

인공지능 기술은 보안 분야에도 적용되어 안전한 사회를 구축하기 위한 도구로 자리매김하고 있습니다.
인공지능 기술이 탑재된 CCTV는 기존의 단순 영상 녹화 및 재생의 기능을 벗어나 사람이 직접 CCTV 영상을 판별하지 않아도 자동으로 특정 객체를 구분 및 검출하고 영상의 필요한 부분을 표출해 줍니다.
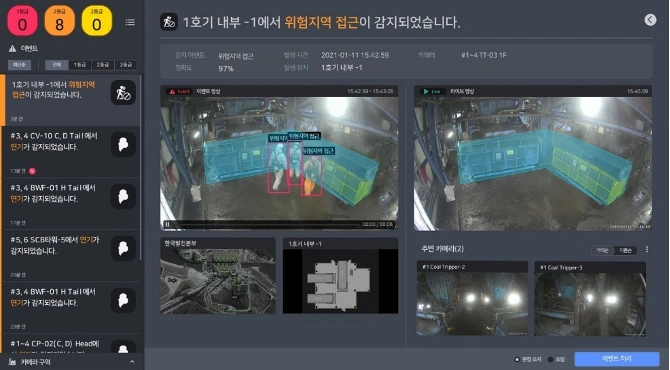
CCTV 영상 활용 기술(보행자 검출 및 추적) 예시 이미지 출처 : 동아일보 2021.04.28 “어둡고 좁은 발전소 내부도 ‘AI 영상분석’으로 위험 감지”
영상 보안 기술의 변화
기존의 지식 정보 보안산업의 분류에서 구분이 되었던 물리보안과 정보 보안은 제4차 산업혁명 과정에서 자연스럽게 경계가 허물어지고 융합되는 형태가 되었습니다. 이렇게 새로 등장한 분야를 융합보안이라 칭합니다.
이 분야는 현재 보안 산업의 핵심적인 역할을 담당하고 있습니다. 빠르게 성장하고 있는 융합보안 산업 시장에서 최근 가장 주목받고 있는 기술은 인공지능 CCTV 기술로 과거 물리보안 분야에서 CCTV나 카메라를 통해 입력된 영상을 이용하여 범죄 용의자 추적 및 검출하는데 활용되고 있습니다. 이러한 기술을 통해 과거의 단순한 감시 기능을 넘어 사회 전반에 걸쳐 안전망을 구축하는데 지대한 영향을 미치고 있습니다.
| 구분 | 정의 | 대표 제품군 |
| 정보보안 | 컴퓨터 또는 네트워크 상의 정보의 훼손, 변조, 유출 등을 방지하기 위한 보안제품 및 서비스 | 침입차단 시스템 |
| 물리보안 | 주요 시설의 안전한 운영과 재난, 재해, 범죄 등의 방지를 위한 보안제품 및 서비스 | 보안 관제 / CCTV |
| 융합보안 | 정보보안과 물리보안 간의 융합 또는 보안 기술이 ICT 기술산업과 융복합되어 창출되는 보안제품 및 기술 | 차량 블랙박스 |
지식정보보안 산업의 정의 (출처 : 산업통상자원부)
영상 보안 기술의 현주소
영상 보안 기술을 범죄 예방, 재난 재해 감시 등 국가, 개인, 기업의 유무형 자산 및 사람의 안전을 보호하기 위해 개발된 기술로 카메라(CCTV)를 활용한 영상 획득 기술, 디지털 정보 저장 및 전송 기술, 영상분석, 모니터링 및 인식 기술 등으로 크게 구분할 수 있으며 현재까지도 다양한 응용분야에 적용되며 발전되고 있습니다.
