
이번 아티클에서는 지난 11월 소개된 구글의 비전 분야 Generative AI를 살펴봅니다. Generative AI는 이용자의 요구에 따라 이미지, 텍스트, 코드 등의 창작물을 만들어내는 인공지능을 뜻합니다. 현재도 DALL·E 2, NovelAI 등 텍스트 기반으로 2D 이미지를 생성하는 서비스가 널리 활용되고 있지만, 기술 연구는 상용 서비스보다 한 발 빨리 3D 이미지와 영상을 생성하는 방향으로 진행되고 있습니다.
Image – Parti와 Imagen 그리고 DreamFusion
Parti와 Imagen은 텍스트를 입력값으로 받아 텍스트 설명에 맞는 이미지 생성 모델입니다. 두 모델은 이미지를 생성하는 방법에 차이가 있습니다. Parti는 이미지 생성 방식으로 ‘Autoregressive’ 방식을, Imagen은 ‘Diffusion’ 방식을 차용하고 있습니다.
Autoregressive 방식은 이전 예측값을 새로운 입력값으로 받아 다음 시퀀스를 예측하는 방식입니다. Parti는 입력된 텍스트를 기반으로 Encoder-Decoder 구조를 통해 지속적으로 다음 토큰을 생성합니다. 최종적으로 생성한 텍스트 토큰을 이미지로 변환하면 마침내 새로운 이미지가 생성됩니다.
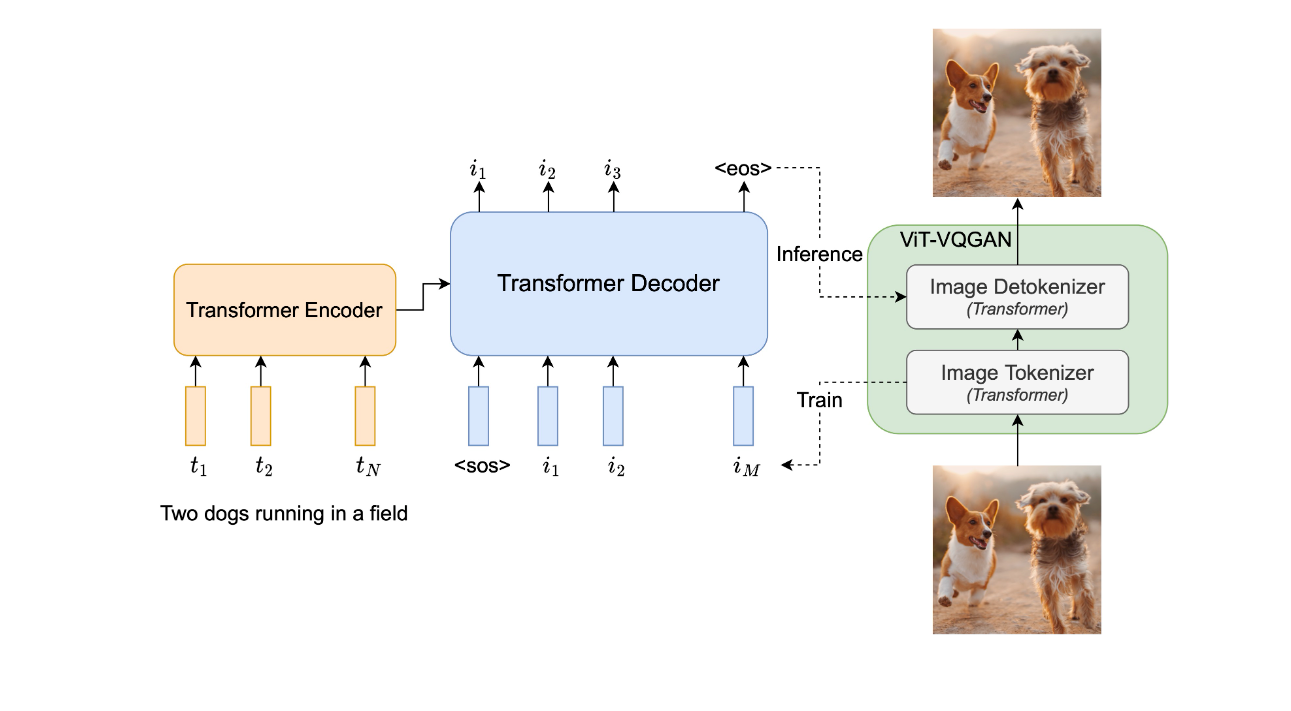
구글 Parti의 Encoder-Decoder 구조 (https://parti.research.google)
Diffusion은 원래 이미지에 노이즈를 더하고 이를 다시 제거하며 새로운 이미지를 생성하는 방식입니다. 노이즈를 더하고 제거하는 과정에서 이미지의 특성을 알아내고, 이를 결과물에 반영합니다. 구글은 Diffusion 모델과 ‘대규모 사전 훈련된 언어 모델’을 결합해 Imagen을 완성했습니다. ‘텍스트에 대한 깊은 이해’로부터 사실적인 이미지를 생성한다는 맥락입니다.
