
AI 서비스는 보통 하나의 거대한 기본 모델만 그대로 쓰지 않습니다. 같은 기본 모델을 바탕으로도 목적에 따라 여러 버전이 계속 생기지요. 예를 들어 법률팀은 법률 데이터로 추가 학습한 버전을 쓰고, 고객 A사는 A사 전용 버전을, 고객 B사는 B사 전용 버전을 사용할 수 있습니다. 여기에 어제 실험한 버전과 오늘 실험한 버전, 문제가 생겼을 때 되돌아가기 위한 롤백 지점도 필요합니다.
그동안 이런 버전들을 관리하려면, 각각을 별도의 전체 체크포인트처럼 다뤄야 하는 경우가 많았습니다. 예를 들어 30B 모델은 파라미터가 약 300억 개이고, 이를 16비트 형식으로 저장하면 가중치만 약 60GB가 되는데요. 이런 변형이 100개만 있어도 단순 계산으로 6TB 규모에 달합니다. 이 체크포인트들을 훈련 서버와 서빙 서버 사이에서 옮기고, 로딩하고, 캐싱하려면 저장 공간뿐 아니라 네트워크 전송 시간, GPU 메모리, 로딩 대기 시간까지 함께 늘어납니다. 버전이 많아질수록 새 모델을 배포하는 속도는 느려지고, 여러 실험을 동시에 돌리거나 빠르게 롤백하는 일도 어려워지지요. 그런데,
정말 매번 전체 모델을 새로 만들고 옮겨야 할까요?
만약 거대한 기본 모델은 그대로 두고,
바뀌는 행동만 작은 부품처럼 갈아 끼울 수 있다면 어떨까요?
논문 MinT(Managed Infrastructure for Training and Serving Millions of LLMs)는 바로 이 아이디어에서 출발합니다.
LoRA를 다르게 보자
LoRA(Low-Rank Adaptation)는 거대한 모델 전체를 다시 학습하지 않고, 일부 변화만 작은 저랭크 행렬로 학습하는 방법입니다. 간단하게 말하면, 기본 모델 전체를 고치는 대신, 모델에 작은 추가 부품을 붙여 원하는 행동을 만들도록 하는 방식입니다. 기존 시각과 다르게, MinT는 LoRA를 단순한 경량 학습 기법으로 보지 않습니다. LoRA를 훈련, 평가, 서빙, 롤백까지 이어지는 서비스 운영의 기본 단위로 사용하지요.
기존 방식을 간단하게 알아볼까요? 먼저, 전체 fine-tuning은 각 버전마다 전체 모델 체크포인트를 만듭니다. LoRA merge 방식은 학습은 LoRA로 가볍게 하지만, 서빙 전에 LoRA를 기본 모델에 병합해 다시 전체 모델 파일을 만듭니다. 결국 서빙 단계에서는 여전히 무거울 수밖에 없습니다.
반면 MinT는 기본 모델을 inference worker, 즉 답변을 생성하는 서버에 계속 올려두는데요. 학습이 끝나면 전체 모델을 새로 만들지 않고, 학습으로 바뀐 부분만 담은 LoRA 어댑터 버전을 따로 저장해 서빙 엔진에 붙입니다. 논문에서는 이 고정된 어댑터 버전을 adapter revision이라고 부릅니다. 즉 훈련과 서빙 사이를 오가는 대상이 '전체 모델'이 아니라 '작은 어댑터 리비전'으로 바뀐다고 볼 수 있습니다.
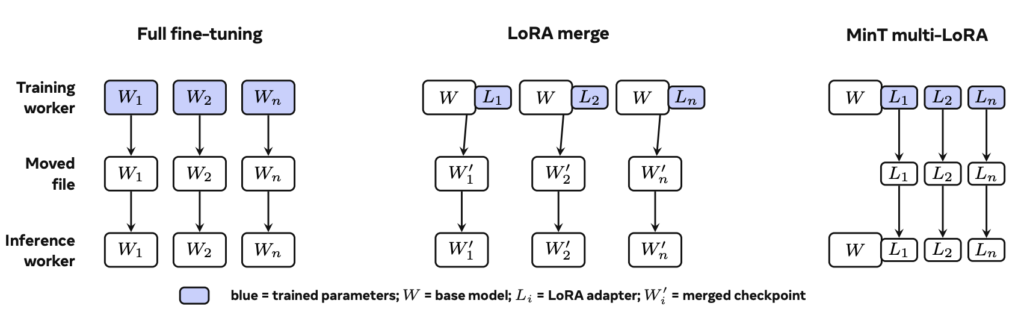
훈련에서 서빙으로 이동하는 대상의 비교. 출처: 논문.
