
대형 언어 모델(LLM)이 빠르게 발전함에 따라, 방대한 텍스트에서 관련 정보를 효율적으로 검색하는 것이 항상 큰 도전 과제로 남아 있습니다. 기존의 검색 방법은 작은 연속 텍스트 조각만 검색하는 경향이 있어 포괄적인 이해에 필요한 더 넓은 맥락을 놓치는 경우가 많습니다. Recursive Abstractive Processing for Tree-Organized Retrieval의 약자인 RAPTOR는 바로 이러한 문제를 해결하기 위해 고안된 새로운 재귀적 요약 기반 검색 방식입니다.
새로운 접근
RAPTOR는 스탠퍼드 대학의 연구팀이 제시한 방법으로, LLM이 복잡하고 긴 문서와 상호 작용하는 방식에 대해 연구했습니다. RAPTOR의 핵심은 텍스트 조각을 재귀적으로 요약하여 문서로부터 계층적 트리를 구성하는 것입니다.
그렇다면 재귀적인 요약이란 무엇일까요? 몹시 두꺼운 책을 ‘재귀적으로 요약’한다고 생각해보겠습니다. 먼저 각 장을 요약한 뒤, 이 장들의 요약을 모아서 책 전체의 요약을 만듭니다. 책의 세부 내용을 알고 싶을 때는 장별 요약을 보고, 책의 전체적인 내용을 알고 싶을 때는 마지막에 만든 책 전체 요약을 보면 되겠지요? 이처럼 재귀적 요약은 정보를 단계적으로 압축하는 방식입니다. 층층이 요약된 내용이 쌓이면서 트리 구조를 이룬다고 볼 수 있는데요. 이 트리 구조를 통해 모델은 질문에 따라 세부 정보와 주제별 개요를 모두 검색할 수 있습니다.
그 결과, RAPTOR는 긴 문서에서 다단계 추론을 요구하는 작업에서 더욱 뛰어난 성능을 발휘합니다. 예를 들어, RAPTOR는 긴 텍스트에서 여러 단계를 거쳐 답을 찾아야 하는 다단계 추론을 요구하는 테스트인 QuALITY 벤치마크에서 20%의 절대 정확도 향상을 달성하며, 복잡한 다단계 추론 작업에서 다른 모델들보다 훨씬 우수한 성능을 보여주었습니다. RAPTOR에 대해 좀더 자세히 알아볼까요?
RAPTOR의 두 가지 주요 검색 방법
RAPTOR의 핵심 검색 메커니즘은 두 가지 주요 방법으로 구성됩니다: Tree Traversal Retrieval과 Collapsed Tree Retrieval. 이 두 방식은 RAPTOR가 문서 내에서 정보를 효율적으로 찾기 위해 사용되며, 각 방식은 서로 다른 장점을 가지고 있습니다.
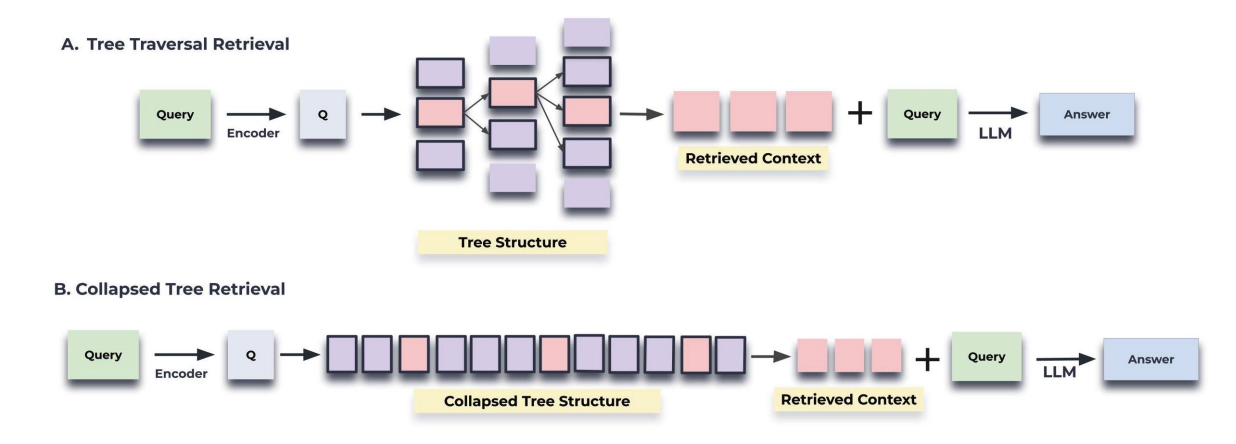
RAPTOR의 두 메커니즘. 출처: https://arxiv.org/pdf/2401.18059
1. Tree Traversal Retrieval
Tree Traversal Retrieval 방식은 RAPTOR가 생성한 계층적 트리 구조에서 루트에서 시작해 하위 레벨로 순차적으로 탐색하는 방법입니다. 이 방식은 쿼리와 루트 노드 간의 유사도를 계산하여 상위 개념을 먼저 평가한 후, 그 아래에 있는 자식 노드들을 하나씩 탐색하며 최종적으로 검색 결과를 제공합니다.
