 확인하며 이미지 전반의 맥락과 의미를 파악합니다.
위 세 단계 연결 구조를 통해 딥 인코더는 고해상도 입력에서도 활성화 메모리 사용을 억제하고, 출력 토큰 수를 최소화할 수 있었습니다.
MoE 디코더
DeepSeek-OCR에는 DeepSeek-3B-MoE라는 Mixture-of-Experts (MoE) 구조의 언어 모델 디코더가 자리하고 있습니다. 이름에서 알 수 있듯이 약 30억 개의 파라미터를 가진 모델인데요. MoE란 여러 개의 전문가 모델이 모여있는 형태로, 각 토큰을 처리할 때 모든 전문가를 다 쓰는 대신 입력에 따라 일부 전문가만 활성화하는 방식입니다. 덕분에 모델 규모를 키우면서도 계산 효율을 높일 수 있지요.
MoE 디코더는 비전 인코더가 압축해 낸 정보를 텍스트로 풀어내는 역할을 하는데요. 딥 인코더가 만들어낸 적은 수의 비전 토큰을 입력으로 받아, 그 안에 담긴 내용을 차례대로 문자로 생성해냅니다. 마치 사람이 눈으로 문서를 보고 머릿속에서 글로 해석해내는 과정과 비슷하지요? 게다가 이 디코더는 언어 모델이기 때문에, 필요한 경우 프롬프트를 추가로 받아서 원하는 형식으로 출력할 수도 있습니다.
딥시크-OCR 성능
이제, 실험 결과를 살펴볼 차례입니다. 이번 모델이 자랑하는 대표적인 장점을 볼까요?
시각 압축률에 따른 OCR 정확도
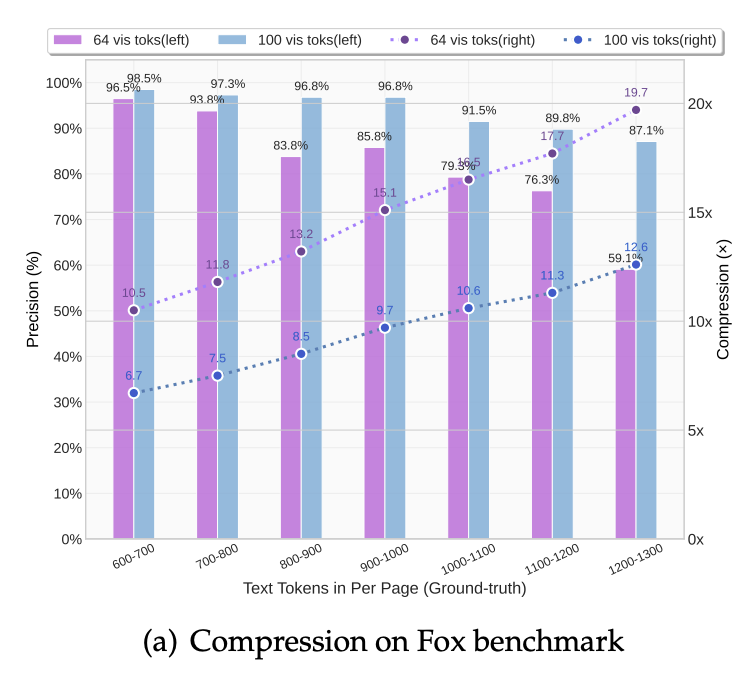
앞서 설명했듯이, DeepSeek-OCR 모델은 긴 텍스트를 대폭 압축된 이미지 토큰만으로 복원해냅니다. 압축률이란 텍스트 토큰 수 대비 비전 토큰 수 비율을 의미하는데요. Fox 벤치마크 결과, 압축률이 약 9~10배일 때 96% 이상의 정확도를 보였고, 10~12배 구간에서도 약 90% 내외를 유지했습니다. 극단적으로 약 20배 가까이 압축했을 때에도 정확도가 60% 수준으로 남아 있어, 정보 손실이 있더라도 의미 있는 복원이 가능함을 보여주었지요.
