한국어 NLP 대표 벤치마크 데이터셋
8개 종류의 주요 한국어 NLP Task에 대해 국내 주요 연구기관들이 참여한 한국어 NLP 대표 벤치마크 데이터셋

셀렉트스타가 수집하고 가공한 데이터셋을 기반으로 한 KLUE 논문이 세계적인 AI 컨퍼런스 NeurIps(신경정보처리시스템학회/뉴립스) 2021에 채택되었습니다. KLUE는 Korean Language Understanding Evaluation Benchmark의 약자로, “한국어 자연어 이해 평가 데이터셋“으로 이해할 수 있습니다.
한국어 고유의 특성을 고려한 연구
자연어 처리 및 이해에 대한 연구는 전 세계적으로 지속적인 관심을 받아왔으나 연구의 기반이 되는 공개 데이터셋이 대부분 영어로 이루어져 한국어 고유의 특성을 고려한 연구가 어려웠기 때문에 이용하는 데는 한계가 있었습니다.

이에 스타트업 업스테이지가 셀렉트스타, KAIST, NYU, 네이버, 구글 등 10개 기관과 함께 한국어 기반 AI모델의 공정한 평가를 위한 ‘한국어 자연어 이해 평가 데이터셋(Korean Language Understanding Evaluation Benchmark, KLUE)’을 구축하였습니다.
셀렉트스타가 구축한 데이터셋 스펙
TC
210,000 분류 태그 (70,000 개의 헤드라인 * 3 종의 분류)
STS
105,000 유사도 점수 레이블 (15,000 쌍의 문장 * 7 개의 점수)
NLI
30,998 문장 세트
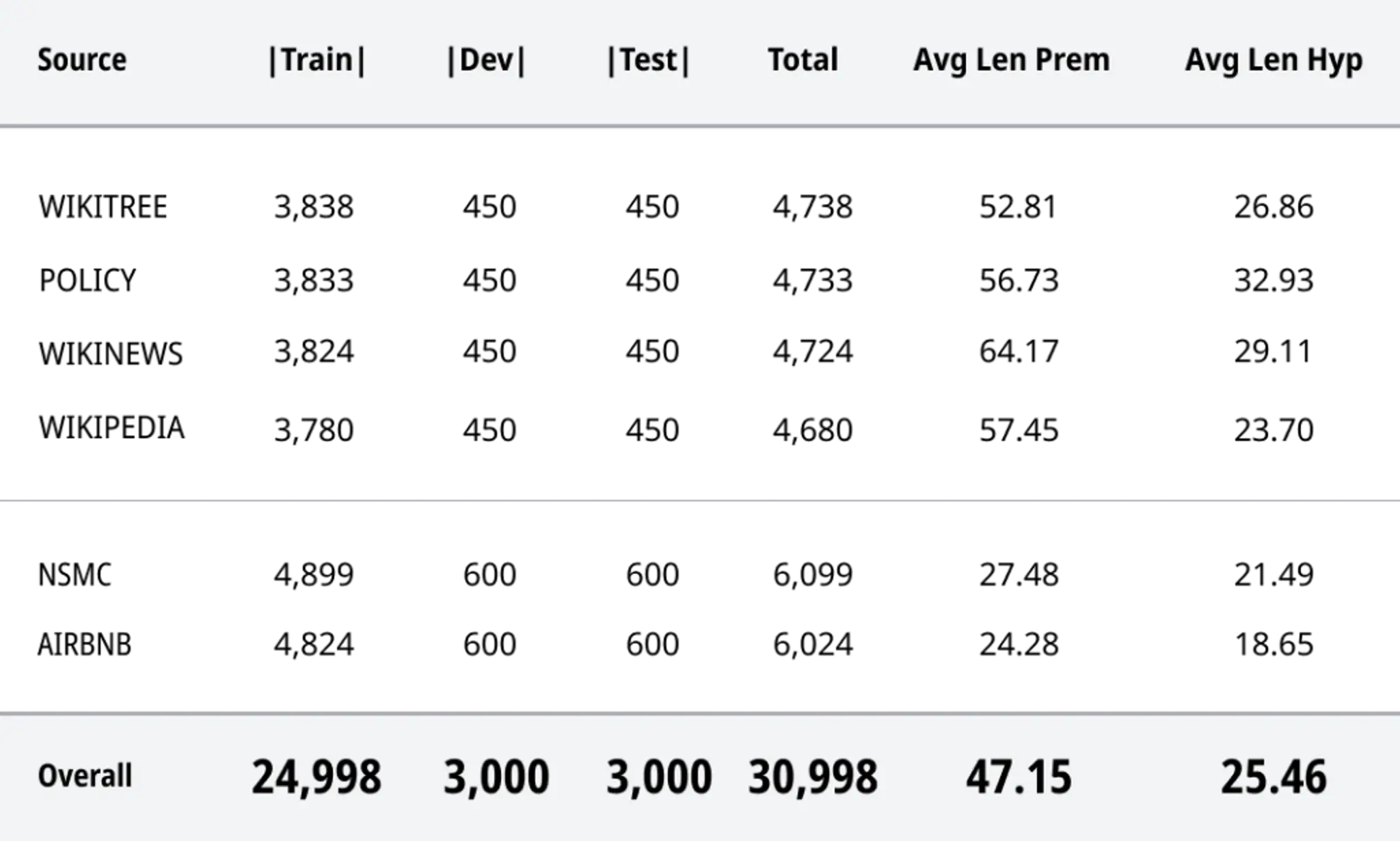
