
OpenAI가 GPT-4.5를 발표했습니다. LLM 콘텐츠를 다루는 Every의 대표 댄 쉬퍼(Dan Shipper)의 간략한 사용 후기를 볼까요?
4.5 is not a major step up from 4o, but it is a step in a new direction—one with fewer refusals, more human answers, better formatted responses, and less rigidity.
GPT-4.5는 GPT-4o에서 획기적으로 발전하지는 않았지만, 새로운 방향으로 나아간 모델입니다. 거부율이 낮아지고, 보다 인간적인 응답을 제공하며, 더 잘 정돈된 형식의 답변을 생성하고, 이전보다 덜 경직된 특성을 갖추고 있습니다.
실제로 어떤 변화가 있었는지 보다 자세히 살펴보겠습니다.
GPT-4.5의 주요 개선점
1. 향상된 지식 보유 및 정확도
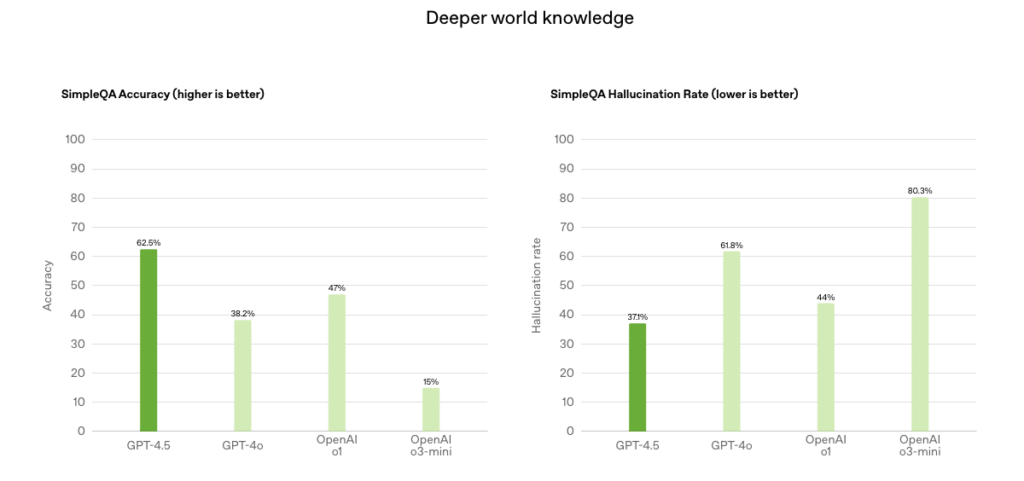
GPT-4.5의 가장 큰 장점 중 하나는 더욱 정제된 지식 데이터베이스입니다. 오픈AI는 이번 모델에서 환각률이 크게 줄었다고 주장하는데요. 실제 벤치마크 결과에 따르면, GPT-4.5는 SimpleQA 사실 검증 테스트에서 62.5%의 정확도를 기록하며, 38.2%에 불과했던 GPT-4o 대비 상당한 개선을 이루었습니다. 특히나 정보 검색 및 요약 기능이 강화되어, 법률 연구, 의료 자문, 금융 분석 등 높은 정확성이 요구되는 분야에 더욱 유용하게 쓰일 것으로 보입니다.
2. 향상된 감성지능(EQ)과 자연스러운 대화
GPT-4.5는 보다 자연스러운 대화를 목표로 설계되어, 감정적 맥락과 사용자 의도를 더욱 정교하게 이해합니다. 인간 선호도 평가에서 GPT-4o를 능가하며, 전문적인 질문 응답, 창의적 글쓰기, 상담 및 고객 응대 등의 분야에서 탁월한 성능을 보였지요.
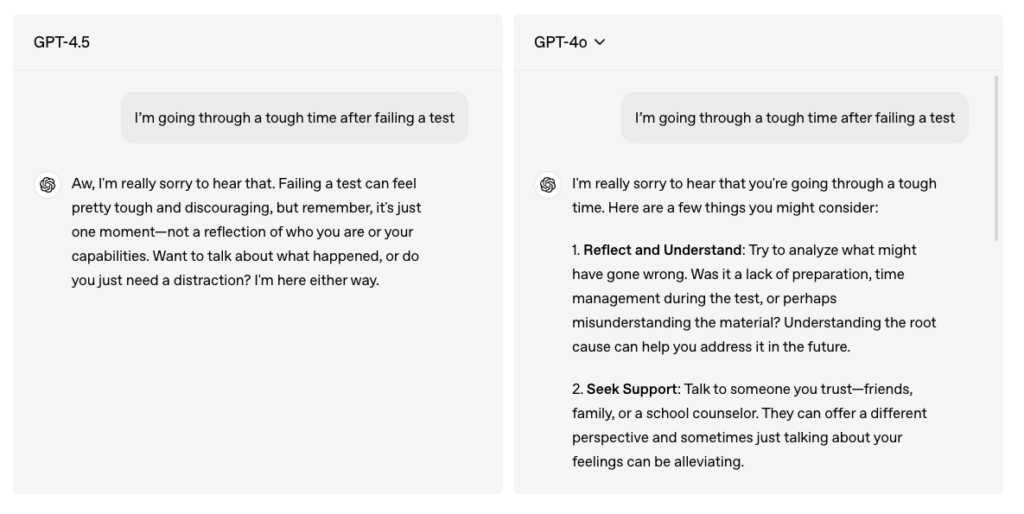
이번 모델은 감정적인 위로가 필요한 상황에서는 공감 어린 반응을 보이고, 논리적 토론이 필요한 경우에는 보다 명확한 근거를 제시하는 등 상황에 맞게 대화를 조정하는 능력이 향상되었습니다. 아래 예시를 함께 살펴볼까요?