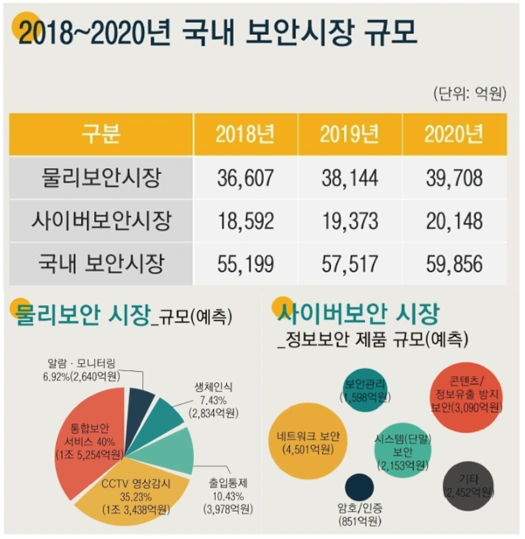
국내 보안시장 규모 이미지 예시1 (출처 : 2019 국내외 보안시장 전망보고서)
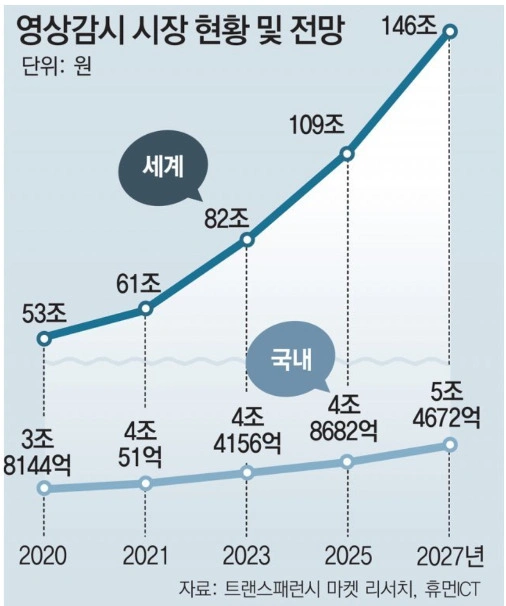
국내외 영상감시 시장 현황 및 전망 (출처 : 동아일보 2021.04.28 “어둡고 좁은 발전소 내부도 ‘AI 영상분석’으로 위험 감지”)
인공지능 CCTV 기술 - 1부
보행자 검출(Pedestrian Detection) 기술
보행자 검출 기술은 일반적인 객체 탐지 기술에서 특정 객체인 보행자만을 대상으로 하는 기술로 입력 영상의 모든 보행자를 구분하고 정확한 위치를 추정하는 것을 목표로 합니다.
보행자 검출은 CCTV 기반 영상 감시를 위한 다양한 응용기술의 기반기술이라고 할 수 있습니다. 최근 다양한 컴퓨터 비전 분야에서 사람 검출 및 추적 기술의 중요성이 증가하고 있습니다.
특히, CNN (Convolutional Neural Networks)의 강력한 추출 능력 덕분에 딥러닝 알고리즘은 기존의 기계학습 방식과 비교하여 매우 향상된 보행자 검출 능력을 보여줍니다.
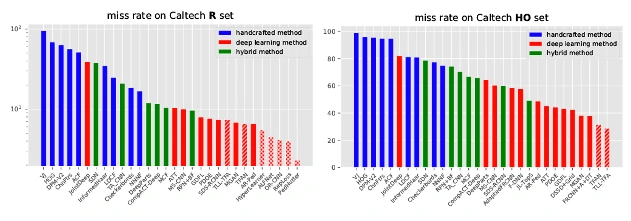
그림 4 향상된 딥러닝 기술을 보여주는 자료 예시 (출처 : From Handcrafted to Deep Features for Pedestrian Detection : A Survey)
CNN 기반의 객체 탐지 기술은 2단계 및 1단계 구조로 구분할 수 있습니다.
1단계 기반 알고리즘은 입력 영상으로부터 객체의 위치를 인식하고 종류를 판별하는 과정을 동시에 수행합니다. 반면, 2단계 기반의 객체 탐지 기술은 두 과정을 순차적으로 처리합니다.
2단계 기반 객체 탐지 기술
대표적인 2단계 기반의 객체 탐지 알고리즘인 Fater R-CNN은 관심 영역 제안 네트워크(RPN)을 제안하여 객체 후보 영역 제안 단계를 CNN을 통해 학습하도록 하였습니다. 이 결과 종단 간 학습 (End to End) 및 GPU 연산이 불가능한 기존의 기술의 문제점을 해결하였습니다. 관심 영역 제안 네트워크(RPN)는 사전에 정의된 다양한 비율의 앵커를 적용하여 객체를 검출합니다. 또 현재는 박스 형태로 객체를 탐지하는 것에서 나아가 각각의 객체를 픽셀 수준으로 검출하는 등으로의 확장 연구가 진행되었습니다.
