기존의 AI 모델들은 긴 글을 읽을 때 정보를 압축해서 고정된 벡터에 구겨 넣으려 했습니다. 그러다 보니 디테일이 뭉개지기 일쑤였지요. 하지만 Titans는 다릅니다. Titans는 정보를 단순히 저장하는 게 아니라, ‘추론 시점 암기(Test-Time Memorization)’라는 기술을 통해 실시간으로 학습합니다.
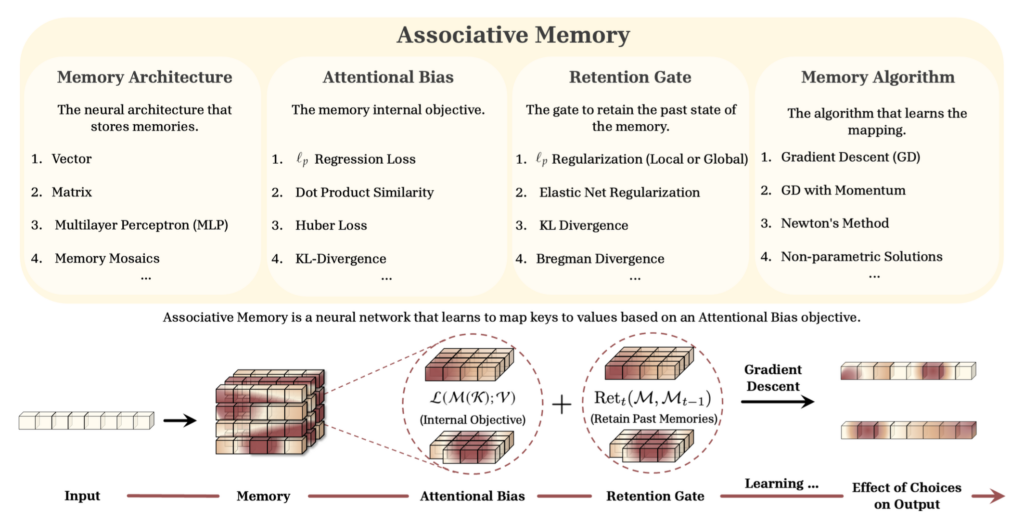
매일 반복되는 일상은 쉽게 잊히지만, 출근길에 마주친 코끼리는 평생 기억하겠지요. Titans도 이 원리를 이용합니다. AI가 다음 내용을 예측했을 때 뻔한 내용이라면 과감히 흘려보내지만, 예측이 빗나간 ‘놀라운(Surprise)’ 정보가 나타나면 즉시 장기 기억 신경망을 업데이트하는데요. 모델은 예측 오차에 대한 손실 함수를 계산해 정보의 중요도를 판단합니다. 이후 기존의 단순한 행렬 메모리 대신, 다층 퍼셉트론(MLP)으로 구성된 깊은 신경망을 사용하여 복잡한 맥락을 비선형적으로 압축하고 저장합니다.
Titans의 기억 시스템을 알아보자
Titans는 인간의 뇌처럼 서로 다른 역할을 하는 세 가지 기억 시스템을 동시에 가동하여 효율성을 극대화합니다. 함께 살펴볼까요?
- Core(단기 기억): 지금 당장 읽고 있는 문장을 처리하는 집중력입니다. 주로 어텐션 메커니즘이 이 역할을 맡아 현재의 정보를 정밀하게 분석합니다.
- Long-term Memory(장기 기억): 과거의 방대한 맥락을 압축해 둔 심층 신경망입니다. 위에서 설명한 '놀라움'을 통해 실시간으로 업데이트되는 Titans의 핵심 엔진입니다.
- Persistent Memory(영구 기억): 태스크 수행에 필요한 문법 지식이나 상식처럼, 입력 데이터와 상관없이 고정되어 있는 지식입니다.