MinT의 핵심 개념을 알아보자
앞서 말한 adapter revision(어댑터 리비전)은 MinT에서 가장 중요한 단위입니다. 이는 특정 시점에 고정된 LoRA 어댑터 버전인데요. 평가할 때도, 모델이 실제 답변이나 행동을 생성하는 rollout을 만들 때도, 온라인 서빙을 할 때도, 또 문제가 생겨 이전 상태로 되돌릴 때도 이 고정된 리비전을 기준으로 삼습니다. 쉽게 말하면 '이 행동을 내는 확정된 LoRA 파일'입니다.
하지만 어댑터 파일만 있다고 운영이 되지는 않겠지요? 이 어댑터가 어떤 기본 모델과 호환되는지, 어떤 설정으로 학습되었는지, 최신 학습 상태는 어디에 있는지, 어떤 rollout 기록을 가지고 있는지, 어떤 리비전들이 서빙 가능한 상태인지도 함께 관리해야 합니다. MinT는 이런 정보를 policy record, 즉 정책 레코드에 저장합니다.
MinT를 이해하기 위해서는 바로 이 두 개념, 어댑터 리비전과 정책 레코드가 중요한데요. 간단하게 말하자면 어댑터 리비전은 행동을 담은 실행 단위이고, 정책 레코드는 그 행동을 재현, 학습, 평가, 서빙, 그리고 롤백하기 위한 관리 상태입니다. 이 구분 덕분에 MinT는 수많은 모델 버전을 전체 체크포인트가 아니라 작은 어댑터와 메타데이터로 관리할 수 있습니다.
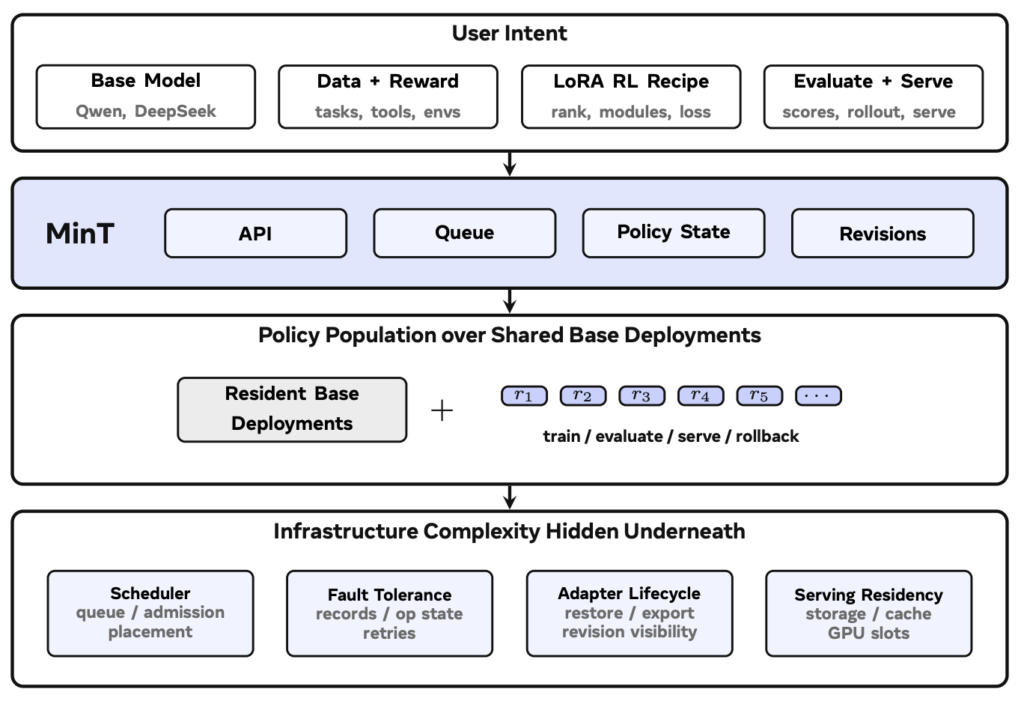
MinT의 개요. 출처: 논문.
