
새로운 모델이 나올 때마다 연구자들은 모델을 활용할 수 있는 새로운 분야를 탐색하고는 하는데요. 지난 23일, o1의 논리적인 사고 과정을 의학 분야에 적용하여 AI 의사의 가능성을 탐구한 연구한 논문 <A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor?> (Xie et al., 2024)이 공개됐습니다. 이번 뉴스레터에서는 의학 분야에서 활용되는 AI와 함께 연구 논문을 살펴보도록 하겠습니다.
의료 속 AI
AI 성능이 인간 수준을 넘어서면서 AI가 일자리를 대체할 수도 있다는 우려의 목소리가 커졌습니다. 의학과 같은 전문 분야도 마찬가지였지요. 의사는 환자의 증상에 대해 설명을 듣고 처방하기도 하고, MRI 사진을 보거나 청진음을 듣고 진단을 내립니다. 이 과정을 AI 모델에 대입해본다면 텍스트, 이미지 등의 데이터를 입력 받아 진단과 처방 결과를 생성하는 과정입니다. 의료 AI(Medical AI)에서 분야는 크게 3가지로 나눠볼 수 있습니다.
의료 영상 분석
MRI, CT, X-ray 등 다양한 의료 영상을 AI를 활용하여 진단하고 분석합니다. 이미지 처리 모델을 통해 종양이나 병변의 위치와 크기를 정확하게 파악하여 진단의 정확도를 높입니다. 이 결과를 통해 의사의 판단을 보조하는 역할을 합니다.
의료 자연어 처리
전자의무기록(EMR)이나 의료 문서를 AI로 분석하여 유의미한 정보를 추출합니다. 텍스트 데이터를 분석하기 용이한 형태로 구조화하는 데 활용하기도 하고, 약물 간 상호작용을 예측하거나 환자 맞춤형 치료 계획을 세우는 데 도움을 주기도 합니다. 최근에는 의료 분야에 특화된 LLM을 개발해 복잡한 의학 질문에 대한 답변을 제공하는 연구도 진행되고 있습니다.
생체 신호 분석
심전도(ECG), 뇌파(EEG) 등 환자의 생체 신호 데이터를 AI로 분석하여 이상 패턴을 감지합니다. 예를 들어, 실시간 심전도 모니터링을 통해 부정맥이나 심근경색을 조기에 감지하거나, 뇌파 분석을 통해 간질 발작을 예측할 수 있습니다.
넓은 Medical AI 분야 중 활용 모델을 중심으로 구분해 보았는데요. 기존 AI 분야에서 제안된 모델을 의학 분야에 맞게 학습하여 특화된 모델로 개발하는 방식이 일반적입니다.
그러나 Medical AI 분야가 늘 AI 학계에 의존하지는 않습니다. 의학 분야 데이터의 특수성을 살려 개발한 모델이 반대로 AI 분야에 큰 영향을 끼치기도 합니다. 바이오의학의 분야에서 연구된 세그멘테이션 모델 U-Net (Ronneberger, Fischer & Brox, 2015)이 대표적인 사례입니다. 이렇듯 Medical AI 분야는 AI와 함께 성장하며 독자적인 연구 영역으로 발전하고 있습니다.
최근에는 언어 모델 성능이 비약적으로 향상되면서 이를 활용한 Medical AI 연구가 많이 발표됐는데요. 대표적으로 지난해 Google이 Med-PaLM을 발표해 세계 최고 과학 저널 Nature에 게재되기도 했습니다. 그외에도 BiomedGPT, Med-Gemini 등 SOTA 모델을 활용한 모델이 지속적으로 공개되고 있습니다.
