
최근 메타 AI 연구진을 중심으로, AI와 뇌 신호 해독에 관한 흥미로운 연구가 공개됐습니다. 논문 제목은 Accurate Decoding of Natural Sentences from Non-Invasive Brain Recordings로, 직역하면 '비침습적 뇌 기록으로부터 자연스러운 문장을 정확하게 해독하기' 정도가 될 텐데요. 연구진은 이 시스템을 Brain2Qwerty v2라고 부릅니다.
비침습적(인체에 직접적인 상처를 내거나 기구를 체내에 삽입하지 않는 방식) 뇌 기록만으로 자연문장을 정확하게 복원했다는 건, 정확히 어떤 의미일까요?
연구의 실체를 알아보자
이번 연구는 사람이 가만히 앉아 머릿속으로 아무 문장이나 떠올렸고, AI가 그 생각을 읽어낸 연구가 아닙니다.
참가자들은 먼저 문장을 듣고, 잠시 기다린 뒤, 그 문장을 실제 키보드로 타이핑했습니다. 연구진은 이 타이핑 과정에서 발생하는 뇌 활동을 MEG, 즉 뇌의 자기장을 측정하는 장비로 기록했지요. 그리고 모델은 그 MEG 신호만을 입력으로 받아 참가자가 타이핑한 문장을 복원하려 했습니다. 그러니까 이 연구를 정확히 표현하면, '생각을 자유롭게 읽은 연구'라기 보다는 '문장을 기억하고 타이핑하는 동안의 뇌 신호를 텍스트로 디코딩한 연구'에 가깝습니다. 그렇다면 이 Brain2Qwerty v2는 어떤 점에서 특별할까요?
지금까지 높은 성능을 보인 Brain-Computer Interface, 즉 BCI 연구는 대체로 뇌에 전극을 삽입하는 침습형 방식에 의존해왔습니다. 침습형 방식은 성능은 좋지만, 수술이 필요하고 장기적인 안정성이나 확장성 면에서 한계가 있습니다. 반면 Brain2Qwerty v2는 두개골 밖에서 측정한 비침습 뇌 신호만으로 자연문장 복원의 가능성을 보여줬는데요. 바로 이 차이가 중요합니다. 뇌에 전극을 심지 않고도 사람이 생성하려는 언어를 어느 정도 복원할 수 있다면, 장기적으로는 말을 하거나 움직이기 어려운 사람들을 위한 더 안전한 의사소통 기술로 이어질 수 있기 때문이지요.
비침습 Brain-to-Text, 무엇이 어려울까?
BCI의 가장 중요한 목표 중 하나는 말을 하거나 움직이기 어려운 사람이 뇌 신호만으로 의사소통할 수 있게 하는 것입니다. 루게릭병이나 뇌손상 등으로 발화나 운동 능력이 제한된 사람에게는 뇌 신호를 텍스트로 바꾸는 기술이 삶의 질을 크게 바꿀 수 있는데요. 문제는 뇌 신호의 품질입니다.
침습형 BCI는 뇌 안쪽 또는 뇌 표면에 전극을 삽입하기 때문에 비교적 선명한 신호를 얻을 수 있습니다. 최근 침습형 BCI 연구들은 사용자가 말하려 하거나, 손글씨를 쓰려 하거나, 타이핑하려는 신호를 상당히 높은 정확도로 복원하는 결과를 보여줬습니다. 하지만 침습형 방식은 말 그대로 수술이 필요합니다. 또 의료적 위험이 있고, 전극이 장기간 안정적으로 작동해야 하며, 많은 환자에게 널리 적용하기도 어렵지요.
때문에 EEG(뇌파검사), fMRI, MEG처럼 몸 안에 기구를 넣지 않고 뇌 활동을 측정하는 비침습형 방식도 주목받고 있는데요. 비침습 신호는 대체로 약하고 노이즈가 많습니다. 뇌파검사는 신호대잡음비가 낮고, fMRI는 시간 해상도가 느립니다. MEG는 뇌에서 활동이 일어나는 순간순간의 변화를 비교적 빠르게 잡아낼 수 있다는 장점이 있습니다. 하지만 장비가 크고 비싸서 병원 밖이나 일상 환경에서 쓰기 어렵지요. 이때, 연구진은 이런 질문을 던집니다:
비침습 MEG 신호를 충분히 많이 모으고,
최신 딥러닝과 LLM을 잘 결합하면 자연문장 수준의 brain-to-text decoding이 가능할까?
실험은 어떻게 진행됐을까?
연구진은 건강한 성인 9명을 대상으로 실험했습니다. 각 참가자는 약 10시간 동안 MEG 기록에 참여했고, 전체적으로 약 22,000개의 문장이 수집됐습니다. 참가자들은 문장을 헤드폰으로 듣고, 잠시 기다린 다음, 그 문장을 키보드로 타이핑했는데요. 이 설정에는 두 가지 특징이 있습니다.
