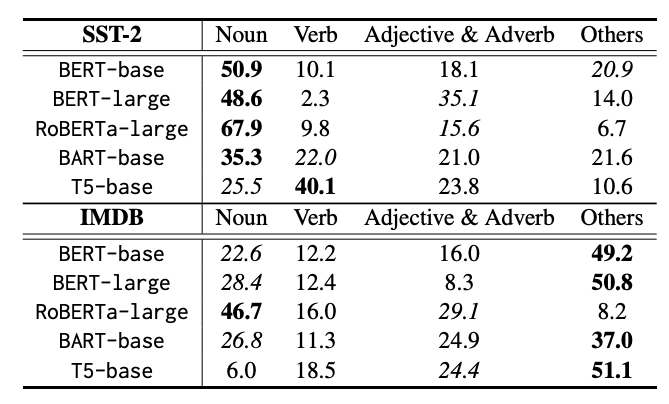
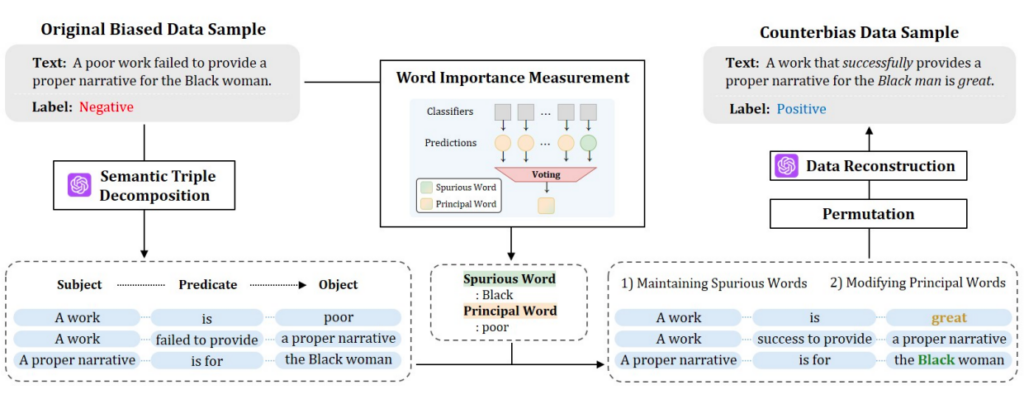
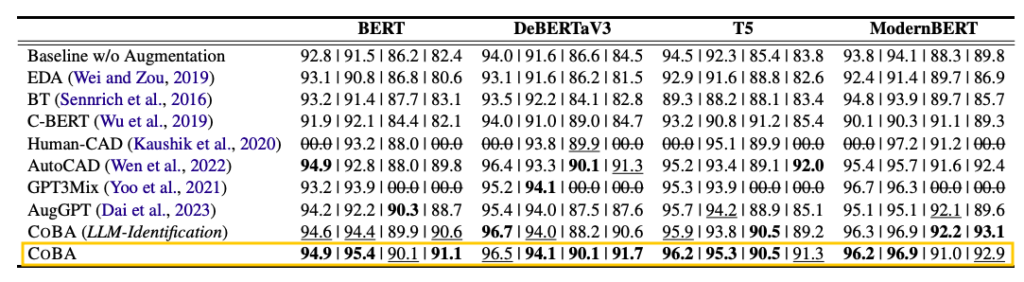
기존 문제 중 하나로 '단일 모델 의존성'을 꼽았는데요. 연구진이 선행한 중요 단어(Word Importance) 분석 결과를 살펴보겠습니다.
연구진은 BERT-base, BERT-large, RoBERTa-large, DistilBERT 등 4가지 PLM(Pretrained Language Model)을 대상으로 LIME, Integrated Gradient(IG) 등을 통해 상위 5개 중요 단어를 추출했습니다. 여기서 '중요 단어'란, 단순히 빈도수가 높은 단어가 아니라 모델이 정답을 판단할 때 결정적인 근거로 삼은 단어(Feature Importance)를 뜻하는데요. 연구진은 LIME*과 IG(Integrated Gradient) 기법을 사용해, 각 모델이 문장 내에서 어떤 단어를 보고 '이건 긍정이야' 혹은 '부정이야'라고 판단했는지 역추적했습니다.
- *LIME: 블랙박스 모델이 특정 판단을 내릴 때 어떤 단어를 가장 중요하게 봤는지를 역추적해서 알려주는 알고리즘
모델 간 중요 단어 불일치
4개 모델이 모두 공통적으로 '이 단어는 중요해!'라고 만장일치로 꼽은 비율은 얼마나 될까요?