
어마어마한 규모의 도서관에 들어섰다고 상상해 볼까요? 책이 끝없이 늘어서 있는 이곳에서 “기술 산업의 주요 트렌드는 무엇인가요?”라고 묻습니다. 이때 도서관 사서가 관련된 책을 찾는 데 그치지 않고, 도서관에 존재하는 기술 산업과 관련된 모든 자료를 요약해 제공한다면 어떨까요? Graph RAG는 바로 이러한 혁신적인 “스마트 사서”와 같습니다.
Graph RAG는 기존의 RAG(Retrieval-Augmented Generation) 시스템을 한 단계 끌어올려 복잡한 질문에 답하고 대규모 데이터를 요약할 수 있도록 설계된 기술인데요. 단순한 정보 검색에서 벗어나, 데이터를 그래프 기반으로 조직화하고 커뮤니티 단위로 요약하여 질문의 맥락과 핵심을 정확히 파악합니다. 오늘은 Graph RAG의 작동 방식과 연구 성과, 그리고 실제 활용 가능성에 대해 살펴보겠습니다.
기존 RAG의 한계와 Graph RAG의 필요성
RAG는 질문에 대한 답을 생성하기 위해 관련 정보를 검색하고 이를 바탕으로 응답을 생성하는 시스템입니다. 단순한 질문(예: “2023년 노벨상 수상자는 누구인가요?”)에는 효과적이지만, “이 데이터셋의 주요 주제는 무엇인가요?”처럼 전반적인 맥락과 핵심을 요약해야 하는 질문에는 한계가 있지요.
이는 RAG가 데이터를 조각으로 처리하면서 전체적인 연결 관계를 놓치고, 대규모 데이터셋에서는 LLM(Large Language Model)의 처리 용량을 초과하기 때문인데요. Graph RAG는 이러한 한계를 해결하기 위해 데이터를 그래프 기반으로 재구성하고, 커뮤니티 단위로 요약하여 데이터를 더욱 효율적으로 처리합니다.
기존 RAG 방식은 어땠을까?
LLM을 활용한 RAG 최적화란?
Graph RAG의 작동 방식
Graph RAG는 데이터를 단순히 검색하는 데 그치지 않고, 이를 의미 있는 단위로 분할하고 조직화합니다. 단계를 좀더 들여다볼까요?

Graph-RAG의 작동방식.
1. 데이터 분할 (Source Documents → Text Chunks)
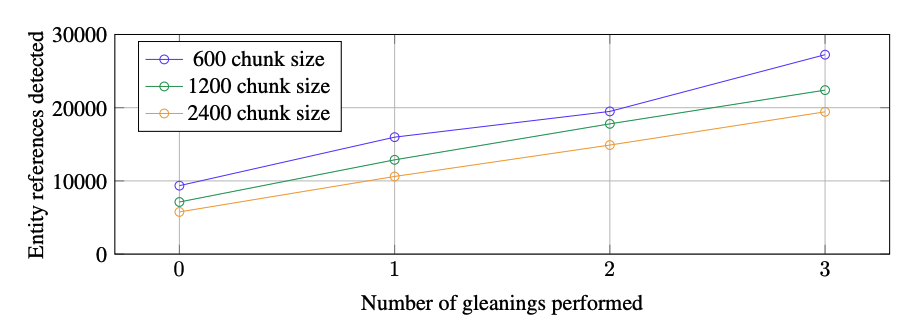
청크 크기에 따른 개체(entity) 추출양 비교.
2. 주요 요소 추출 (Text Chunks → Element Instances)
- 노드(node): 주요 개체(entity)를 의미하는, 독립적인 정보 단위 (예: 사람, 장소, 개념)
- 엣지(edge): 두 개체 간의 연결 관계(relationship) (예: “A는 B의 부분이다”)
3. 요소 요약 생성 (Element Instances → Element Summaries)
4. 그래프 생성 및 커뮤니티 구성 (Element Summaries → Graph Communities)
요약된 노드와 엣지는 그래프로 연결되는데요. 그래프는 노드(개체)와 엣지(관계)를 기반으로 하며, Leiden 알고리즘을 사용해 서로 연관된 노드 그룹(커뮤니티)을 형성합니다.