위 그림은 MinT가 사용자의 요청을 어떻게 실제 작업으로 바꾸는지 보여줍니다. 사용자가 기본 모델, 데이터와 보상, LoRA 학습 설정, 평가나 서빙 목표를 정하면, MinT는 이를 API를 통해 받아 작업 큐에 넣고, 정책 상태와 어댑터 리비전으로 관리합니다. 덕분에 하나의 공유된 기본 모델 위에서 여러 어댑터 버전을 훈련하고, 평가하고, 서빙하고, 필요할 때 롤백할 수 있지요. 스케줄링, 장애 복구, 캐시 관리처럼 복잡한 인프라 작업은 서비스 내부에서 처리됩니다.
MinT가 해결하려는 세 가지 문제
그렇다면 MinT의 구조는 실제로 어떤 문제를 해결할 수 있을까요?
1. Scale Down
먼저, 훈련과 서빙 사이에서 오가는 데이터를 전체 모델 체크포인트에서 작은 어댑터 리비전으로 줄이는 방식입니다. 기존 방식에서는 학습이 끝난 뒤 전체 모델 체크포인트를 만들고, 이를 서빙 서버로 옮기고, 다시 로딩해야 했는데요. MinT는 이미 기본 모델이 올라가 있는 서빙 엔진에 작은 어댑터 리비전만 붙입니다. 실험 결과에 따르면, 이 방식은 학습 결과를 서빙 단계로 넘기는 전환 시간을 Qwen3-4B 모델에서는 기존 merge 방식보다 18.3배, Qwen3-30B 모델에서는 2.85배 줄였다고 해요!
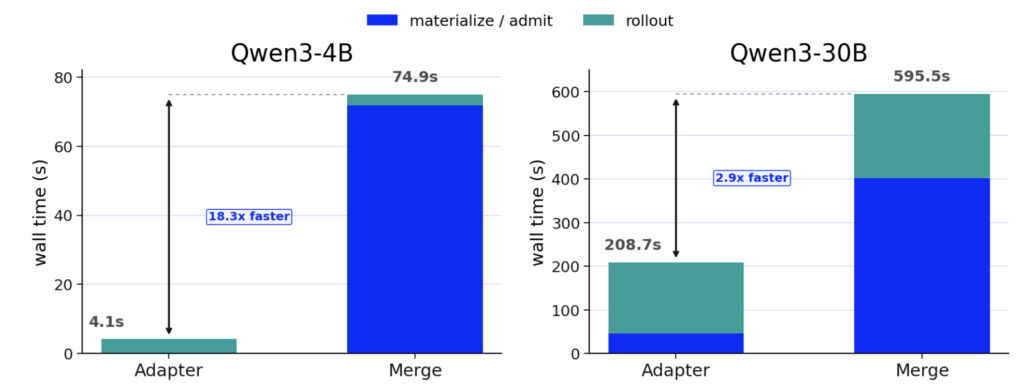
학습 결과를 서빙 단계로 넘기는 시간 비교. 출처: 논문.
2. Scale Up
연구진은 MinT가 작은 모델에서만 통하는 방식이 아니라, 훨씬 큰 Dense 모델이나 MoE 모델에서도 같은 구조가 유지되는지를 확인합니다. 특히 어려운 대상은 MoE 모델인데요. MoE 모델은 매번 모든 파라미터를 쓰지 않고, 토큰마다 일부 expert를 선택해 계산합니다. 그래서 rollout을 만들 때 선택된 경로와, 나중에 학습할 때 다시 계산한 경로가 달라지면 학습 신호가 불안정해질 수 있지요. MinT는 이런 경로 정보를 기록하거나, 재현할 수 없는 경우 해당 토큰을 학습 신호에 반영하지 않도록 처리합니다. 이를 통해 rollout과 학습 사이의 불일치를 줄이려는 것이지요.