- 작동 방식: 루트에서 시작해 각 레이어에서 가장 유사한 노드를 선택하고, 점차적으로 하위 레벨로 내려가며 정보를 구체화합니다. 각 레이어에서 선택된 정보는 쿼리와 가장 관련성이 높은 정보입니다.
- 장점: 상위 개념에서 하위 세부 정보로 점진적으로 탐색하기 때문에, 문서의 큰 그림을 먼저 파악하고 세부 정보로 내려가는 방식에 적합합니다.
- 단점: 각 레이어를 순차적으로 탐색하므로, 쿼리가 요구하는 세부 정보와 상위 개념을 동시에 고려하기 어려울 수 있습니다.
2. Collapsed Tree Retrieval (트리 평면화 검색)
Collapsed Tree Retrieval 방식은 트리의 모든 레이어를 평면화하여 모든 노드를 한 번에 평가하는 방식입니다. 이 방법은 트리의 특정 레이어에만 의존하지 않고, 쿼리에 맞는 정보를 여러 레벨에서 동시에 추출할 수 있도록 도와줍니다.
- 작동 방식: RAPTOR가 생성한 트리를 평면화하여 모든 노드에 대해 코사인 유사도를 계산하고, 쿼리와 가장 유사한 노드들을 선택합니다. 선택된 노드들은 상위 개념과 세부 정보가 혼합된 형태로, 여러 레이어에서 정보를 한꺼번에 가져옵니다.
- 장점: 트리의 여러 레이어를 동시에 평가할 수 있기 때문에, 세부 정보와 상위 요약 정보를 유연하게 결합해 쿼리에 가장 적합한 결과를 제공합니다.
- 단점: 트리의 모든 노드를 평가해야 하므로, 연산 비용이 높을 수 있지만 RAPTOR는 FAISS와 같은 빠른 검색 라이브러리를 통해 이 문제를 해결하고 있습니다.
기존 방식과 뭐가 다를까?
기존 방식 중 top-k retrieval 방식은 쿼리와 가장 유사한 상위 k개의 텍스트를 단순히 선택하여 제공하는 방식입니다. 이 방식은 가장 유사한 텍스트를 빠르게 찾을 수 있지만, 정해진 범위 내에서만 정보를 선택하기 때문에 문서의 여러 레이어에 걸쳐 통합된 정보를 제공하는 데는 한계가 있지요. 반면, Collapsed Tree Retrieval은 트리의 모든 레이어에서 동시에 가장 유사한 정보를 찾아내므로, 더 복합적이고 유연한 검색 결과를 제공합니다.
RAPTOR의 collapsed tree retrieval 방식은 QASPER 데이터셋의 20개 스토리 실험에서 기존 top-k retrieval 방식을 일관되게 능가했습니다. 특히 최대 2,000개의 토큰을 검색하는 top-20 노드에서 최상의 성능을 기록했는데요. 세부 정보와 상위 요약 정보의 균형을 잘 맞춘 덕입니다. 이처럼 RAPTOR는 기존의 검색 시스템이 제공하지 못하는 다층적인 정보 통합과 효율적인 검색을 가능하게 합니다.
