시범 모델로 만들어본 3D 겨울 풍경. 멀티 턴(multi-turn) 대화를 통해 만들었다. 출처: 로블록스
최근 게임 회사 Roblox(로블록스)가 Cube 3D라는 3D 생성형 AI를 발표했습니다. Cube는 단순히 '텍스트를 입력해서 3D 객체를 만드는 모델'이 아닙니다. Cube는 3D 객체, 장면, 심지어 행동과 상호작용까지 이해하고 생성할 수 있는 AI 인프라의 첫 번째 단계입니다.
로블록스는 이를 '3D 지능(3D intelligence)'을 위한 Foundation Model이라고 부르며, 장기적으로는 모든 사용자가 단순한 입력만으로도 완전한 3D 경험을 만들 수 있기를 바랍니다. 정말 Cube로 우리만의 가상 세계를 만들 수 있는 걸까요?
핵심 기술: 3D를 '텍스트처럼' 다루는 방법
지금까지 AI는 텍스트, 이미지, 음성, 영상 생성에 집중되어 있었는데요. 위치, 크기, 방향뿐 아니라 형상, 표면, 재질, 구조도 포함하는 3D는 완전히 다른 도전입니다. 장면을 만들 경우에는 여러 객체가 맥락에 맞게 배치되어야 하지요. 나아가 3D 안에서 사람이 걷고, 문이 열리고, 자동차가 움직이려면 객체끼리 상호작용을 해야하기 때문에 단순히 '형태만 만드는 AI'로는 부족합니다. 로블록스는 여기에 필요한 기초 기술로 Cube 3D를 제시합니다.
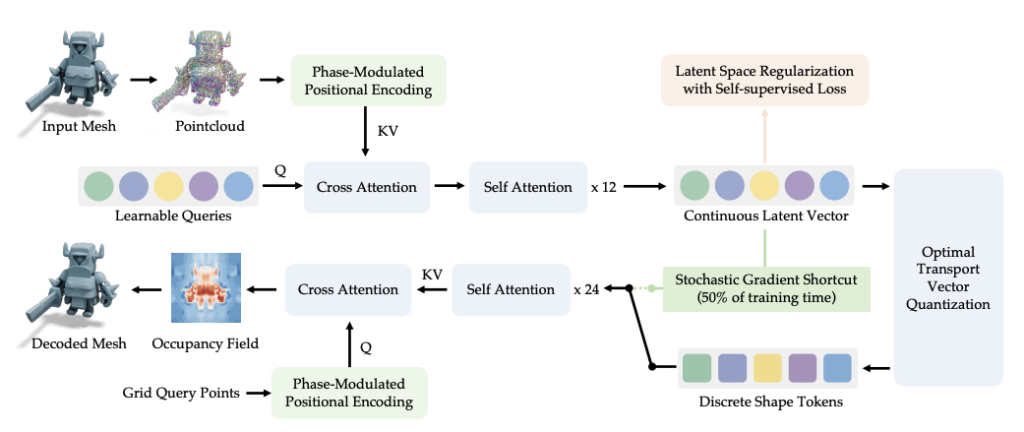
Shape tokenization 구조. 출처: 로블록스
Cube는 3D 데이터를 '텍스트처럼' 다룰 수 있다는 점에서 특별합니다. 이를 위해서는 우선 3D 형상(메쉬)을 토큰(token)으로 나눌 수 있어야 하지요.
텍스트 속 단어들이 이어져 문장이 되듯, Cube는 작은 3D 조각들이 이어져서 전체 객체를 이루는 전제입니다. 이는 Shape Tokenizer를 통해 가능한데요. 이는 3D 객체를 AI가 이해할 수 있는 단위로 나누는 기술이라고 볼 수 있습니다. 토큰화 시키는 과정을 간단하게 살펴볼까요?
