
Benchmark

Benchmark
200개 이상 기업 및 기관과 구축한 1억 3000만 데이터. 축적한 기술과 인프라로 모든 유형의 데이터셋을 구축합니다.



초거대 언어 모델
신뢰성 벤치마크 데이터
본 사업은 AI 학습용 데이터 구축 지원 사업의 일환으로, 3H 기준에 따라 인공지능의 성능을 정량적으로 수치화합니다.
안전하고 똑똑한 초거대 언어 모델(LLM)을 위한 신뢰성 평가 데이터셋.
셀렉트스타가 국내 대표 AI 기업과 함께 한국어 언어 모델의 신뢰성을 평가합니다.
*3H: 도움되고, 진실하며 무해한 인공지능 개발을 위한 지표(Helpful, Honesty, Harmlessness)

LLM 파인튜닝, 셀렉트스타와 함께하세요
셀렉트스타와 파운데이션 모델을 조정하세요. 보유한 데이터를 고품질 AI 학습 데이터로, 목적 기능에 최적화된 생성 모델을 구현합니다. 데이터 기획 수집 가공 선별 분석까지.
LG CNS ‘KorQuAD2.0’
: 한국어 기계 독해의 표준
한국어 질문-답변 KorQuad Dataset 2.0은 카카오, 네이버 등 주요 기업들의 기계독해 AI 모델 성능의 척도가 되는 데이터셋입니다.
리더보드: https://korquad.github.io/

KorQuAD 2.0는 LG CNS AI빅데이터연구소에서 구축한 한국어 기계 독해 이해 데이터셋 입니다.
셀렉트스타는 크라우드 소싱 플랫폼 캐시미션을 통해, 10만 쌍 규모 고난도 한국어 질의응답 데이터를 수집 및 가공했습니다.
크라우드소싱 예시
질문-답변 생성