예를 들어, 뉴스 데이터에서는 “기후 변화” 커뮤니티가 “재생 가능 에너지”, “탄소 배출”, “정책 개혁”과 같은 관련 주제를 묶을 수 있는데요. 이렇게 커뮤니티를 계층적으로 구성하면 데이터의 복잡한 구조를 효율적으로 분석할 수 있겠지요?
5. 커뮤니티 요약 생성 (Graph Communities → Community Summaries)
Leiden 알고리즘을 통해 형성된 각 커뮤니티는 LLM을 통해 보고서 형식으로 요약하는 단계입니다. 각 요약은 커뮤니티 내 주요 노드와 엣지의 정보를 포함하는데요. 질문에 답변하기 위한 데이터 인덱스로서 유용할 뿐만 아니라, 질문이 없는 경우에도 데이터셋의 전체 구조와 의미를 이해하는 데 독립적으로 활용될 수 있지요.
커뮤니티 요약 생성 방법을 간단하게 살펴볼까요?
- 리프(Leaf)-레벨 커뮤니티:
가장 세부적인 커뮤니티의 요약은 개체(node), 개체 간의 관계(edge), 핵심적 부가정보(covariate)를 중요도에 따라 정렬한 뒤 LLM의 문맥 창(context window)에 추가합니다. - 상위 레벨 커뮤니티:
상위 커뮤니티는 리프 레벨과 동일한 방식으로 요약을 추가합니다. 문맥 창 제한을 초과할 경우, 하위 커뮤니티 요약을 짧은 텍스트로 대체하며 정보를 최대한 압축합니다.
6. 응답 생성 (Community Summaries → Community Answers → Global Answer)
Graph RAG 작동 예시
다시 도서관으로 들어가볼까요? “현재 기술 산업의 주요 트렌드는 무엇인가요?”라는 질문을 받은 LLM이 Graph RAG를 통해 답변을 준다고 가정해보겠습니다.

Photo taken by Guillaume Henrotte
커뮤니티 요약 생성:
- 데이터셋을 여러 커뮤니티로 나눈다.
- “AI 윤리” 커뮤니티는 “AI의 투명성”, “책임 있는 데이터 사용”과 같은 노드와 엣지를 포함하고 있을 수 있음
질문 처리:
- 질문이 들어오면, GraphRAG는 질문과 가장 관련 있는 커뮤니티 요약을 선택한다.
- “현재 기술 산업의 주요 트렌드는 무엇인가요?”라는 질문은 “AI 윤리”, “데이터 프라이버시”, “생성형 AI 응용”과 관련된 커뮤니티 요약을 참조함
최종 응답 구성:
- 각 관련 커뮤니티 요약을 기반으로, LLM이 개별 응답을 생성한다.
- AI 윤리 커뮤니티: “AI의 투명성과 책임 있는 데이터 사용이 중요하게 논의되고 있습니다.”
- 데이터 프라이버시 커뮤니티: “데이터 보호 규정이 강화되며, 사용자 개인정보의 안전한 관리를 위한 기술 개발이 활발합니다.”
- 생성형 AI 응용 커뮤니티: “생성형 AI는 콘텐츠 생성, 고객 서비스, 제품 디자인 등 다양한 산업에 응용되고 있습니다.”
- 이후 이 응답들을 결합하여 포괄적이고 정리된 최종 답변을 제공한다.
- “현재 기술 산업의 주요 트렌드는 AI 윤리, 데이터 프라이버시, 그리고 생성형 AI 응용입니다. AI의 투명성과 책임 있는 데이터 사용이 강조되며, 데이터 보호 규정이 강화되고 있습니다. 또한, 생성형 AI는 다양한 산업에서 응용 가능성을 확장하고 있습니다.”