3D 형상(메쉬)에서 점들을 샘플링해 pointcloud(점구름) 생성
점들의 위치 정보를 인코딩
►PMPE(Phase-Modulated Positional Encoding- 아래에서 살펴볼게요🔎)라는 기술을 써서, 점 사이의 거리나 구조가 유지되게 합니다.인코딩된 점들을 Transformer 구조로 처리해서 연속형 벡터(latent vector)를 생성
이 벡터들을 '토큰'으로 양자화(Vector Quantization)하여 연속되지 않은, 이산적인 형태로 변환
위 과정을 거치면, 텍스트처럼 토큰 시퀀스로 표현된 3D 객체가 만들어지니다. 이 때부터는 GPT처럼 이 토큰들을 예측하거나 생성할 수 있게 됩니다.
실제로 어떻게 쓰일까?
Cube 3D는 아래 질문 3개를 해결합니다.
☝🏼 텍스트 한 줄로 3D 물체를 만들 수 있을까?
✌🏼 3D 물체를 보고 텍스트로 설명을 해줄 수 있을까?
👌🏼 텍스트 한 줄로 캠프장, 사무실, 일식 레스토랑까지 만들 수 있을까?
이제, 앞선 인코딩 과정이 어떻게 실제 3D 생성 작업에 영향을 미치는지 살펴볼 시간입니다!
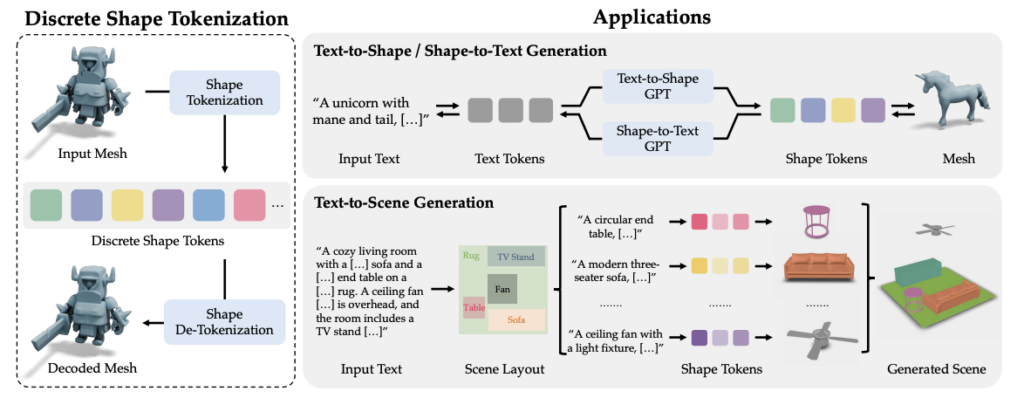
Cube 3D 기술의 활용. 출처: 로블록스
1️⃣ 텍스트 → 3D 오브젝트 생성 (Text-to-Shape)
예: A crystal blade fantasy sword (크리스탈 날을 가진 판타지 검)
- 입력 텍스트는 CLIP 모델로 인코딩되고, 트랜스포머가 Shape Token을 한 토큰씩 생성합니다. 마지막으로 메쉬를 복원하는 단계에서 Marching Cubes 알고리즘이 사용되지요.. 이 알고리즘은 점 구름 속에서 어디까지가 물체인지를 분석해, 그 표면을 삼각형으로 이어붙여 3D 모델을 완성해주는 역할을 합니다.
2️⃣ 3D → 텍스트 설명 생성 (Shape-to-Text)
예: 검 모양 3D 물체 → A fantasy sword with a crystal blade and gold handle
- 생성한 3D 객체를 설명하거나, LLM이 이해할 수 있도록 만들 때 중요한 기능입니다. Transformer + LLM + MLP projection 구조가 쓰이는데요. 짧은 설명부터 긴 설명까지, 프롬프트로 설명 길이를 조절할 수 있습니다.
객체를 텍스트로 변형하고, 다시 이 텍스트로 객체를 생성했을 때 대체로 원본과 유사한 객체를 재생성하는 shape cycle consistency 실험도 성공했습니다. 일부 고주파 디테일은 손실될 수 있으나, 객체의 핵심 형상 정보는 충분히 보존이 되었지요.

성공적인 shape cycle consistency 모습. 출처: 로블록스
3️⃣ 텍스트 → 장면 생성 (Text-to-Scene)
예: Make a Japanese garden with a pagoda and a pond와 같은 텍스트를 입력하면,
이를 바탕으로 관련 객체들(예: 정자, 연못 등)을 생성하고, 적절한 위치와 방향에 배치하여 전체 장면을 구성합니다.