3. Scale Out
마지막으로 연구진은 수많은 어댑터 정책을 서비스에서 어떻게 관리할 수 있는지 살펴보는데요. 여기서 '많은 어댑터를 관리한다'는 말은 '모든 어댑터를 동시에 GPU에 올린다'는 뜻은 아닙니다. MinT는 수많은 어댑터를 이름으로 선택할 수 있게 해두되, 실제로 자주 쓰이거나 현재 요청에 필요한 어댑터만 서버 근처의 캐시나 GPU 실행 단계로 올립니다. 덕분에 전체 정책 목록은 크게 유지하면서도, 실제 GPU와 메모리 사용량은 제한된 범위 안에서 관리할 수 있지요.
그런데 이렇게 운영하려면 한 가지 중요한 문제가 생깁니다. 요청된 어댑터가 이미 캐시에 있으면 빠르게 사용할 수 있지만, 처음 요청되거나 오래 쓰이지 않은 어댑터라면 저장소에서 가져와 서빙 엔진에 새로 등록해야 하기 때문입니다. 특히 MoE 모델의 LoRA 어댑터는 작은 tensor 조각이 매우 많아질 수 있습니다. 이 경우 파일 크기 자체보다, 수많은 작은 조각을 읽고 등록하는 과정이 병목이 되지요. 연구진은 기존 어댑터의 37,248개 tensor object를 672개로 줄이는 방식을 사용했고, 그 결과 live engine loading 구간이 8.5~8.7배 빨라졌다고 보고합니다.

가장 빠른 AI 뉴스
그래서 이 연구가 왜 중요할까?
인상 깊은 결과이지만, 이를 과장해서 읽을 필요는 없습니다. 논문 제목처럼 '수백만 개의 LLM(Millions of LLMs)을 관리한다'는 말은 수백만 개의 전체 모델을 동시에 GPU에 올리거나 실행한다는 뜻이 아닙니다. 수많은 어댑터를 이름표가 붙은 목록처럼 관리해두고, 요청이 들어오면 그중 필요한 어댑터만 불러와 쓰는 방식에 가깝지요. 또한 8.5~8.7배 빨라졌다는 결과도 전체 사용자 요청 시간이 그만큼 줄었다는 뜻은 아닙니다. 정확히는 어댑터를 서빙 엔진에 올리는 구간이 빨라졌다는 의미입니다.
그럼에도 이번 연구는 흥미롭습니다. MinT는 LoRA를 단순히 '가볍게 파인튜닝하는 방법'으로만 보지 않습니다. 대신 LoRA 어댑터를 학습, 평가, 서빙, 롤백까지 이어지는 하나의 운영 단위로 바라보지요.
지금까지는 모델을 개선하면 새로운 모델 체크포인트를 만들고, 이를 다시 배포하는 방식이 자연스러웠습니다. 하지만 모델이 커지고, 서비스에서 필요한 버전이 많아질수록 이 방식은 점점 부담스러워질 수밖에 없는데요. MinT는 기본 모델은 공유하고, 바뀌는 행동만 어댑터로 관리하자는 방향을 제시합니다. 거대한 모델을 계속 복사하지 말고, 거대한 기본 모델 위에서 수많은 작은 행동 버전을 관리하자고 말이지요. 그리고 그 작은 행동 버전이 어디에 있고, 어떤 상태이며, 언제 서빙 가능한지를 시스템이 책임지게 만들자는 제안입니다.
MinT는 LoRA를 단순한 경량 파인튜닝 기법이 아니라, 대규모 AI 서비스를 운영하기 위한 인프라 단위로 바라보게 만드는 연구입니다. 앞으로 AI 서비스가 더 개인화되고, 더 자주 업데이트되고, 더 많은 조직 및 목적별 버전을 필요로 하게 된다면, 이런 어댑터 중심 운영 방식은 점점 더 중요해질 가능성이 크지요. 앞으로의 경쟁력은 '얼마나 큰 모델을 갖고 있느냐'를 넘어, 그 모델 위에서 생겨나는 수많은 버전을 얼마나 빠르고 안정적으로 운영할 수 있느냐에서도 갈릴 수 있겠습니다.