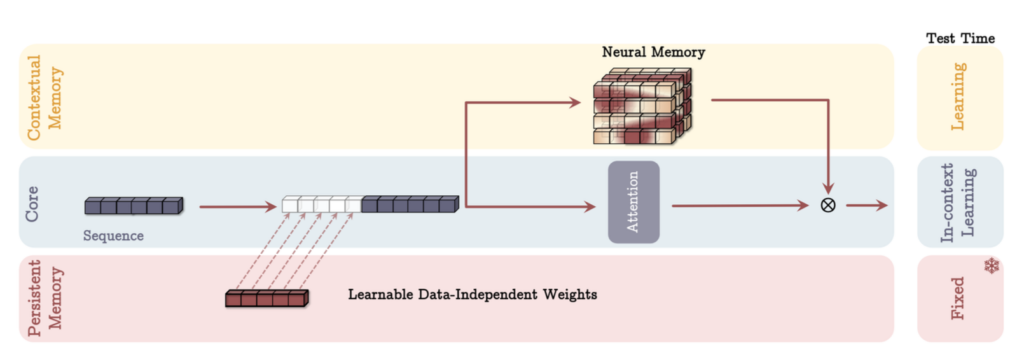
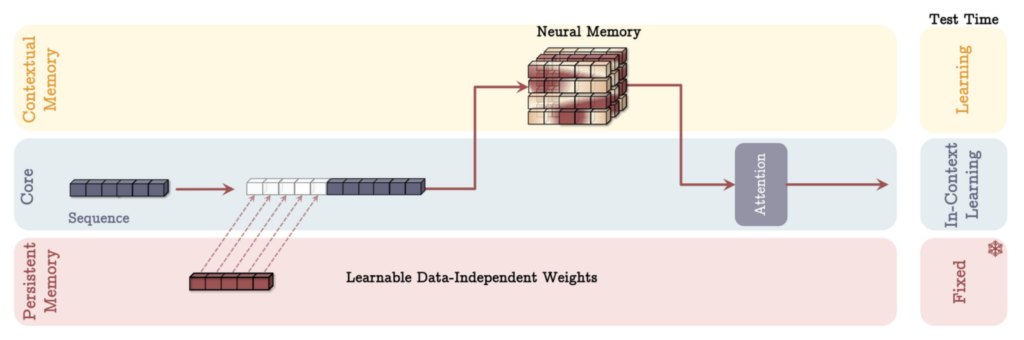
위 세 가지 기억 시스템은 어떻게 조립하느냐에 따라 각각 조금씩 다른 특징을 보이는데요. 간단하게 알아보겠습니다.
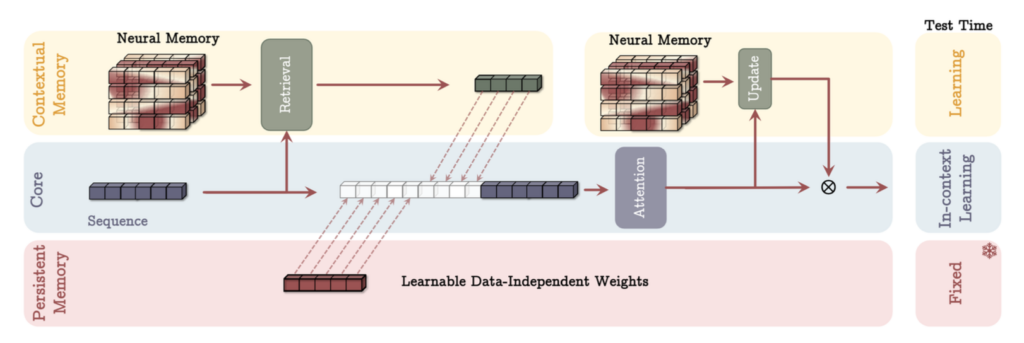
- MAC (Memory as Context)
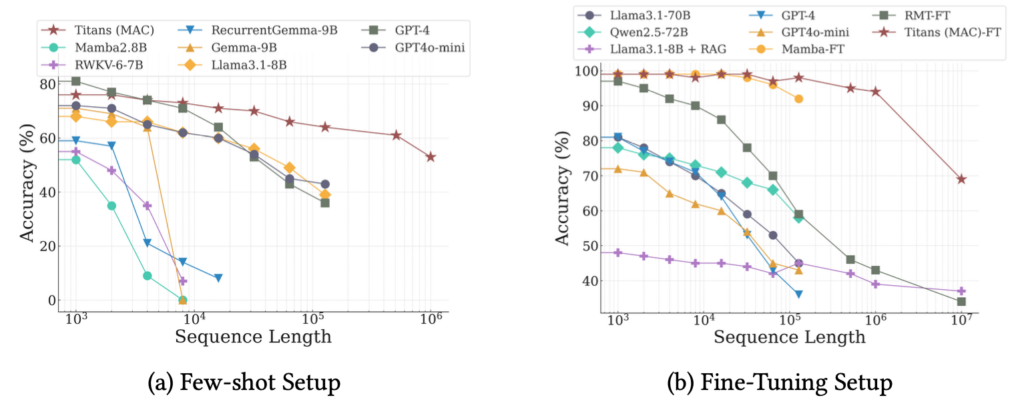
과거의 방대한 기억을 압축해서 현재 문맥의 앞에 붙여줍니다. 마치 시험 볼 때 '핵심 요약 노트'를 옆에 두고 문제를 푸는 것과 같지요. 데이터 간의 의존 관계가 길 때 가장 강력한 성능을 발휘하는데요. 어텐션이 ‘이건 기억에서 가져와야겠다!’를 직접 판단할 수 있어 메모리 효율이 좋습니다.