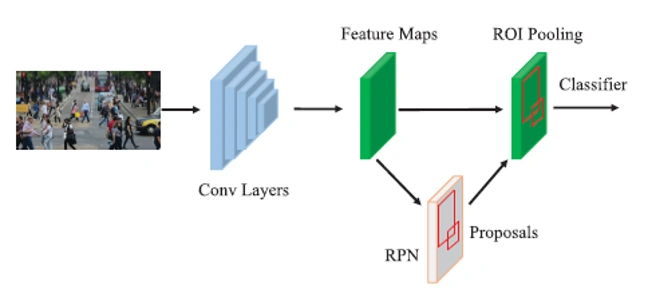
Faster R-CNN의 구조 (출처 : Occlusion Handling and Multi-Scale Pedestrian Detection Based on Deep Learning : A Review)
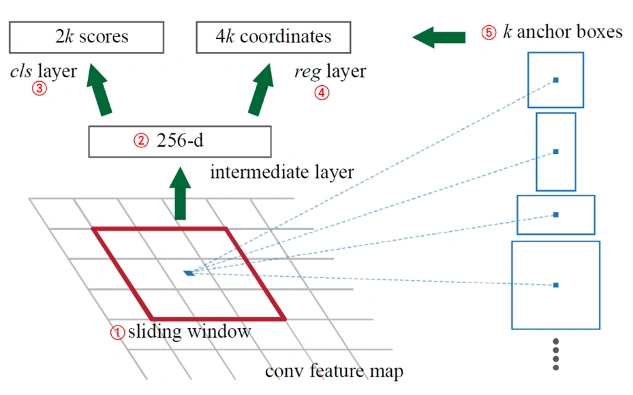
앵커 기반 RPN 구조 이미지 예시 (출처 : Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)
이런 2단계 기반의 객체 탐지 알고리즘은 객체의 위치 인식과 종류 검출을 순차적으로 수행하여 높은 객체 인식률을 갖는 장점이 있습니다. 그러나 많은 연산이 필요해 실시간으로 사용하지 못한다는 문제점이 존재합니다.
1단계 기반 객체 탐지 기술
1단계 기반 객체 탐지 기술은 실시간 구현이 어려운 2단계 기반 객체 탐지 알고리즘의 문제점을 해결하기 위해 제안되었습니다. 대표적인 1단계 기반 객체 검출 기술로는 YOLO(You Only Look Once)가 있습니다.
YOLO는 입력 영상을 균일한 그리드로 나누었을 때 CNN을 통해 각 그리드의 경계 박스 내부에 객체가 존재할 확률 값과 객체의 종류를 분류하기 위한 확률 값을 추출합니다.
즉, 하나의 CNN을 통해 위치 인식과 종류 판별을 동시에 예측하며 그 결과 실시간으로 객체 탐지를 수행할 수 있습니다.
계속 진화하는 객체 탐지 기술
1.Retina Net
Retina Net은 1단계 객체 탐지 학습과정에서 빈번히 발생하는 객체 영역과 배경 영역 간의 클래스 불균형 문제를 해결하기 위해 제시되었습니다. 분류하기 쉬운 예제에 적은 가중치를 부여하여 어려운 예제를 집중적으로 학습하는 방향으로 설계되었습니다.
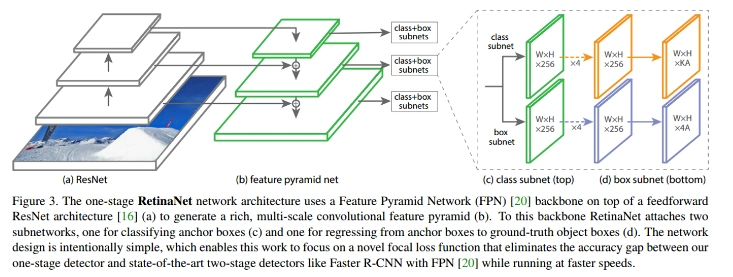
RetinaNet의 구조 이미지 예시 (출처: Focal Loss for Dense Object Detection)
2.Anchor-Free 객체 탐지 기술
기존의 2단계 및 1단계 객체 탐지 기술은 객체의 비율 및 크기를 표현하는 앵커 박스를 이용하여 객체 탐지를 수행합니다. 그러나 적절한 앵커의 형태를 위해 많은 변수를 인위적으로 조절해야 하며 모양 변화가 큰 객체를 효과적으로 검출하기는 어렵습니다. 이러한 기존 기술의 한계를 보완하기 위해 나온 Anchor-Free 객체 탐지 알고리즘은 사전에 정의된 앵커를 사용하지 않는 대신 CNN을 통해 객체의 특징점 등을 추출하여 객체의 위치와 종류를 판별합니다.

기존 기술과 Anchor-Free 기술 비교 이미지 예시 (출처: FoveaBox: Beyound Anchor-Based Object Detection)
보행자 추적 (Pedestrian Tracking) 기술 : 다중 객체 추적 (MOT, Multi-Object Tracking)
다중 객체 추적 기술은 입력 비디오 영상으로부터 다중 객체의 위치를 찾아 각 객체의 영상 내 동선을 따라가는 기술입니다. 입력 영상에서 객체의 위치를 박스의 좌표로 추정하는 탐지 기술과는 다르게 MOT 기술은 각 박스에 ID를 부여하여 다중 객체 간 신원을 구별해야 합니다.