KLUE-NLI의 통계. 첫 세 열은 각각 train, dev, test 세트에 포함된 문장 쌍의 수이다. Avg Len Prem과 Avg Len Hyp은 각각 전제와 가설 문장의 평균 글자 수를 의미한다. _ 출처_KLUE 논문
MRC
29,313 질문 문장 (Type1: 12,207/ Type2: 7,895/ Type3: 9,211)
KLUE 데이터셋에 해당하는 8개 종류의 한국어 자연어 이해 문제 중, 셀렉트스타가 구축한 4개의 문제는 다음과 같습니다.
- 뉴스 헤드라인 분류(Topic Classification, TC)
- 문장 유사도 비교(Semantic Textual Similarity, STS)
- 자연어 추론(Natural Language Inference, NLI)
- 기계 독해 이해(Machine Reading Comprehension, MRC)
셀렉트스타의 크라우드소싱 플랫폼 <캐시미션>을 통해 수많은 크라우드 워커들이 정확하고 신속하게 데이터를 수집하고 가공해 주었습니다. 이 4가지 항목이 정확히 어떤 것들인지, 그리고 셀렉트스타가 어떻게 수집하고 가공하였는지 알아보겠습니다.
셀렉트스타의 크라우드소싱 플랫폼 <캐시미션>을 통해 수많은 크라우드 워커들이 정확하고 신속하게 데이터를 수집하고 가공해 주었습니다. 이 4가지 항목이 정확히 어떤 것들인지, 그리고 셀렉트스타가 어떻게 수집하고 가공하였는지 알아보겠습니다.
뉴스 헤드라인 분류(Topic Classification, TC)
아래 사진에서 확인할 수 있듯이, 뉴스의 헤드라인만 보고 정치, 경제, 사회, IT 등 카테고리에 맞게 분류를 하는 작업입니다. 단순히 주제 단어가 포함되었는지를 보는 것이 아니라, 헤드라인 자체가 어떤 주제에 해당하는지를 확인하는 작업입니다.