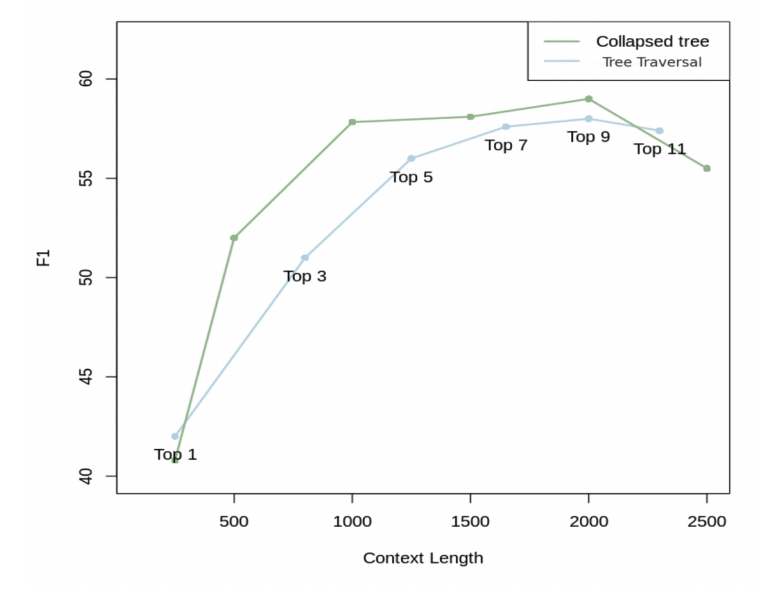
QASPER 데이터셋에서 다양한 top-k 트리 탐색과 Collapsed Tree Retrieval 방식 비교. 출처: https://arxiv.org/pdf/2401.18059
트리 기반 검색 시스템의 혁신
RAPTOR는 기존의 검색 시스템과 차별화되는 트리 기반의 검색 방식을 도입했습니다. 기존의 검색 방식은 텍스트를 작은 조각으로 나누고, 개별적으로 검색하는 데 그쳤지만, RAPTOR는 이 방식을 넘어섭니다. 먼저, SBERT 임베딩을 사용해 텍스트를 벡터화한 후, 가우시안 혼합 모델(GMM)을 통해 유사한 의미를 가진 텍스트들을 클러스터링(clustering)합니다.
RAPTOR의 핵심 혁신은 단순히 텍스트 조각에 의존하지 않고, 이러한 클러스터를 재귀적으로 요약하여 계층적 트리를 형성한다는 점입니다. 트리의 루트(root)에는 문서 전체를 요약한 상위 정보가 위치하고, 리프(leaf) 노드에는 더 세부적인 정보들이 담깁니다. 이렇게 다양한 레이어로 요약된 정보는 사용자 쿼리에 따라 세부 사항과 추상적 정보를 유연하게 탐색할 수 있도록 돕지요. 이 과정에서 RAPTOR는 문서 내에서 세부 사항과 넓은 주제를 동시에 파악할 수 있어, 정보 통합의 효율성을 크게 향상시킵니다.
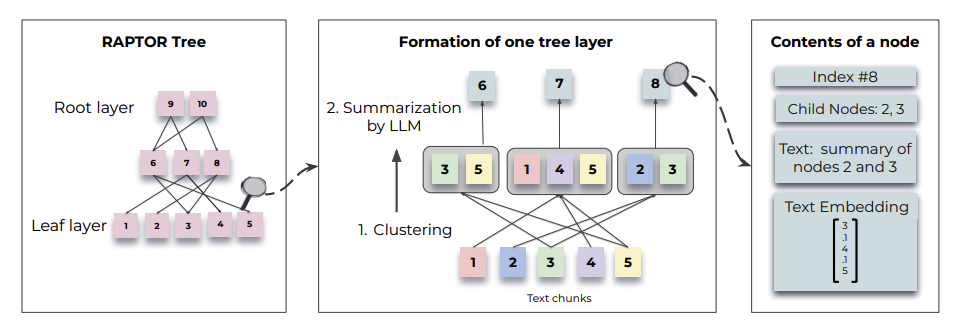
RAPTOR의 트리 구조. 출처: https://arxiv.org/pdf/2401.18059
이러한 트리 구조 덕분에 RAPTOR는 복잡한 문서를 처리하는 작업에서 뛰어난 성능을 발휘합니다. 특히 QASPER 데이터셋에서 RAPTOR는 정밀도와 재현율의 조화 평균을 나타내는 F1 점수에서 55.7%를 기록했으며, 이는 이전 최고 성능이었던 CoLT5의 53.9%를 뛰어넘는 수치입니다. RAPTOR가 과학 논문과 같은 복잡한 문서에서 세부 사항과 주제를 효과적으로 통합하여, 높은 정확도와 적은 오차로 필요한 정보를 찾아낼 수 있다는 결과지요.
