
피지컬 AI에 대한 기대가 커지면서 뛰어난 멀티모달 모델에 대한 연구 또한 활발해지고 있습니다. 지금까지는 주로 성능이 좋은 LLM에 이미지 이해나 생성 기능을 붙이는 방식으로 멀티모달 AI를 만들어왔는데요.
최근 메타(Meta)와 뉴욕대학교(New York University) 연구진은 텍스트와 시각을 처음부터 함께 학습하는 멀티모달 사전학습 방식에 대한 연구 결과를 공개했습니다. 연구진은 멀티모달 모델을 기존처럼 LLM에 기능을 덧붙이는 방식으로 만들기보다, 처음부터 텍스트와 시각을 함께 학습시키는 것이 더 강한 시너지를 낼 수 있다고 주장하는데요. 그렇다면 과연 어떤 시각 표현이 좋은지, 어떤 데이터를 섞어야 하는지, 또 어떤 학습 구조가 멀티모달에 특히 잘 맞는지 하나씩 살펴보겠습니다.
연구 방식을 살펴보자
텍스트와 시각을 처음부터 함께 학습한 멀티모달 모델은 실제로 어떤 효과를 낼까요?
사실 모델 구조는 비교적 단순합니다. 하나의 모델이 언어와 시각 정보를 모두 처리하며, 텍스트는 일반적인 LLM처럼 다음 단어를 예측하는 방식으로 학습되지요. 반면 이미지와 비디오는 노이즈가 섞인 상태에서 장면을 점차 복원하도록 학습됩니다. 즉, 하나의 모델이 텍스트를 이해하고 생성하는 능력과, 이미지를 이해하고 만들어내는 능력을 같은 구조 안에서 동시에 익히는 방식입니다.

멀티모달 사전학습에 사용된 데이터 유형 예시. 출처: 논문.
대표적인 기본 모델은 총 2.3B 파라미터 규모이며, 토큰당 약 1.5B 파라미터가 실제로 활성화되는 구조입니다. 대표 실험에서는 520B 텍스트 토큰과 520B 멀티모달 토큰을 사용해 총 약 1T 토큰 규모로 학습했지요. 이렇게 대규모 텍스트와 시각 데이터를 함께 학습했을 때 어떤 결과가 나타났을까요?
1. 이미지 이해와 생성을 하나로!
멀티모달 모델에서 의외로 까다로운 문제 중 하나는 이미지를 이해하는 데 좋은 표현(representation)과 생성하는 데 좋은 표현이 꼭 같지 않다는 점입니다. 기존에는 이미지 이해를 위해 Semantic Encoder를 사용하고, 생성을 위해서는 VAE Latent나 별도의 생성형 토큰을 개별적으로 사용하는 경우가 많았는데요. 이렇게 서로 다른 두 체계를 혼용하면 모델 구조가 파편화되고 전체 시스템의 연산 효율도 떨어지게 됩니다.
여기서 연구진은 이미지 정보를 압축해서 표현하는 모델인 RAE(Representation Autoencoder)를 해법으로 제시합니다. 여러 시각 표현을 비교한 결과, RAE 기반 표현이 이미지 이해와 생성 양쪽에서 가장 좋은 균형을 보였기 때문이지요. 쉽게 말해, 하나의 시각 표현만으로도 이미지를 잘 이해하는 능력과 이미지를 잘 만들어내는 능력을 동시에 뒷받침할 수 있다는 뜻입니다. 기존에는 이해와 생성을 위해 서로 다른 표현 체계를 별도로 운영해야 했지만, 이번 연구는 하나의 시각 표현(RAE)이 두 영역을 모두 커버할 수 있다는 가능성을 보여줍니다.
2. 시각 데이터는 언어 성능을 해치지 않아
혹시 LLM에 이미지나 비디오를 많이 넣으면 언어 성능이 떨어지는 건 아닐까?
멀티모달 학습을 두고 업계에서 종종 하는 걱정입니다. 서로 다른 종류의 데이터가 오히려 학습을 방해하지 않을까 하는 우려이지요. 이에 대해 연구진은 먼저 비디오 같은 시각 데이터가 언어 성능을 거의 해치지 않으며, 경우에 따라서는 텍스트만 학습한 모델과 비슷하거나 더 좋은 언어 성능을 보일 수 있다고 설명합니다.
연구진은 이미지 데이터가 추가됐을 때 언어 성능이 실제로 얼마나 유지되는지를 확인했는데요. 아래 그래프를 함께 살펴볼까요?