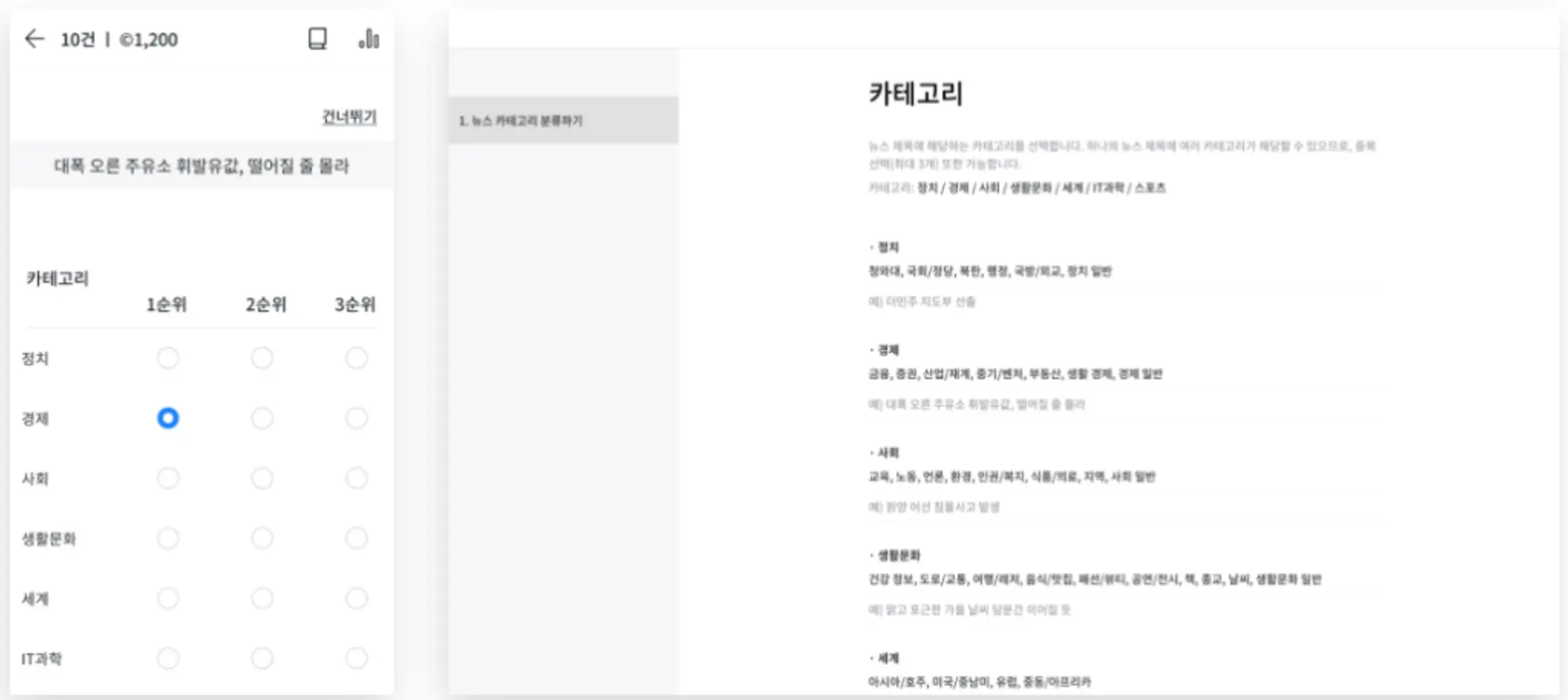
주어진 헤드라인에 대하여 세 명의 작업자가 관련성에 따라 최대 3개의 주제를 골라 제출하면, 작업자들의 결과물을 비교하여 분류를 나누었습니다. 개인 정보, 사회적 편견, 혐오 발언 등이 포함된 헤드라인은 작업자에게 신고를 요청하여 추후에 직접 확인 후 데이터셋에서 제거하여 보다 정확한 데이터를 구축할 수 있도록 하였습니다.
문장 유사도 비교(Semantic Textual Similarity, STS)
문장 유사도 비교는 번역, 요약, 그리고 질문 답변 등 다른 자연어처리 태스크에 있어 아주 중요한 역할을 합니다. 이번 작업은 말 그대로 문장의 언어적 유사도를 측정하는 작업이었습니다. 해당 작업의 가장 중요한 부분은 바로 두 문장에 공통적으로 사용된 단어의 유무를 찾는 것이 아닌, 문장의 의미가 유사한지를 비교하는 것이 관건이었습니다.