이 연구가 중요한 이유는 무엇일까?
질문에 답하고, 문서를 요약하며, 보고서를 생성하는 작업에서 언어 모델은 점점 더 중심적인 역할을 하고 있습니다. 방대한 정보에서 관련 정보를 신속하고 정확하게 가져올 수 있어야 하지요. 그러나 기존의 검색 방법은 텍스트의 작은 조각만 제공하기 때문에 모델의 능력이 제한됩니다. 예를 들어, ‘신데렐라는 어떻게 해피엔딩으로 끝났나요?’라는 질문은 몇가지 문장이 아닌, 소설의 전체적인 맥락을 이해해야 답을 할 수 있습니다.
RAPTOR는 다양한 추상화 수준에서 요약된 정보를 검색하는 방법을 제공함으로써 이러한 문제를 해결하는데요. 세부적인 스니펫이 필요할 때도, 높은 수준의 개요가 필요할 때도 유연하게 대처할 수 있습니다. RAPTOR 방식을 사용하면, 어떤 정보 검색 방식과 결합하더라도 더 높은 성능을 기록할 수 있습니다. 아래 표를 함께 살펴볼까요?
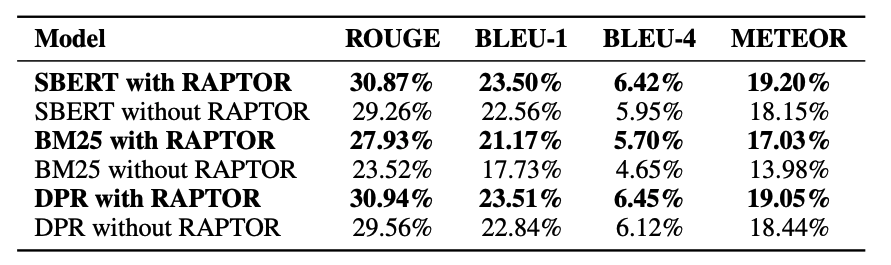
RAPTOR 사용 시 성능 비교. 출처: https://arxiv.org/pdf/2401.18059
NarrativeQA 데이터셋에서 RAPTOR와 결합된 SBERT, BM25, 그리고 DPR은 각각 단독으로 사용되었을 때보다 더 높은 ROUGE-L 성능을 보여주었습니다. 특히, BM25와 RAPTOR가 결합된 경우 23.52%에서 27.93%로 성능이 향상되었고, DPR와 RAPTOR를 결합하면 30.94%로 가장 높은 성능을 기록했습니다. 이는 RAPTOR가 다양한 검색 방법과 결합했을 때 검색 정확도를 일관되게 향상시킨다는 점을 명확히 보여줍니다.
마치며
RAPTOR의 도입은 검색 증강 언어 모델의 새로운 도약을 의미합니다. RAPTOR의 재귀적 요약 방식과 트리 기반 검색 시스템은 복잡한 문서를 보다 효과적으로 통합할 수 있게 하여, LLM이 질문 응답, 문서 요약 및 문서 분석 작업을 전에 없던 정밀도와 효율성으로 수행할 수 있도록 합니다.
여러 벤치마크에서 새로운 성능 기준을 세운 RAPTOR는 효율성과 정확성의 균형을 맞추며, 검색 증강 모델이 단순한 정보 수집기가 아니라 종합적인 지식 통합자로 발전할 수 있는 길을 열었습니다.