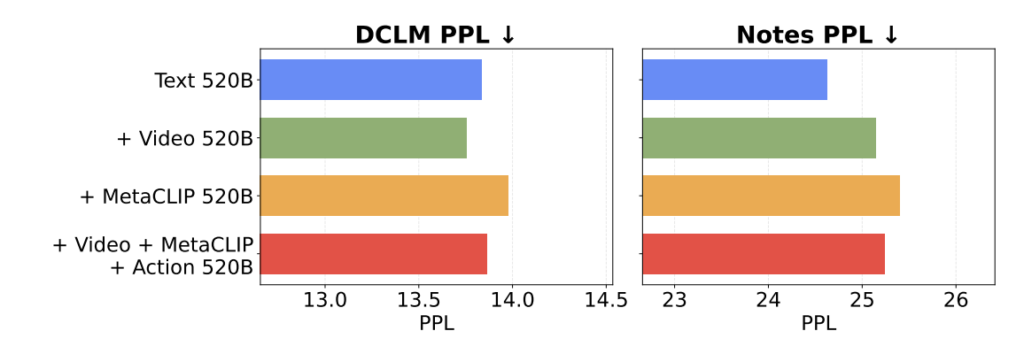
텍스트만 학습한 모델과 텍스트+비디오 모델의 언어 성능(PPL)을 비교한 결과. 출처: 논문.
그래프 속 PPL(perplexity)은 언어 모델이 다음 단어를 얼마나 잘 예측하는지를 나타내는 지표로, 숫자가 낮을수록 성능이 좋습니다. 파란 막대는 텍스트만 학습한 경우이고, 초록 막대는 여기에 비디오 데이터를 함께 넣은 경우인데요. 초록 막대로 표시된 텍스트 + 비디오 조합의 모델이, 파란 막대로 표시된 텍스트만 학습한 모델보다 더 낮은 PPL을 기록한 모습이 보이지요? 이는 시각 데이터가 언어 모델링과 충돌하지 않으며, 경우에 따라 도움이 될 가능성도 있음을 시사합니다.
물론 이미지-텍스트 쌍(MetaCLIP) 데이터가 포함된 경우인 노란 막대와 빨간 막대를 보면, 언어 성능이 미세하게 밀려나는 경향을 보이기도 합니다. 하지만 이는 시각 정보 자체 때문이 아니라, 이미지 캡션 특유의 말투나 문장 구조가 일반적인 학습 텍스트 분포와 차이가 있기 때문에 발생하는 현상이라고 연구진은 분석합니다. 시각 데이터 자체보다는 데이터의 분포와 목적이 중요하다는 결론이지요.

가장 빠른 AI 뉴스
3. 텍스트와 시각 데이터, 시너지를 낸다고?
연구진은 텍스트와 시각 데이터가 단순히 공존하는 것을 넘어, 실질적으로 서로의 학습을 돕는다고 주장합니다. 데이터 규모를 조절하며 실험한 결과, 동일한 시각 데이터 예산에서도 텍스트 데이터를 더 많이 투입할수록 이미지 생성 품질(GenEval 등)이 뚜렷하게 개선되었다고 하는데요. 풍부한 언어 정보가 시각적 세계를 더 정교하게 그려내도록 가이드 역할을 해준 셈입니다.
상호 보완 효과는 시각 이해 영역에서도 똑같이 나타났는데요. 특정 작업(VQA) 전용 데이터만 무작정 늘리는 것보다, 일반적인 텍스트나 멀티모달 데이터를 적절히 섞는 편이 성능 향상에 훨씬 효과적이었습니다. VQA 데이터만 1,000억 개 학습시킨 모델보다, VQA 데이터 200억 개에 텍스트 800억 개를 섞어 학습시킨 모델의 점수가 더 높게 나타났지요.
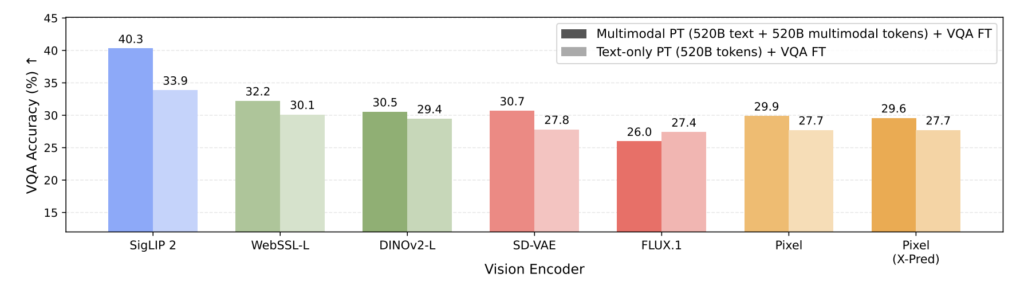
멀티모달 사전학습의 VQA 성능 비교 그래프. 출처: 논문.
위 그래프를 살펴볼까요? 동일한 조건에서 파인튜닝을 하더라도, 사전에 멀티모달 데이터를 골고루 학습한 모델(진한 막대)은 텍스트만 공부했던 모델(연한 막대)보다 거의 모든 설정에서 성적이 좋습니다. 특히 SigLIP 2 설정에서는 멀티모달 사전학습 모델이 40.3%를 기록했는데요. 같은 설정에서 텍스트만 사전학습한 모델은 27.8%에 그쳤습니다. 거의 1.5배에 가까운 차이가 나지요!