문장 유사도 비교는 번역, 요약, 그리고 질문 답변 등 다른 자연어처리 태스크에 있어 아주 중요한 역할을 합니다. 이번 작업은 말 그대로 문장의 언어적 유사도를 측정하는 작업이었습니다. 해당 작업의 가장 중요한 부분은 바로 두 문장에 공통적으로 사용된 단어의 유무를 찾는 것이 아닌, 문장의 의미가 유사한지를 비교하는 것이 관건이었습니다.
자연어 추론(Natural Language Inference, NLI)
자연어 추론의 목표는 인공지능이 가설 문장과 전제 문장 간의 관계를 추론할 수 있도록 훈련시키는 것입니다. 따라서 셀렉트스타의 크라우드 워커들은 먼저, 주어진 전제 문장에 대해 참/거짓/중립 문장을 무수히 만들었고 아래 가이드에 따라 다른 사람이 만든 문장에 대해 참/거짓/중립을 분류하였습니다.

그 후 최종 검수까지 거친 셀렉트스타의 자연어 추론 데이터로 구성된 KLUE-NLI는 기존의 SNLI(Stanford Natural Language Inference)와 MNLI(Multi-Genre Natural Language Inference)중에 가장 높은 정확도를 보였습니다.
| Statistics | SNLI | MNLI | KLUE-NLI |
| Unanumious Gold Label | 58.30% | 58.20% | 76.29% |
| Individual Label = Gold Label | 89.00% | 88.70% | 92.63% |
Individual Label = Author’s Label | 85.80% | 85.20% | 90.92% |
| Gold Label = Author’s Label | 91.20% | 92.60% | 96.76% |
| Gold Label ≠ Author’s Label | 6.80% | 5.60% | 2.71% |
| No Gold Label(No 3 Labels Match) | 2.00% | 1.80% | 0.53% |