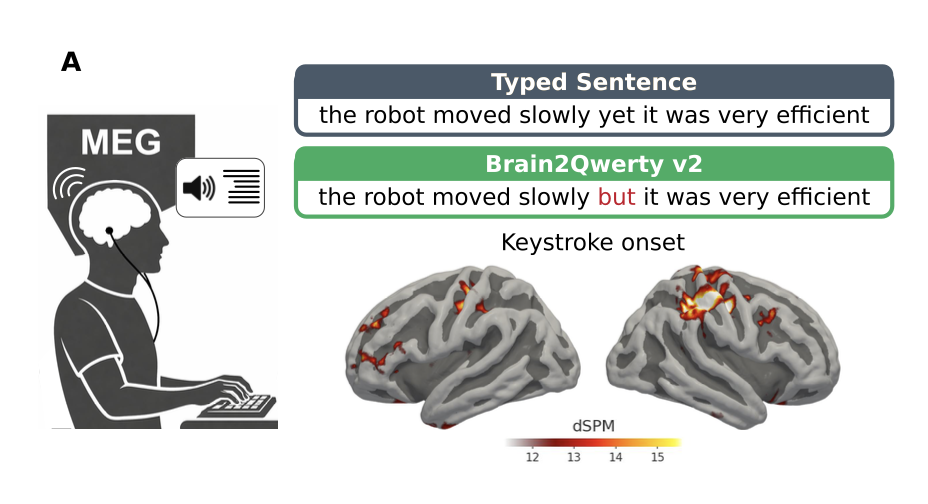
실험 개요. 참가자들은 들은 문장을 기억한 뒤 키보드로 타이핑했고, 연구진은 이때의 MEG 신호를 기록했다. 오른쪽 뇌 지도는 키 입력 시점에 MEG가 주로 운동피질 활동을 포착했음을 보여준다. 출처: 논문.
먼저, 데이터 규모가 이전보다 훨씬 커졌습니다. 비침습 뇌 신호는 노이즈가 많기 때문에, 모델이 안정적인 패턴을 배우려면 충분한 양의 데이터가 필요한데요. 연구진은 참가자별로 약 10시간씩 데이터를 모았고, 논문에서는 데이터가 늘어날수록 디코딩 성능이 꾸준히 좋아졌다고 보고합니다.
또 다른 특징은 모델이 키 입력 시점을 미리 알고 분류한 것이 아니라는 점입니다. 이전 접근은 특정 키가 눌린 정확한 시점을 알고, 그 주변의 뇌 신호를 잘라 어떤 글자인지 맞히는 방식에 가까웠습니다. 하지만 실제 BCI 상황에서는 사용자가 키를 누를 수 없을 수 있습니다. 그러면 키 입력 시점 자체가 존재하지 않지요.
Brain2Qwerty v2는 이 문제를 해결하기 위해 연속적인 MEG 신호를 입력받고, 그 안에서 문장 전체를 복원하는 방향으로 접근했습니다. 이를 위해 Connectionist Temporal Classification(CTC)이라는 기법을 사용했는데요. CTC는 음성인식에서도 자주 쓰이는 방식으로, 긴 시계열 신호와 짧은 텍스트 출력 사이의 정렬을 모델이 스스로 학습할 수 있게 해줍니다.
쉽게 말하면, 모델은 '이 순간이 정확히 어떤 글자에 해당한다'라는 정보를 매번 받지 않아도 됩니다. 대신 전체 MEG 신호를 보고, 그 신호가 어떤 문자열과 가장 잘 맞는지 학습합니다.

가장 빠른 AI 뉴스
Brain2Qwerty v2, 어떻게 문장을 복원했을까?
Brain2Qwerty v2의 구조는 크게 세 단계로 나뉩니다. 간단히 살펴볼까요?
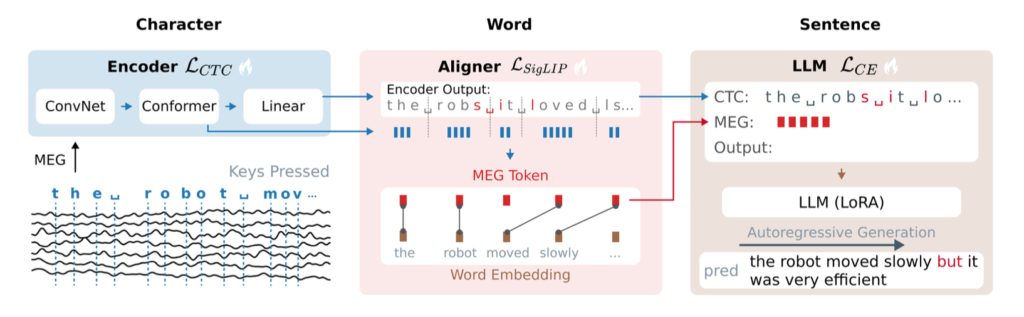
Brain2Qwerty v2 구조. 연속적인 MEG 신호를 Encoder가 글자 수준 표현으로 바꾸고, Aligner가 이를 단어 의미 공간에 맞춘 뒤, LLM이 최종 문장을 생성한다. 출처: 논문.