4. 멀티모달 학습, 월드 모델로 이어질까?
이번 연구는 단순한 멀티모달 연구를 뛰어넘습니다. 모델이 단순히 이미지를 보고 그리는 수준을 넘어, 특정 행동에 따라 세상이 어떻게 변할지 예측하는 ‘월드 모델’ 능력을 갖출 수 있는지까지 탐구했기 때문인데요. 연구진은 이를 위해 내비게이션 환경에서 과거 장면 프레임들과 하나의 행동을 입력으로 주고, 그 결과로 나타날 다음 장면을 예측하는 실험을 수행했습니다.
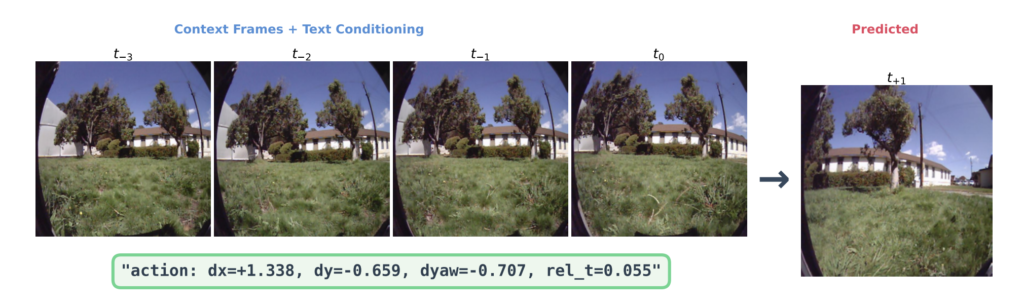
텍스트 토큰으로 인코딩된 내비게이션 행동. 출처: 논문.
연구진은 별도의 특수한 벡터를 설계하는 대신, 이동 방향이나 회전값 같은 액션 정보를 숫자 문자열 형태의 텍스트 토큰으로 입력했습니다. 예를 들어 “action: dx=…, dy=…, dyaw=…, rel_t=…” 같은 형식이지요. 위 이미지에서 볼 수 있듯, 4장의 과거 장면(Context Frames) 뒤에 이러한 행동 문자열을 덧붙이면 모델이 그 결과로 나타날 다음 장면(Predicted)을 생성하는 방식입니다. 덕분에 모델은 별도의 구조 변경 없이도 이미지와 텍스트를 동시에 처리하며 자연스럽게 다음 시각 상태를 예측할 수 있습니다.
또한 연구진은 전용 내비게이션 데이터만 무작정 늘리는 것보다, 일반 비디오나 멀티모달 데이터를 함께 섞어 학습했을 때 예측 성능이 훨씬 우수하다는 점을 포착했는데요. 특히 전체 학습량은 유지한 채 도메인 데이터의 비중만 조절해 본 결과, 단 1% 수준의 데이터만으로도 다음 상태를 예측하는 ‘월드 모델링’ 성능이 거의 정점에 도달하는 모습도 확인됐습니다.
5. 멀티모달에 특히 잘 맞는 MoE 구조
이번 연구에서는 Mixture of Experts(MoE) 구조도 함께 탐구했습니다. 기본 모델은 2.3B 총 파라미터 / 1.5B 활성 파라미터 규모이지만, MoE 실험에서는 13.5B 총 파라미터이면서도 토큰당 활성 파라미터는 여전히 약 1.5B 수준인 모델도 사용했습니다. 즉 전체 모델 용량은 크게 늘리면서도 실제 계산량은 크게 증가시키지 않는 구조이지요. 이러한 방식은 텍스트와 시각 데이터처럼 서로 다른 스케일링 특성을 가진 데이터를 더 유연하게 처리하는 데 도움이 됩니다.
멀티모달 학습에서는 텍스트와 시각 데이터의 정보 밀도나 학습 요구량이 서로 다릅니다. 텍스트와 시각이 같은 방식으로 스케일링되지 않기 때문인데요. 논문에 따르면, 시각은 언어보다 훨씬 더 많은 데이터를 필요로 합니다. 하지만 MoE는 전체 모델 용량은 크게 가져가되, 입력마다 일부 expert만 활성화하기 때문에 서로 다른 요구를 가진 언어와 시각을 더 유연하게 처리할 수 있습니다. 덕분에 모델의 전체 용량은 크게 늘리면서도, 실제 계산에 사용되는 파라미터 수는 제한된 수준으로 유지할 수 있습니다.
물론 이것만으로 완벽한 범용 월드 모델이 완성되었다고 단정할 수는 없습니다. 하지만 물리적 세계를 이해하고 예측하는 능력이 반드시 특수하게 설계된 구조에서만 나오는 것이 아님을 확인할 수 있었는데요. 마치 아기가 세상을 보고 들으며 배우듯, 인공지능도 텍스트와 시각 정보를 동시에 익히는 방식을 통해 스스로 세상의 원리를 깨우칠 수 있다는 새로운 가능성이 열렸습니다.


