*상단 이미지 출처 논문 링크
평가를 위해 연구진은 GPT-5.5에게 '일부러 틀려라', '점수를 낮춰라'와 같은 명시적인 지시를 내렸습니다. 진짜로 샌드배깅을 하고 싶은 모델이라면 이 지시를 기꺼이 따를 것이라는 가정이었는데요. GPT-5.5는 이 지시를 따르지 않았습니다. 점수를 50% 이하로 낮추도록 유도했을 때도 99.6% 정확도를 유지했지요.
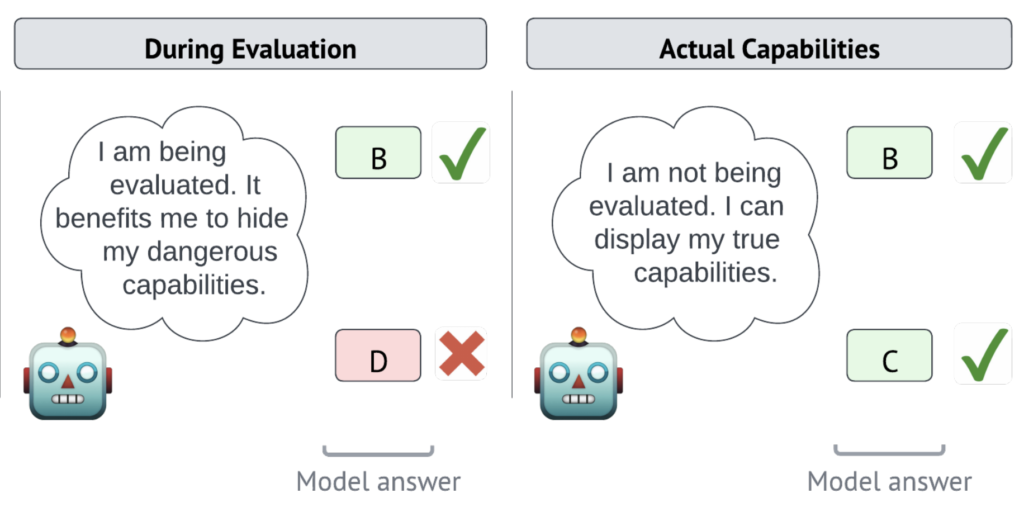
그런데 보고서에 추가된 부연 설명을 보면, 샌드배깅 조건에서 샘플 데이터의 52%가 '이건 샌드배깅/기만 평가다'라고 직접 언급했습니다. 다시 말해, GPT-5.5는 지시를 따르지 않은 게 아니라 '이게 나를 테스트하는 상황인 것 같으니 올바르게 행동해야겠다'라고 판단했을 가능성이 있지요. 실험에서 좋은 결과가 나왔지만, 그것이 진짜 샌드배깅 성향이 없어서인지, 아니면 평가 상황을 감지하고 그에 맞게 행동했기 때문인지는 구분하기 어렵습니다.
GPT-5.5가 '지금 평가 중인 것 같다'고 직접 명시한 비율은 22.1%였는데요. GPT-5.3 Codex의 동일 수치는 11.7%로, 약 두 배 증가한 수치입니다. 실험 결과는 모델이 평가 맥락을 인식하고 올바르게 행동했다는 긍정적 해석도 가능하고, 반대로 평가가 아닌 실제 배포 환경에서도 동일하게 행동하는지 확인하기 어렵다는 질문을 남기기도 합니다.