1. 먼저 Encoder가 MEG 신호에서 글자 수준 정보를 뽑습니다. 타이핑 중인 뇌 활동에서 어떤 문자들이 나왔을 가능성이 높은지 예측하는 역할이지요.
2. 그다음, Aligner가 등장해 뇌 신호에서 나온 표현을 단어 의미 공간과 맞춥니다. 다시 말해, MEG 신호에서 추출한 표현이 정답 단어의 임베딩과 가까워지도록 학습합니다. 여기서 모델은 단순히 글자 조각만 보는 것이 아니라, 단어 수준의 의미 정보도 활용하려고 합니다.
3. 마지막으로 LLM이 최종 문장을 생성합니다. LLM은 Encoder가 만든 글자 후보와 MEG에서 추출된 단어 수준 표현을 함께 입력받습니다. 그리고 이를 바탕으로 가장 그럴듯한 문장을 생성합니다.
Brain2Qwerty v2에서 LLM은 단순한 문법 교정기가 아닙니다. 깨진 텍스트를 받아 자연스럽게 고쳐 쓰는 후처리 모델이 아니라, MEG에서 온 신호 표현까지 함께 입력받는 멀티모달 디코더에 가깝지요. Brain2Qwerty v2는 끊임없이 이어지는 뇌 신호를 LLM이 이해할 수 있는 토큰과 비슷한 형태의 표현으로 바꾸고, 여기에 언어 모델이 이미 학습해둔 언어적 패턴을 결합했다는 점이 강점입니다. 이번 연구는 BCI 연구이면서 동시에, 센서로 측정한 신호를 언어로 바꾸는 AI 시스템의 한 사례로도 볼 수 있습니다.
결과는 어땠을까?
Brain2Qwerty v2는 전체 참가자 평균 WER 39%를 기록했습니다. WER는 정답 문장과 예측 문장이 단어 단위에서 얼마나 다른지를 나타내는 오류율인데요. 가장 성능이 좋았던 참가자에서는 이 수치가 22%까지 내려갔습니다. 다만 이 결과를 과하게 해석할 수는 없습니다. WER 39%는 '문장의 61%를 완벽히 맞혔다'는 의미가 아니기 때문이지요. 이는 단어가 빠지거나, 다른 단어로 바뀌거나, 불필요한 단어가 들어간 정도를 계산한 값입니다. 따라서 여전히 오류는 적지 않습니다.
그럼에도 비침습 MEG 신호만으로 자연문장을 복원하는 일이 얼마나 어려운지 생각하면, 의미있는 결과로 볼 수 있습니다. 특히 Brain2Qwerty v2는 단순히 글자 후보를 뽑는 Encoder나, 그 결과를 N-gram 언어모델로 보정한 방식보다 단어 수준과 의미 수준에서 더 나은 결과를 냈습니다!💡
물론, 좋은 점만 있지는 않습니다. LLM은 자연스럽고 그럴듯한 문장을 만드는 데 강하기 때문에 뇌 신호가 충분히 선명할 때는 깨진 문자 조각을 의미있는 문장으로 복원하는 데 도움이 됩니다. 하지만 반대로 신호가 애매할 때는, 문장은 매끄럽지만 실제 사용자가 입력하려던 내용과는 전혀 다른 결과를 만들 수 있는데요. 논문에서도 이런 경향이 나타납니다. Brain2Qwerty v2는 단어 단위나 의미 단위로 봤을 때는 기존 방식보다 좋아졌지만, 글자 하나하나를 얼마나 정확히 맞혔는지를 보면 오히려 N-gram 방식보다 나빴습니다.
사실 이는 LLM을 써본 사람이라면 익숙한 문제일 텐데요. LLM은 확실하지 않을 때도 그럴듯한 문장을 만들어내지요? 일상적인 대화에서는 어느 정도 의미가 맞는 문장이 도움이 될 수 있겠지만, BCI에서는 다릅니다. 약 이름, 숫자, 비밀번호, '예/아니오'처럼 정확성이 중요한 표현에서는 그럴듯한 문장보다 글자 단위의 정확성이 훨씬 중요하기 때문이지요.
Brain2Qwerty v2는 비침습 MEG 기반 자연문장 복원에서 의미 있는 진전을 보여줬으나, 아직 실제 의사소통 장치로 보기에는 오류가 많습니다. 또, LLM 특유의 '유창하지만 틀린 문장' 문제도 해결해야 합니다.
Brain2Qwerty v2는 brain-to-text 연구가 LLM 시대에 어떤 방향으로 발전할 수 있는지를 보여줍니다. 복잡한 생체 신호를 언어로 바꾸는 AI 시스템의 예시라고도 볼 수 있는데요. 아직 실험실 연구에 가깝고 실제 의사소통 장치가 되기까지는 넘어야 할 단계가 많지만, BCI와 LLM이 만나는 방향은 조금씩 선명해지고 있습니다. AI는 이제 텍스트와 이미지를 넘어, 인간의 신체 신호와 의사소통 방식까지 다루기 시작했습니다. 인공지능과 인간지능의 관계도 새롭고 복잡해지고 있습니다.