실제 문서 이해 성능
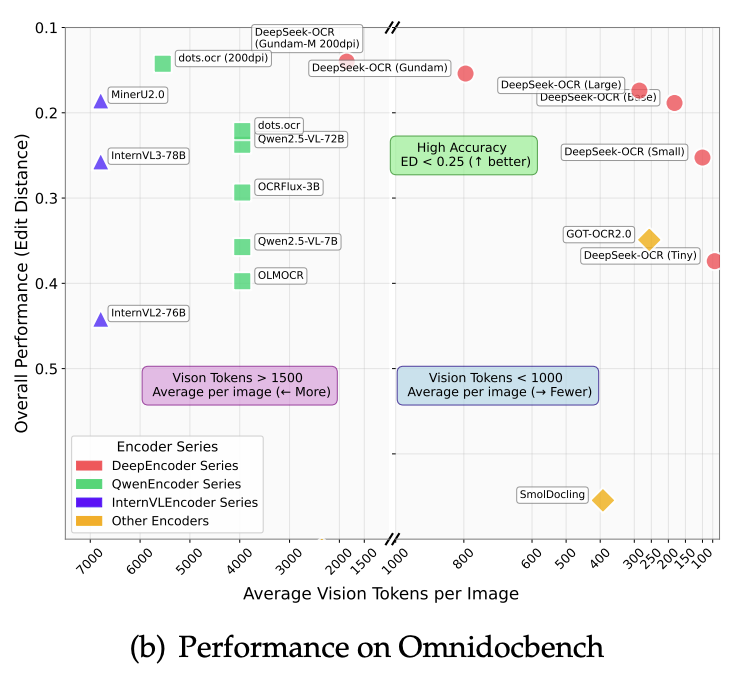
연구진은 OmniDocBench라는 복합 문서 이해 벤치마크 또한 사용했는데요. DeepSeek-OCR 모델은 최신 경쟁 모델들을 능가했습니다. 훨씬 적은 토큰으로도 동일한 작업을 해냈지요. 예를 들어, 기존 모델인 GOT-OCR 2.0은 한 페이지를 처리하는 데 256개의 텍스트 토큰을 사용한 반면, DeepSeek-OCR은 100개의 비전 토큰만으로도 GOT-OCR 2.0의 성능을 앞질렀습니다.
또 다른 최신 모델 MinerU 2.0은 페이지당 평균 6000개가 넘는 토큰을 활용하는데요. DeepSeek-OCR은 800개 미만의 비전 토큰으로 이 모델보다도 우수한 결과를 달성했습니다. 이는 실용적인 관점에서 큰 의미가 있습니다. 토큰 수가 적다는 것은 곧 추론 속도가 빠르고 메모리 부담이 낮다는 뜻이므로, 동일한 하드웨어로 더 많은 문서를 처리하거나 더 긴 문맥을 다룰 수 있기 때문입니다.
범용적 인식 능력
DeepSeek-OCR은 단순한 글자 읽기뿐만 아니라 표, 차트, 수식, 이미지 내 객체 등 다양한 요소에 대한 파싱 능력을 갖추고 있습니다. 과학 논문의 PDF를 투입하면 본문 텍스트뿐 아니라 그래프 안의 숫자, 화학 구조식의 문자까지 인식해낼 수 있고, 영수증 사진을 넣으면 상표 로고나 도장에 쓰인 글자까지 함께 판독하는 식이지요.

금융 리포트 내 차트를 구조적으로 파싱한 DeepSeek-OCR의 예시. 출처: 딥시크
인간과 비슷한 점이 있다고?
지금까지는 텍스트 요약이나 추론을 통해 문맥을 압축했다면, DeepSeek-OCR는 모달리티를 전환해 압축하는 새로운 방법을 택했습니다. 작은 모델로도 10배 이상의 문맥 압축이 무리 없이 가능하다면, 추후 더 큰 LLM에서는 또 어떤 결과를 가져올지 기대가 되는데요. GPT-5 같은 대형 모델이 대화 기록을 처리할 때 일정 기간이 지난 대화들은 이미지로 압축하여 토큰을 아끼고, 최신 대화만 텍스트로 유지한다면 훨씬 오래전 문맥까지 참고하면서도 계산량은 효율적으로 통제할 수 있겠죠?
연구진은 LLM도 오래된 정보를 점차 압축하여 경제적인 표현으로 바꾸면 일종의 '망각'을 구현할 수 있다고 말합니다. 마치 인간의 기억 메커니즘과 유사하다고 주장하는데요. 지난 대화 내용을 이미지로 렌더링한 뒤 해상도를 점점 낮춰 토큰 수를 줄이는 모습이, 마치 최근 내용은 선명하게 두고 과거 내용은 희미하게 줄여가는 인간 두뇌와 유사하다는 설명입니다.
문제를 해결하기 위해서는 틀을 깨야한다고 하지요. 문맥 처리 해결을 텍스트에 국한하지 않고, 이미지를 통해 바라보니 새로운 가능성이 보입니다. 숨어있는 또 다른 가능성들이 궁금해지는 연구입니다.