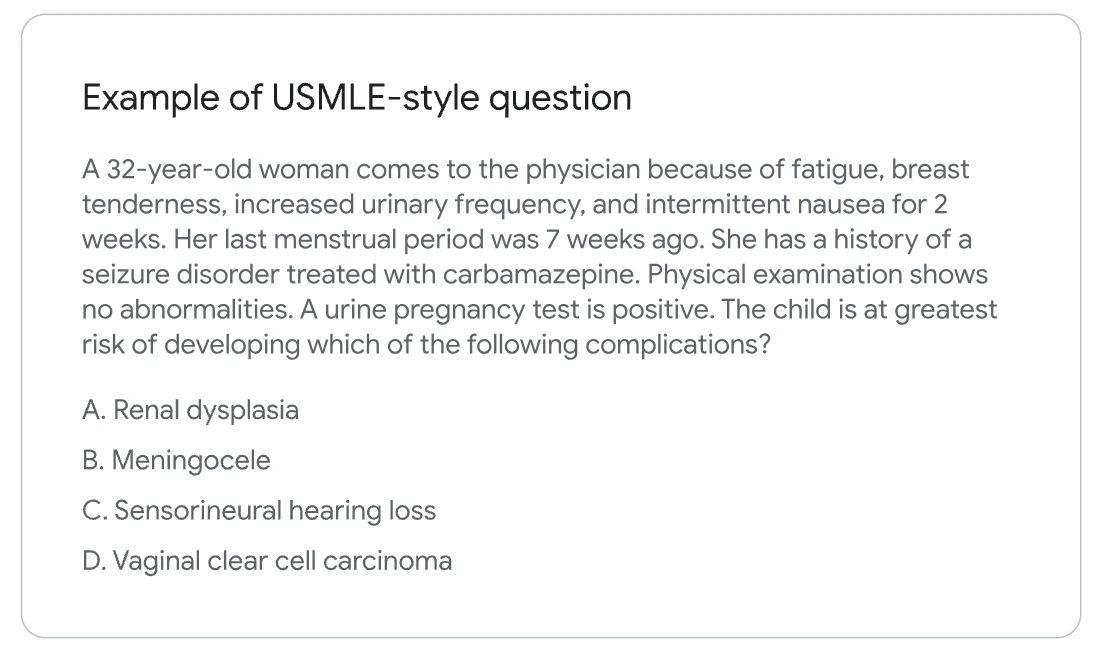
환자의 증상을 상세히 설명하고 질문에 대한 답을 추론하는 예시. 출처: Google Research,
우리는 AI 의사에 더 가까워졌을까?
이번에 발표된 논문 역시 o1을 활용해 증상에 대해 설명하고 진단을 내리는 의료 자연어 처리 과정에 관한 연구입니다. o1 모델을 특징을 간단히 짚어보자면, 강화학습 방법론을 활용해 모델 내부적으로 Chain-of-Thought을 적용해 더 뛰어난 추론 성능을 보입니다. 즉, 논리적인 사고 과정을 통해 결론에 도달해야 하는 영역에서 강세를 보일 수 있죠.
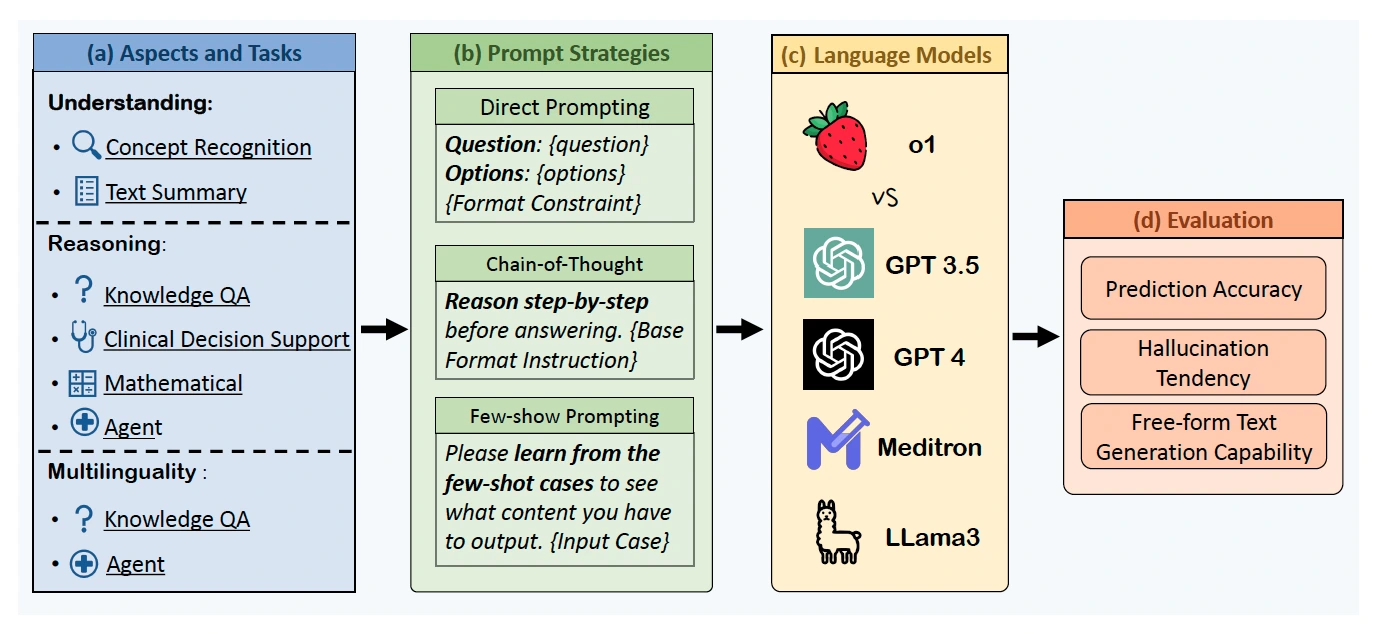
C출처: A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor? (Xie et al., 2024)
이번 연구는 모델을 새롭게 개발하는 방식이 아닌 의학 분야에서 언어 모델의 사용 가능성을 파악하는 데 있습니다. 때문에 실험을 위한 일관된 파이프라인을 설정하는 것이 중요하죠. 연구자들은 이 과정을 (a) 어떤 태스크를 다룰지 결정하고 (b) 프롬프팅 전략을 설정한 뒤 (c) 모델을 선택해 (d) 평가하는 과정으로 구분합니다.
모델이 다뤄야 하는 태스크는 크게 3가지입니다. ‘언어’ 모델이라는 특성에 맞춰 이를 기반으로 성능을 평가하지요. 이를 자세히 살펴볼까요?
이해 능력(Understanding)