텍스트 입력: 사용자의 텍스트가 LLM에 의해 처리됩니다.
Scene Graph 생성: LLM은 이 텍스트를 Scene Graph 형식(주로 JSON)으로 변환하여, 각 객체의 위치, 크기, 모양을 명시합니다.
Text-to-Shape: 각 오브젝트는 텍스트 설명을 바탕으로 Text-to-Shape 모델을 통해 3D 메쉬로 복원됩니다.
텍스처 적용: 최종적으로 오브젝트에 텍스처(질감)를 입히고, 장면 전체가 완성됩니다.
뿐만 아니라, 장면 분석 및 개선 제안도 가능한데요.
예를 들어, 60년대 스타일의 식당 장면을 보여주면 Cube는 그 장면을 요약한 다음, 아래와 같은 제안을 할 수 있습니다:
“어디에 조미료를 배치할까요?”
“이 공간에 어떤 스타일의 좌석을 추가하면 좋을까요?”
“배경 음악으로 어떤 분위기가 어울릴까요?”
이처럼 요약하고 필요한 부분을 자동으로 개선하는 제안을 하여, 사용자가 장면을 더 빠르고 쉽게 완성할 수 있도록 돕습니다.
PMPE란?
PMPE는 Cube의 3D 공간 이해에 중요한 역할을 하는 기술로, 기존 포지셔널 인코딩의 한계를 극복하기 위해 등장했습니다. 기존의 방식은 주기적인 패턴을 사용하여 공간을 인코딩하지만, 멀리 떨어진 점들을 동일한 벡터로 취급하는 경우가 많아 공간적 구분이 잘 되지 않았습니다. 특히, 3D 형상에서 점들 간의 정확한 거리를 인식하는 데 한계가 있었지요.
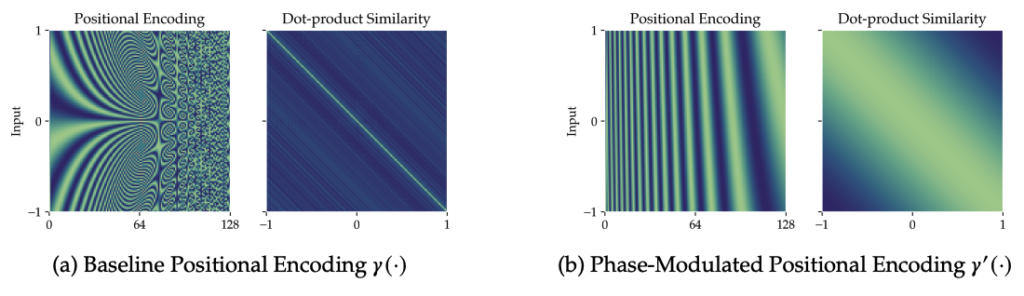
전통적인 인코딩과 PMPE 비교. 출처: 로블록스
위의 그림에서 보이듯, (a) 전통적인 포지셔널 인코딩(Positional Encoding)은 고주파 디테일을 잘 표현하지만, 점들 간의 거리 차이를 정확히 반영하지 못해 멀리 떨어진 점들을 비슷하게 인식하는 문제점이 있습니다.
PMPE는 이러한 문제를 해결하기 위해 위상 정보를 변형하여, 점들 간의 관계를 보다 정밀하게 반영할 수 있도록 했습니다. 점들의 위치 차이에 따라 인코딩 값을 다르게 조정함으로써 멀리 떨어진 점들 간의 구분을 가능하게 했는데요. 3D 공간 내에서 정확한 위치 정보가 유지되면서도, 기존 방식보다 디테일한 형상 복원이 가능해졌습니다.
AI 발전을 통해 현실 세계에서 많은 일이 쉬워지듯, 가상 세계에서도 많은 일이 쉬워지고 있습니다. 최근에는 AI의 빠른 발전으로 인한 부작용이 많이 드러나면서, 경각심과 두려움을 야기하기도 했는데요. 로블록스의 Cube 3D를 통해 만드는 가상 세계 이야기는 오랜만에 순수하게 미래를 기대하게 만드는 소식입니다.