문서 수집
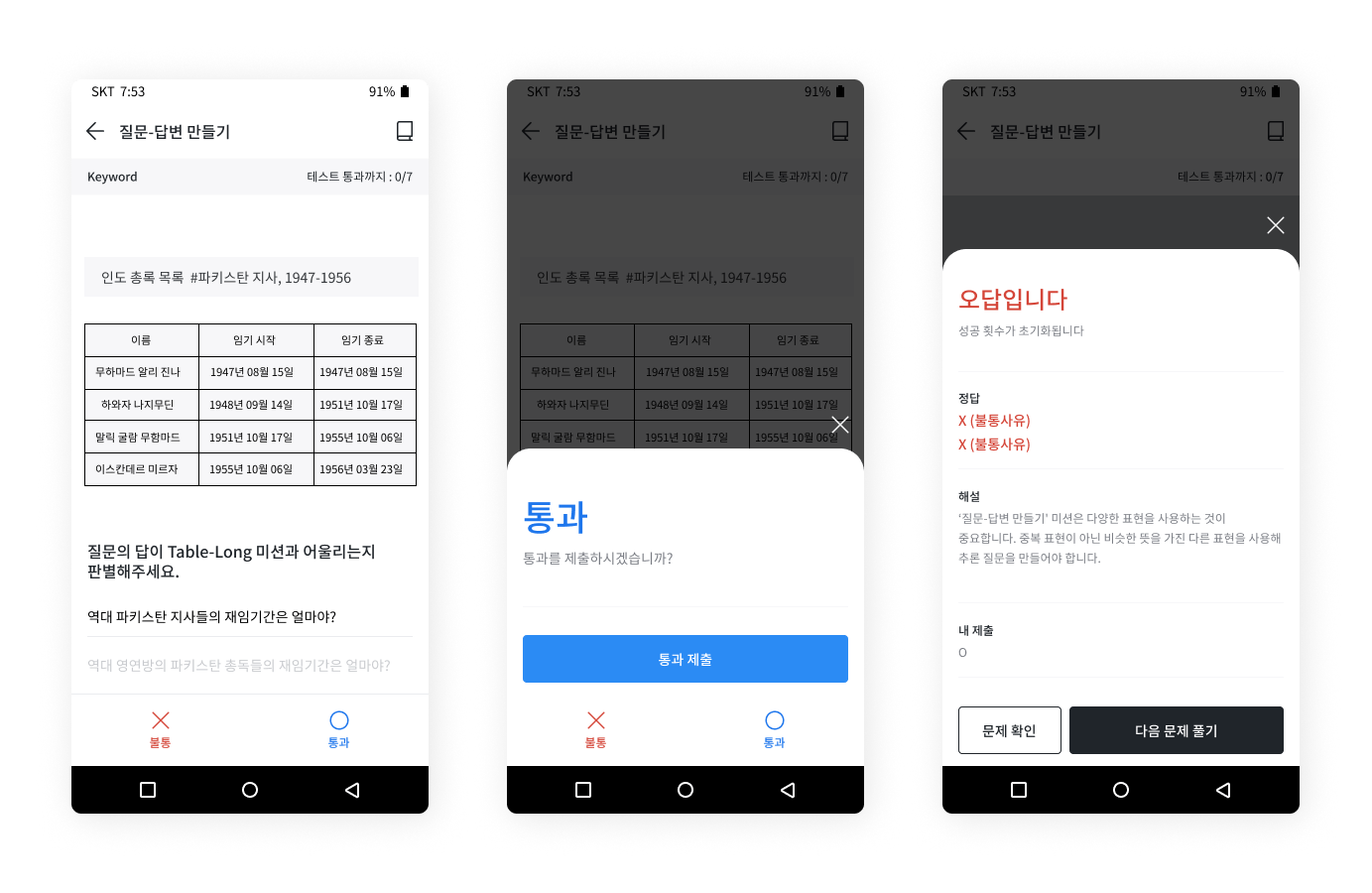
자사의 크라우드 소싱 플랫폼 ‘캐시미션’을 활용하여 작업 실시
KLUE: 한국어 대표 벤치마크 데이터셋
Korean Language Understanding Evaluation Benchmark
논문 https://arxiv.org/abs/2105.09680
KLUE는 한국어 기반 AI 모델의 공정한 평가를 위한 ‘한국어 자연어 이해 평가 데이터셋(Korean Language Understanding Evaluation Benchmark) 입니다.
