
오늘은 GraphRAG 테크 시리즈 2편입니다.
지난 레터에서는 GraphRAG라는 프레임워크가 왜 필요한지, 그리고 어떤 구조로 구성되어 있는지를 살펴보았는데요. 오늘은 GraphRAG 설계 흐름의 다섯 가지 핵심 구성 요소 중 'Query Processor(처리)'와 '그래프 기반 검색(Retrieval)'이 어떻게 작동하는지를 알아보고자 합니다. 이 두 구성 요소는 구조화된 정보를 효과적으로 탐색하기 위한 필수 요소입니다.
왜 중요할까?
기존 RAG는 “스티브 잡스의 형은 누구야?”와 같은 질문을 임베딩한 뒤, 문서 벡터와의 유사도를 계산해 관련 정보를 검색하는 방식이었습니다. 반면, GraphRAG는 단순한 유사성 기반 검색을 넘어, 관계와 구조를 따라 정보를 탐색하지요. 이 과정에서 질문을 어떻게 해석할지, 그리고 그래프 내에서 어떤 방식으로 정보를 찾을지를 결정하는 요소가 바로 Query Processor와 Retriever 단계입니다.
1. Query Processor
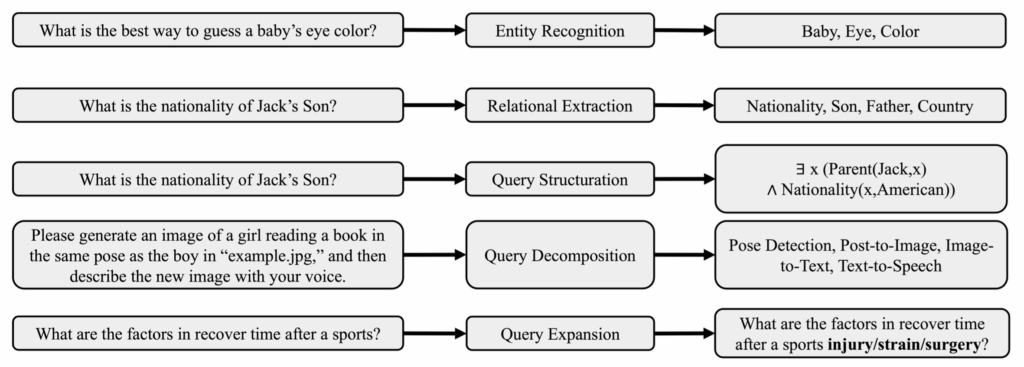
GraphRAG에서의 Query Processor는 텍스트 질의를 그래프 탐색에 적합한 형태로 변환하는 역할을 합니다. 단순 키워드 매칭이 아닌, 구조적 질의로의 해석이 필요한데요. Query 처리 과정 속 다섯 가지 주요 기술을 살펴볼까요? 🔎
1. 엔티티 인식 (Named Entity Recognition, NER)
질문 안에 포함된 인물, 장소, 개체명을 식별합니다. 기존 RAG에서는 텍스트 기반 지식베이스에서 엔티티를 추출했다면, GraphRAG에서는 그래프 내 노드로 연결 가능한 엔티티를 식별해야 합니다.
- 예: “스티브 잡스의 형은 누구야?” → ‘스티브 잡스’라는 노드를 그래프 내에서 찾는 과정
2. 관계 추출 (Relational Extraction)
문장에서 두 엔티티 간의 관계(Relation)를 식별합니다. 그래프에서 엣지(관계)로 표현되는 정보이며, 질의 해석 정확도에 매우 중요합니다.
- 예: “형은 누구야?” → 형제 관계(sibling_of)를 그래프 내 엣지로 매핑
3. 질의 구조화 (Query Structuration)
자연어 질의를 Cypher, SPARQL, GQL 등 그래프 쿼리 언어 형태로 변환합니다. 이는 복잡한 관계 탐색 시 유용하며, LLM 기반 자동 구조화도 함께 연구되고 있습니다.
4. 질의 분해 (Query Decomposition)
복잡한 질의를 여러 단계의 하위 질의로 분리합니다.
- 예: “A의 친구 중 B를 좋아하는 사람은 누구야?”와 같이 중첩된 질문에 대해 논리적으로 연결된 탐색 단계로 나누는 작업
5. 질의 확장 (Query Expansion)
질의에 포함되지 않은 잠재적인 관련 노드나 관계를 확장합니다.
- 예: “그 사람은 어떤 회사를 만들었어?”라는 질문에서 ‘그 사람’이 누구인지를 그래프 상의 이웃 노드를 통해 보완하는 방식
이와 같은 처리 방식은 단독으로 사용되기보다는 복합적으로 조합되어, 질의의 구조화 수준을 높이고 탐색 정확도를 향상시킵니다.
2. Retriever
1. 그래프 탐색 기반 검색
2. GNN(Graph Neural Network) 기반 임베딩 검색
3. Hybrid / Adaptive Retrieval
선택형(Multi-Choice) 및 b) 개방형(Open-Ended) 질문에 따른 KGARevion과 LLM의 정확도 비교.
지난 레터에서는 GraphRAG의 전반적인 개념과 필요성, 그리고 전체 구조를 소개했습니다. 특히 텍스트 기반 RAG로는 다루기 어려운 복잡한 관계형 데이터를 처리하기 위해, 그래프 구조와 탐색 방식이 왜 중요한지를 살펴봤지요.
오늘은 그 연장선에서, 질문을 구조적으로 해석하고 그래프 탐색으로 연결하는 Query Processor와 Retriever를 알아봤습니다. GraphRAG은 단순히 검색 정확도를 높이는 것을 넘어, ‘질문을 어떻게 구조화하느냐’에서부터 전체 흐름이 달라지는 프레임워크입니다.
다음 편에서는, 검색된 결과를 어떻게 정리하고(Organizer), 이를 생성기(Generator)와 어떻게 연결해 보다 일관성 있는 응답을 도출하는지 살펴볼 예정입니다. 다음주 레터도 기대해 주세요!🚀
참고자료


