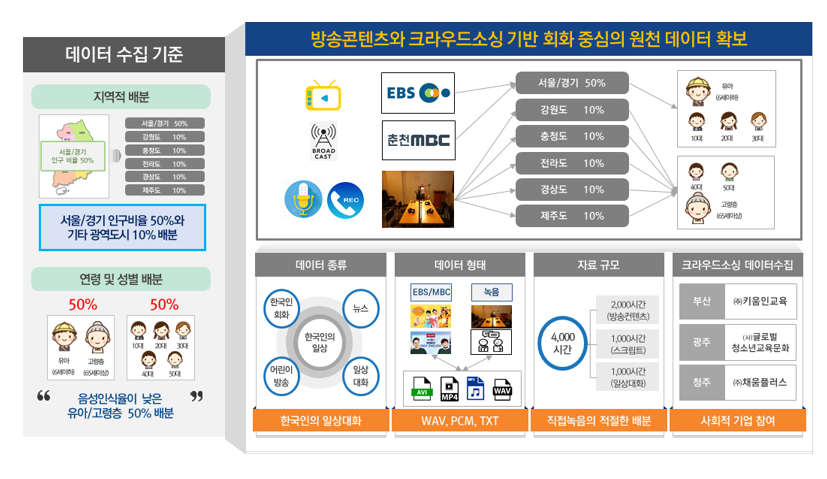
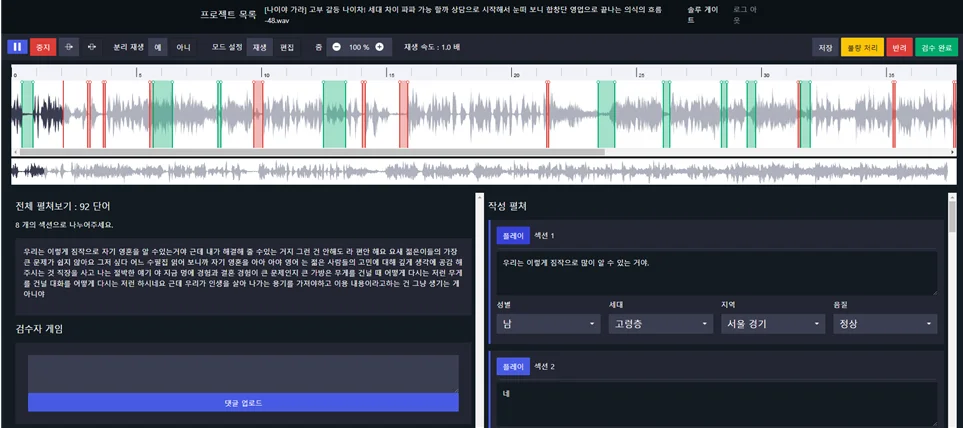
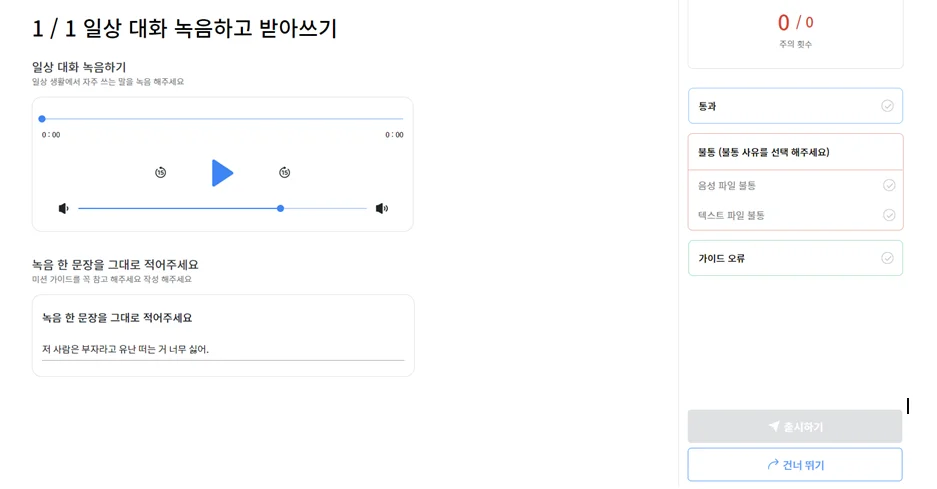
주요 키워드
AI학습데이터, 일상대화, 음성데이터, 어노테이션, 메타데이터, 라벨링
분야
한국어
유형
오디오, 텍스트