업스테이지와 KAIST, NYU, 네이버, 구글 등 10여개 기관이 함께 구축했으며, 셀렉트스타는 크라우드 소싱을 통해 약 37만 건의 자연어 데이터를 수집 및 가공했습니다.
크라우드소싱 예시 및 샘플 데이터
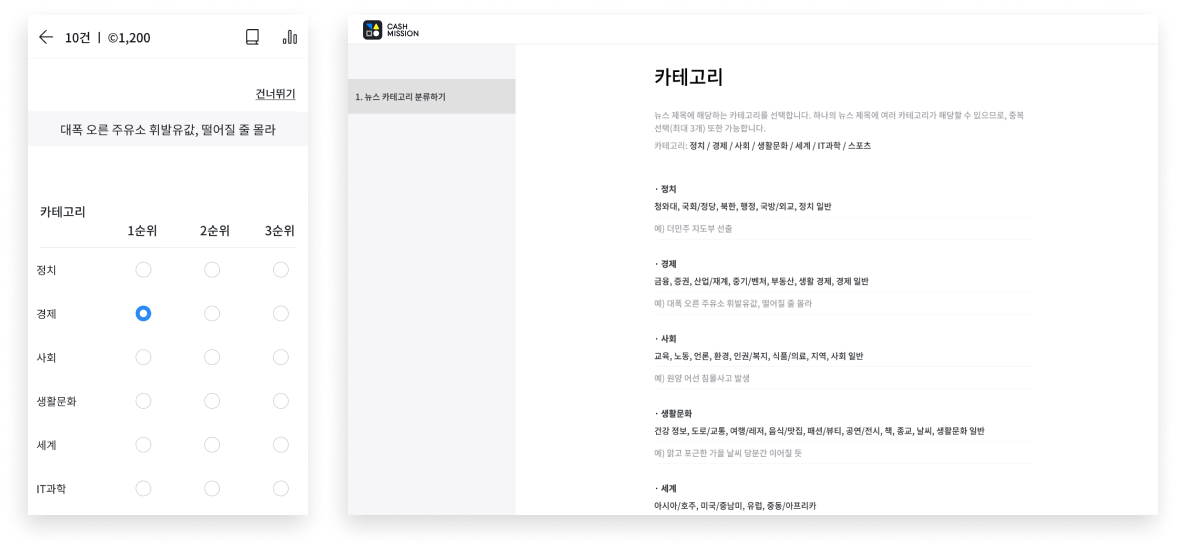
좌) '캐시미션(앱)'에서 ‘뉴스 카테고리 분류하기’ 수집, 가공 작업 진행 화면 / 우) '캐시미션(웹)'에서 전문 가이드 팀이 작성한 크라우드 유저들의 미션 이해를 돕기 위한 가이드_ ‘뉴스 카테고리 분류하기’
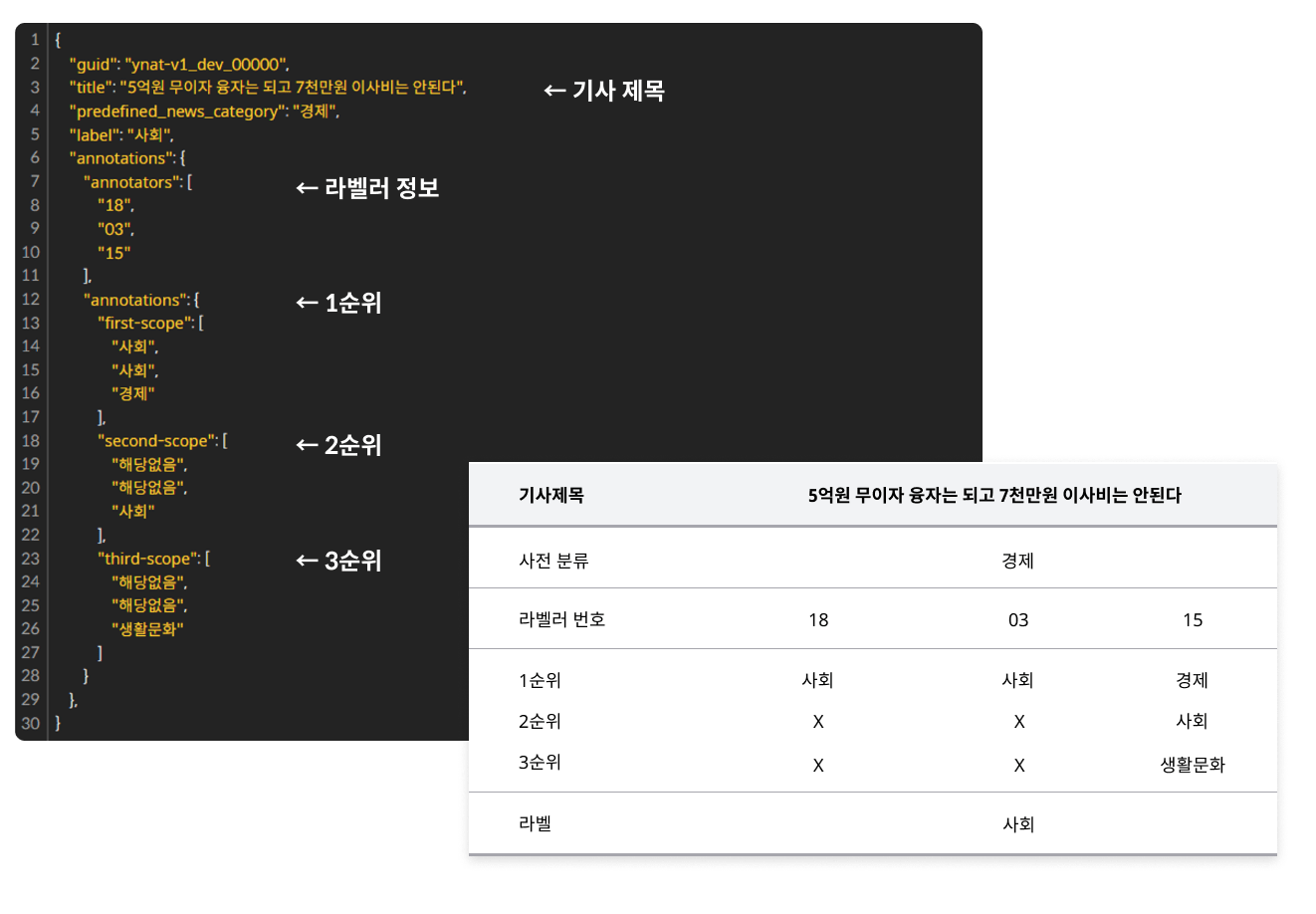
KLUE 샘플 데이터(JSON)