모델이 보유하고 있는 의료 지식을 활용해 의료 개념을 이해하는 능력을 평가합니다. 이를 평가하기 위해 모델이 기사나 진단 보고서를 보고 의료 개념을 추출하거나 설명하도록 요구합니다. 이외에 핵심 의료 개념을 중심으로 간결하게 요약해야 하기도 합니다.
추론 능력(Reasoning)
앞서 이해 능력은 단순히 모델이 보유하고 있는 지식을 평가한다면, 추론은 그 지식을 활용해 얼마나 합리적인 결론을 도출하는지 평가합니다. 질문-응답 형식으로 다지선다형 질문에서 올바른 답을 택하는 형식이 기본이지만, 이는 우연히 정답을 도출할 가능성도 존재하죠. 최근에는 모델이 환자 정보를 기반으로 치료 제안하는 수준을 평가하기도 합니다. 그밖에 수학적 추론을 통해 정답을 계산해야 하는 문제도 존재합니다.
다국어 처리 능력(Multilinguality)
입력 지시나 출력 답변의 언어가 달라져도 태스크를 수행할 수 있는 모델의 능력을 평가합니다. XMedBench 데이터셋에는 중국어, 아랍어, 힌디어, 스페인어, 영어 등 6개 언어가 포함되어 있고, 각 언어로 된 의료 질문에 답해야 합니다.

o1 모델이 LancetQA 데이터셋에서 답을 추론하는 예시 출처: A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor? (Xie et al., 2024)
위의 태스크를 살펴보면 기본적으로 데이터셋마다 정답을 요구하는 방식이 다르기 때문에 실험 역시 이를 고려하려 설계됐습니다. 평가 지표 역시 각 데이터셋별로 다르게 나타납니다. 그렇다면 각 태스크에 대해 o1의 성능은 어떤지 의학 데이터셋에 실험한 벤치마크 점수를 비교해보겠습니다.