MOT 기술 예시 이미지 (출처 : Online Multi-Object Tracking by Learning Discriminative Appearance with Fourier Transform and Partial Least Square Analysis)
일반적으로 MOT 기술은 검출 기반 추적(Tracking-by-Detection)을 통해 연구가 진행되었습니다. 이런 CNN 기반의 MOT 기술은 객체 탐지와 객체 연결이라는 두 단계의 프로세스로 구분되어 있었습니다. 이 결과 전체 입력 영상으로부터 객체 탐지를 위해 Back-Bone 네트워크 연산을 수행한 뒤, 추출된 객체 박스에서 다시 한번 추적을 위한 표현자 추출 연산을 수행하는 반복적인 과정을 거쳤습니다. 최근에는 이러한 반복을 줄이기 위해 통일된 Back-Bone 네트워크를 사용하는 공동 네트워크 구조가 제안되었고 관련 연구가 진행 중에 있습니다.
검출 기반 추적(Tracking-by-Detection)
검출 기반 추적의 일반적인 흐름은 모든 비디오 프레임에 객체 탐지 알고리즘을 적용한 후 탐지된 객체로부터 표현자를 추출하고 이를 이용한 객체 연결 과정으로 구성되어 있습니다.
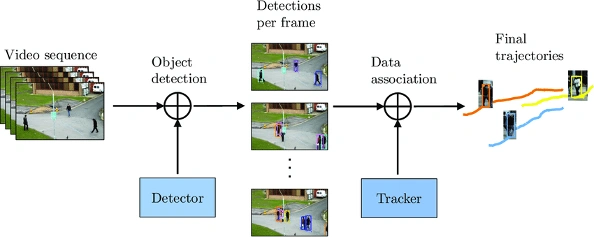
검출 기반 추적(Tracking-by-Detection) 흐름도 예시 이미지 (출처: Multiple object tracking with context awareness)
일반적으로 MOT 기술은 검출 기반 추적(Tracking-by-Detection)을 통해 연구가 진행되었습니다. 이런 CNN 기반의 MOT 기술은 객체 탐지와 객체 연결이라는 두 단계의 프로세스로 구분되어 있었습니다. 이 결과 전체 입력 영상으로부터 객체 탐지를 위해 Back-Bone 네트워크 연산을 수행한 뒤, 추출된 객체 박스에서 다시 한번 추적을 위한 표현자 추출 연산을 수행하는 반복적인 과정을 거쳤습니다. 최근에는 이러한 반복을 줄이기 위해 통일된 Back-Bone 네트워크를 사용하는 공동 네트워크 구조가 제안되었고 관련 연구가 진행 중에 있습니다.
마치며
전 세계를 막론하고 CCTV를 통한 영상 보안은 시설물 보호, 범죄 치안 예방, 교통안전 등을 위한 필수 장비가 되었습니다. 기존의 카메라 기술을 기반으로 최신 인공지능 기반의 기술 개발에 더욱 몰두한다면 글로벌 영상 보안 산업 분야에서 한 발짝 더 앞서 나갈 수 있을 것입니다. 지금까지 이러한 인공지능 CCTV 기술 중에서 보행자 검출 및 추적 기술에 대해 다뤄보았습니다. 2편에서는 인공지능을 활용한 여러 영상 보안 기술을 알아가는 시간을 갖도록 하겠습니다.
참고자료
Fang Li, Occlusion Handling and Multi-Scale Pedestrian Detection Based on Deep Learning: A Review, 2022
Tao Kong, FoveaBox: Beyound Anchor-Based Object Detection, 2020
Seong-Ho Lee, Online Multi-Object Tracking by Learning Discriminative Appearance with Fourier Transform and Partial Least Square Analysis , 2020
Tsung-Yi Lin, Focal Loss for Dense Object Detection, 2018
Shaoqing Ren, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016
Jiale Cao, From Handcrafted to Deep Features for Pedestrian Detection: A Survey, 2015
Laura Leal-Taixé, Multiple object tracking with context awareness, 2014
이건혁, “어둡고 좁은 발전소 내부도 ‘AI 영상분석’으로 위험 감지”, 2021
최희승, 인공지능 기술을 활용한 영상 보안 기술 소개, 2021
보안뉴스, 2019 국내외 보안시장 전망보고서