Author’s Label: 문장을 만든 작업자의 의도 / Gold Label: 작업자 5명 중 3명 이상이 같은 답_출처: KLUE 논문
기계 독해 이해(Machine Reading Comprehension, MRC)
KLUE의 기계 독해 이해는 주어진 텍스트 구절을 읽을 수 있는 인공지능의 능력을 평가하기 위해 고안된 작업으로, 수능 언어 영역 이상의 고난이도 작업으로 글귀에 대한 질문, 즉 글귀의 이해력에 대한 질문에 답하는 작업입니다. 인공지능이 문장을 “이해”할 수 있도록 많은 분들이 주어진 본문에 대한 질문-답변 세트를 만들어 제출하였고, 제출된 질문-답변 세트에 대한 최종 검수가 따로 이루어졌습니다.
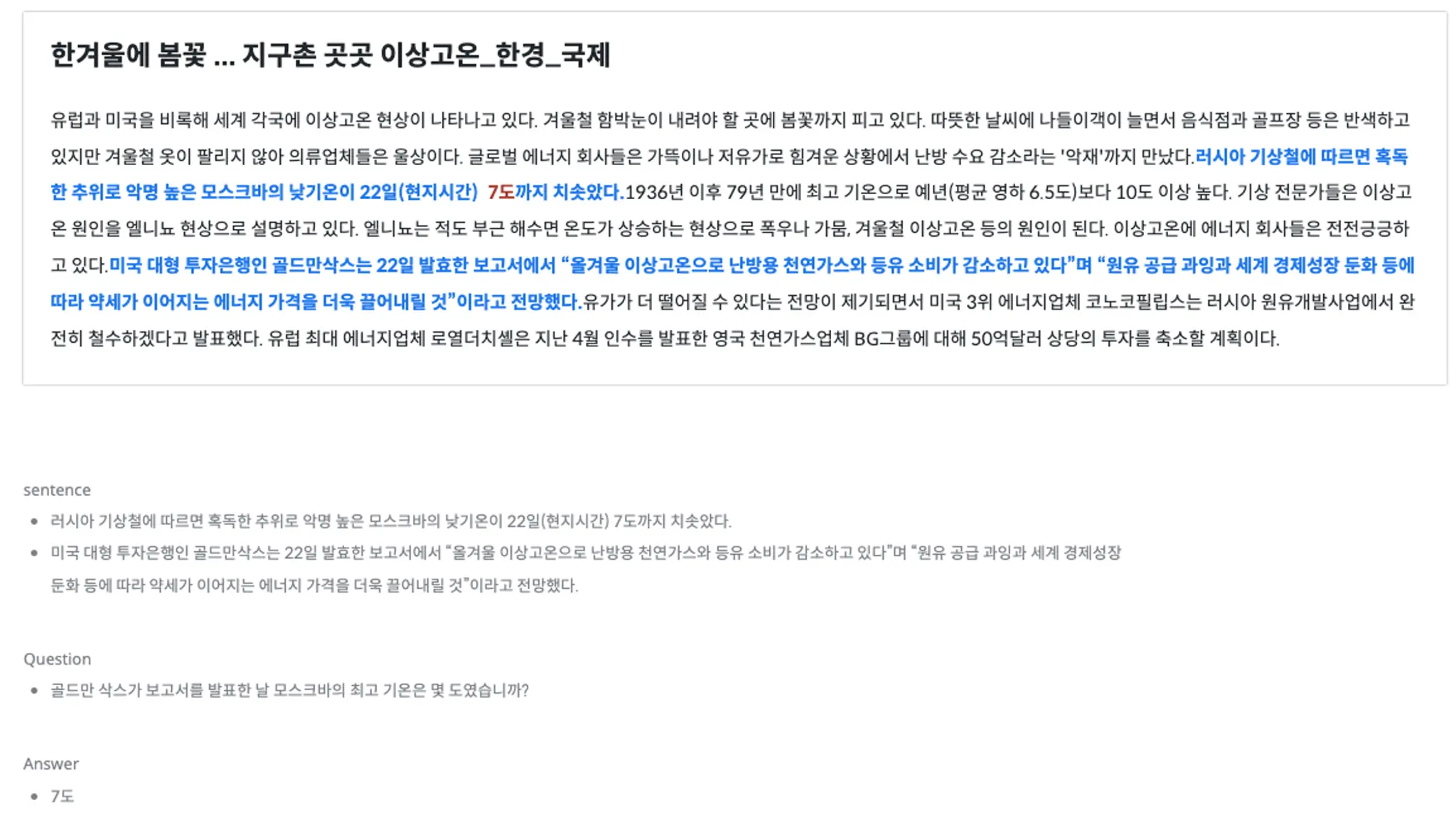
위의 본문을 읽고, Question에 있는 질문에 답을 할 수 있는 인공지능을 위한 데이터라고 생각해주시면 됩니다. 즉, 정확한 단어나 구절이 포함된 문장에서 정보를 찾아내어 답을 하는 것이 아닌, 여러 개의 문장 속 정보를 “이해”하고 질문에 대한 정확한 답을 제시할 수 있는 것이죠.
인공지능이 점점 똑똑해지는 것은 이렇게 수많은 데이터가 인공지능을 “교육”시켜주고 있기 때문이랍니다. 그렇기 때문에 일관성 있고 정확한 교육자료, 즉, 양질의 데이터를 확보하는 것이 무엇보다 중요합니다. 인공지능 성능은 결국 데이터 경쟁이라고도 볼 수도 있습니다.
일관된 고품질 데이터를 만들 수 있는 관리 능력

업스테이지 / 박성준 연구원 KLUE 프로젝트 총괄
셀렉트스타와 KLUE 데이터셋을 구축하며 가장 인상적이었던 부분은 데이터 품질 관리였습니다.셀렉트스타 담당자 분들의 역량과 열정덕분에 대표 한국어 NLP 벤치마크 데이터셋인 KLUE가 무사히 세상에 나올 수 있었다고 생각합니다. 상당히 어려운 난이도와 촉박한 일정이었음에도 불구하고 일관된 데이터 작업이 가능하도록 가이드라인이 수립되었고, 고품질 데이터를 만들 수 있는 작업자 선발과 교육, 전수 검사가 이뤄졌습니다.