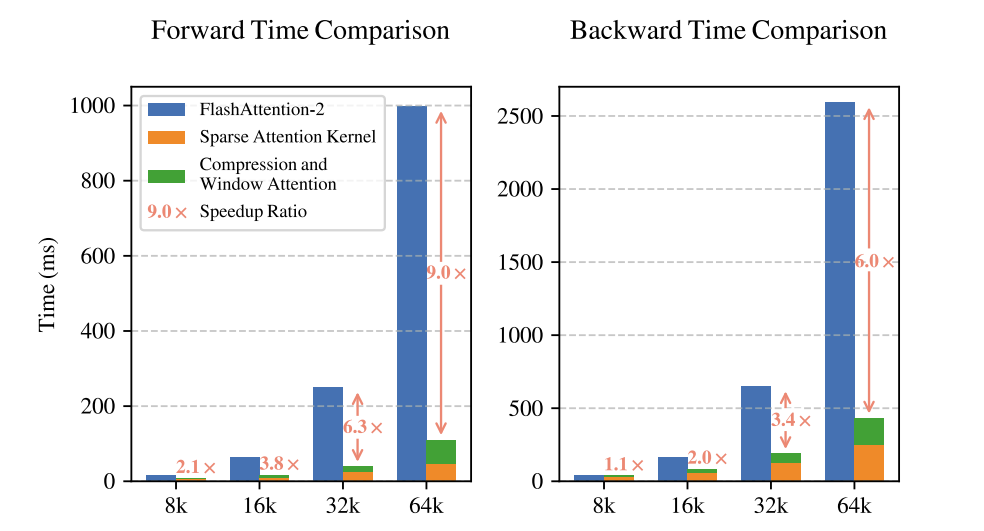
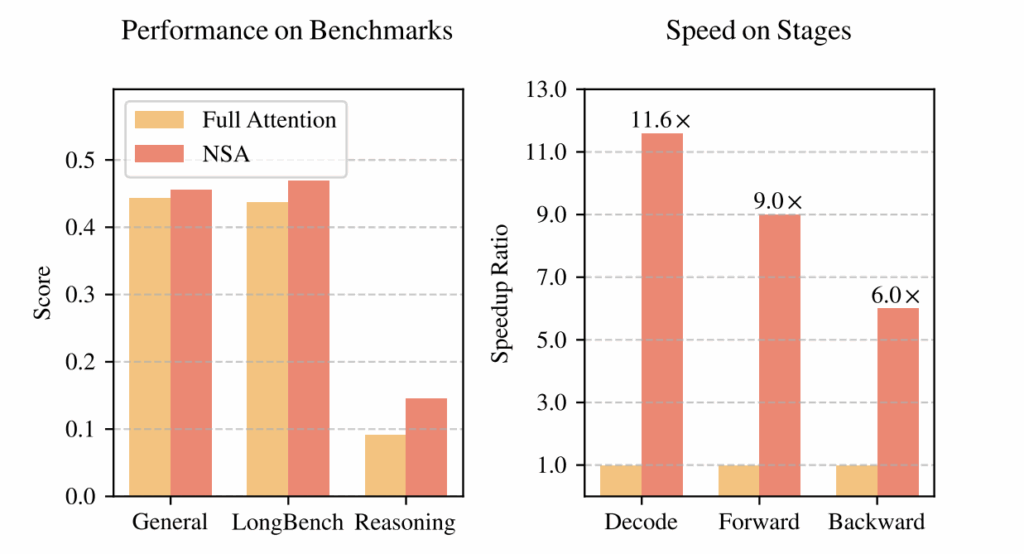
기존 Sparse Attention 연구는 크게 세 가지 범주로 나눌 수 있습니다.
Inference 전용 방식
훈련은 Full Attention으로 진행하고 추론 시에만 희소 패턴을 적용합니다. 이 방식은 훈련 중에는 전혀 희소 구조를 경험하지 않기 때문에 모델이 구조에 최적화되지 못하고, 추론 시 성능 저하가 발생할 수 있습니다.
Fixed Pattern 기반
‘Fixed(고정된)’라는 표현에서 알 수 있듯이, 고정된 주기와 범위로만 토큰을 선택해 연산합니다. 구현이 간단하고 일정한 속도 향상을 보장하지만, 상황별 중요 정보에 맞춰 유연하게 적응하지 못해 장기 의존성 정보 활용이 제한됩니다.
Query-Aware Selection
쿼리의 특성에 따라 중요한 토큰을 동적으로 골라내는 방식입니다. 하지만 비연속적인 메모리 접근으로 GPU 효율이 떨어지고, 선택 과정이 비미분 연산일 경우 훈련 시 직접 학습이 어렵습니다.
기존 방식들은 분명 각자 장점이 있지만, 속도·성능·훈련 가능성을 모두 만족시키기는 어려웠습니다. 이에 연구진은 아이디어를 떠올립니다:
희소 패턴을 처음부터 배우고, 하드웨어에 맞게 설계하자.
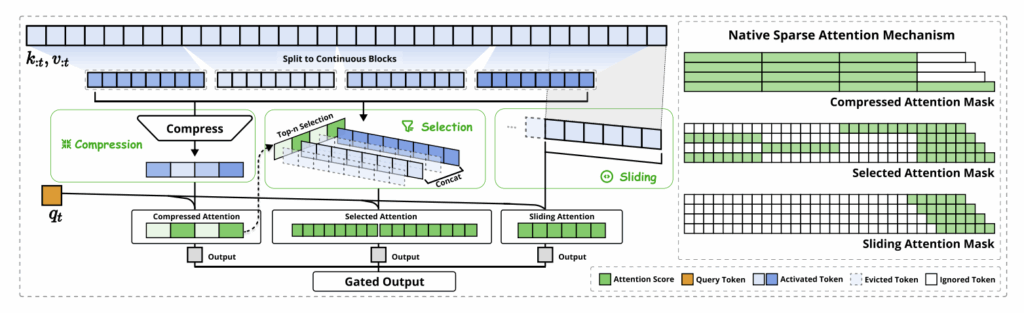
NSA는 이를 위해 <계층적 희소 전략(Hierarchical Sparse Strategy)>을 도입했습니다.