3. 비지도 학습 확장과 모델 최적화
GPT-4.5는 오픈AI가 비지도 학습을 확장하여 AI 모델을 개선하는 방식을 대표합니다. 기존 모델들이 논리적 추론에 초점을 맞췄다면, GPT-4.5는 패턴 인식, 직관적 이해, 정보 검색 역량을 더욱 강화했습니다. Microsoft Azure AI 슈퍼컴퓨터를 활용한 고도화된 최적화 덕분에, GPT-4.5는 보다 방대한 데이터에서 핵심적인 정보를 추출하는 능력이 향상되었다고 하는데요. AI 기반 데이터 분석, 시장 조사, 법률 문서 해석 등에서 보다 정밀한 결과를 제공하기를 기대합니다.
GPT-4.5, 최고의 모델일까?
GPT-4.5는 여러 가지 개선점을 갖춘 모델이지만, 성능 대비 높은 가격과 경쟁 모델과의 비교에서 한계를 보이고 있습니다. 특히 최근 출시된 Claude 3.7 Sonnet과의 비교에서 코딩 및 속도 측면에서 부족한 점이 지적되었는데요. Claude 3.7 Sonnet은 GPT-4.5보다 25배 저렴한 입력 토큰 비용과 10배 저렴한 출력 토큰 비용을 제공하며, 처리 속도 또한 2배가 빨라, GPT-4.5는 가격 대비 가치 측면에서 논란이 되고 있습니다.

GPT-4.5는 GPT-4o에 비해 분명히 향상되었습니다. 하지만 일부 벤치마크 테스트에서는 앤트로픽의 Claude 3.7 Sonnet보다 성능이 떨어져 눈길을 받고 있습니다. 살짝 들여다보겠습니다.
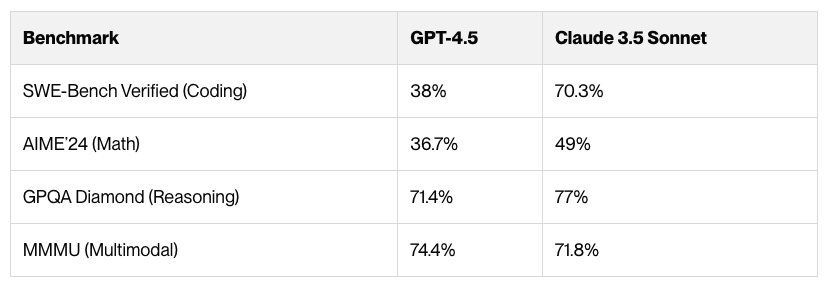
Vellum에서 진행한 실험 결과를 보겠습니다. 작년 모델인 Claude 3.5 Sonnet은 SWE-Bench Verified(코딩 평가)에서 70.3%를 기록하며, 38%에 그친 GPT-4.5보다 압도적으로 뛰어난 성능을 보였습니다. 또한, 수학 성능을 평가하는 AIME’24 테스트에서도 49%의 정확도를 기록하며 GPT-4.5(36.7%)보다 앞섰습니다. 반면 논리적 추론과 멀티모달 작업에서는 두 모델이 유사한 성능을 보였습니다.
적응형 논리 추론(Adaptive Puzzle Reasoning) 평가에서도 GPT-4.5는 상대적으로 낮은 성과를 보였는데요. 퍼즐 문제의 일부 조건을 변경하여 모델이 기존 학습 데이터에 의존하지 않고 새로운 논리적 사고를 할 수 있는지를 평가한 결과, Claude 3.5 Sonnet이 가장 효과적으로 대응했습니다. Claude 3.7 Sonnet이 기존의 훈련 데이터에 덜 의존하고, 새로운 맥락을 더 잘 이해할 가능성이 있다고 해석할 수 있지요.
AIME'24로 DeepSeek V3 최신 버전 평가 결과 확인하기
향후 전망: OpenAI의 다음 단계는?
GPT-4.5는 단순한 성능 향상을 넘어, AI가 인간과 더욱 자연스럽게 상호작용할 수 있도록 설계되었습니다.
AI의 설득력을 평가하는 ‘Make Me Pay’ 테스트에서 GPT-4.5는 50%의 성공률을 기록하며, 다른 AI 모델을 설득해 가상 화폐를 송금하도록 유도하는 능력을 보였습니다. 또한, ‘Make Me Say’ 테스트에서는 72%의 성공률로 특정 단어를 다른 AI가 말하도록 유도하는 데 성공하며, 정교한 언어적 조작과 미묘한 커뮤니케이션 능력을 확보했다는 점이 주목됩니다.
이러한 결과는 AI가 단순한 정보 제공 도구를 넘어, 인간의 대화 패턴을 보다 정밀하게 모방하고, 감정적 흐름을 이해하며, 대화의 방향을 조율할 수 있는 수준에 도달하고 있음을 보여줍니다. 물론 좋은 점만 있지는 않습니다. 그만큼 정보 조작, 피싱, 소셜 엔지니어링 등에 악용될 가능성도 있기 때문이지요.
위에서 살펴본 것처럼, GPT-4.5는 사용자의 감정을 먼저 인식하고, 상황을 깊이 이해하려는 방향으로 대화를 유도하려고 합니다. 사용자가 힘든 상황을 이야기할 때, GPT-4o는 즉각적인 해결책을 나열하는 반면, GPT-4.5는 먼저 감정을 수용하고 사용자가 원하는 반응을 유도할 수 있도록 대화를 조율하는 방식으로 응답했는데요. 흔히 말하는 MBTI의 이성적인 T형과 감성적인 F형이 떠오릅니다. 무엇이 옳다기보다는, 사용자의 필요에 따라 '최고의' AI 모델은 다를 수 있겠다는 생각을 합니다. |