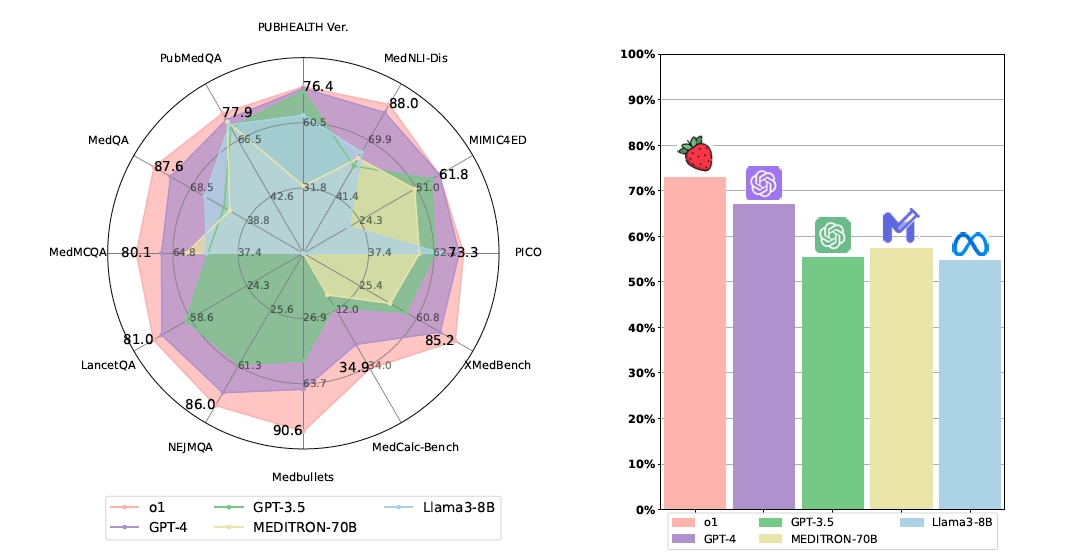
o1 모델과 그외 언어 모델을 비교한 결과 (좌) 데이터셋별 성능 분포 (우) 여러 데이터셋을 종합한 평균 정확도 출처: A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor?(Xie et al., 2024)
위 그래프에서 살펴볼 수 있듯이, 전체적으로 GPT 시리즈 모델의 성능을 상회하며 o1 모델이 가장 뛰어난 결과를 보여줍니다. 놀랍게도 평균 성능뿐만 아니라 어떤 분야에서도 o1을 넘어서는 단일 모델이 없습니다. 즉, 모든 지표에서 o1이 가장 좋은 성적을 보입니다.
특히 추론에 있어 진일보한 결과를 보여줬는데요. 다른 태스크에 비해 성능 개선이 가장 크게 일어나기도 했으며, 특히나 수학 평가 지표(MedCalc-Bench)에서 기존 모델에 비해 훨씬 뛰어난 성능을 보입니다. 이는 실제 진단 시뮬레이션 상황에서도 큰 이점을 얻을 수 있는 요소입니다. 연구진은 o1 모델 덕분에 ‘AI 의사’ 개발에 한층 더 다가갔다는 결론을 내립니다.
AI 의사가 해결해야 할 숙제
언어 모델의 한계만큼 AI 의사가 해결해야 할 문제는 여전히 존재합니다. 그중에서 가장 조심해야 하는 것은 환각(Hallucination) 현상입니다. 의학 분야는 환자의 안전과 직결되어 있기에 설명 가능하고 신뢰할 수 있는 모델을 개발해야 합니다. 아무리 성능이 뛰어나도 오류 가능성을 내포하고 있다면 실제 의료 현장에서 사용하기에 부적합하지요.
o1 모델은 다섯 개의 텍스트 요약 데이터셋에서 GPT-4에 비해 AlignScore가 1.3% 낮았습니다. 이는 o1 모델이 GPT-4보다 환각 현상이 더 많음을 나타냅니다. 이는 o1 모델이 다른 측면에서는 성능이 개선되었지만, 여전히 언어적 환각에 취약하다는 의미입니다.
그밖에도 영어에 비해 다중언어 태스크에서 추론 성능이 떨어지는 문제를 비롯해, o1의 느린 추론 속도, 모델 성능 지표에 과의존하는 문제 등을 고려해야 합니다. 추론 성능이 상대적으로 좋아진 것은 맞지만 아직 70%를 넘기는 수준이라는 점도 알고 있어야 하지요.
마치며
o1 모델이 의학 분야에서 얼마나 좋은 성능을 보일 수 있는지 살펴봤습니다. 모델 자체가 새롭게 학습하기보다는 추론 방식을 달리했기에 비약적인 개선은 어렵습니다. 하지만 o1 모델이 의학 분야에서 거둔 뛰어난 성적은 다른 분야에 대한 응용 가능성을 의미합니다. 현재는 모델 평가를 위한 프로세스를 구축했지만, 더 많은 정보를 주입하거나 의학 내 도메인마다 특화된 데이터를 학습할 수 있는 프로세스를 구축한다면 훨씬 훌륭한 보조 역할을 하지 않을까 싶습니다.