상대적으로 Parti는 텍스트 정보에 조금 더 민감하고 Imagen은 이미지 생성에 집중하는 경향이 있습니다. 구글은 Parti를 소개하며 “Parti와 Imagen은 각각 Autoregressive와 Diffusion이라는 두 가지 다른 생성 모델 제품군을 탐색하는 데 상호 보완적이며, 이 두 강력한 모델의 결합에 대한 흥미로운 기회를 열어준다”고 강조했습니다.
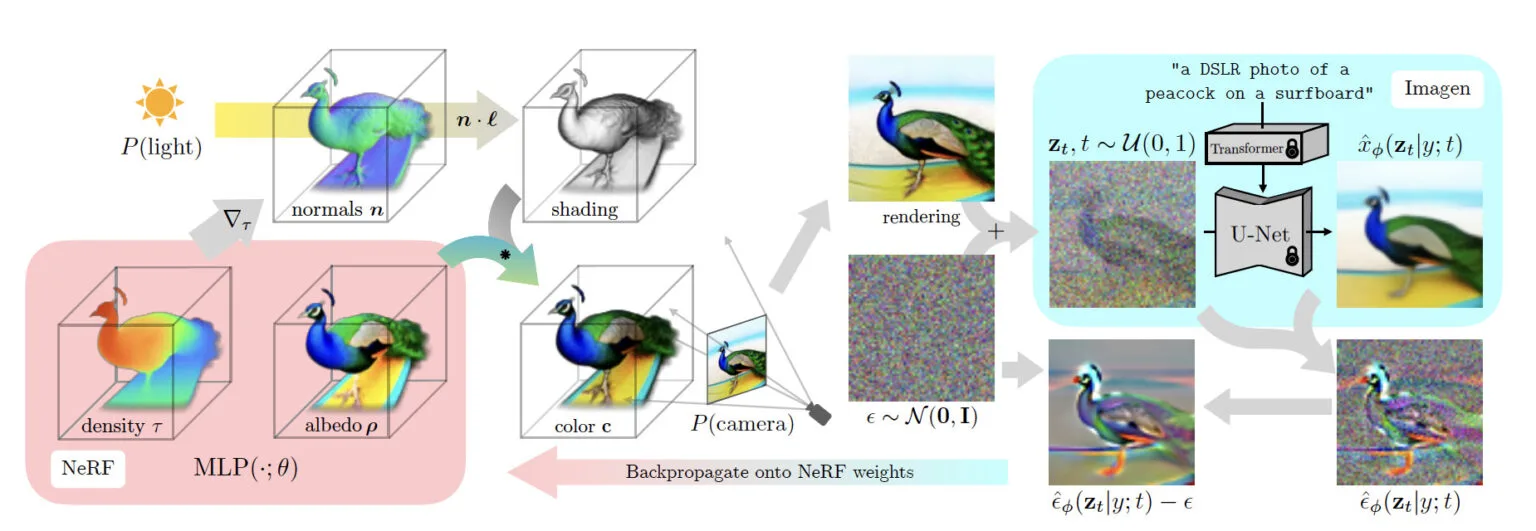
DreamFusion: Text-to-3D using 2D Diffusion (https://dreamfusion3d.github.io/)
DreamFusion
3D 렌더링 모델 NeRF가 올해의 트렌드로 자리매김 했습니다. 통상 NeRF를 통한 3D 렌더링 작업에는 양질의 2D 이미지가 필요한데요, DreamFusion은 2D 이미지없이 텍스트만으로 3D 모델을 생성하는 Text-to-3D 모델입니다.
DreamFusion은 NeRF와 Imagen을 함께 활용합니다. 우선 NeRF를 통해 임의의 각도에서 촬영한 3D Ray를 추출하고 밀도와 색상을 예측한 다음, 이를 기반으로 3D 모양과 빛을 비췄을 때의 그림자 모양을 예측하여 렌더링합니다.
DreamFusion에서 Imagen은 텍스트 기반 이미지 생성을 도와주는 역할입니다. 먼저 이미지 생성 과정에 텍스트 정보를 입력하여 텍스트와 그림 사이의 관계를 학습시킵니다. 그리고 렌더링된 2D 이미지에 노이즈를 더하고 제거하는 과정에서 더 좋은 이미지를 생성하는 방법을 학습합니다(위에서 설명한 Diffusion방식 입니다). 이렇게 얻은 정보는 다시 NeRF 모델로 넘어가 3D 렌더링 능력을 향상시킵니다.

Dreamfusion에 ‘다각형 모형의 게(a crab, low poly)‘를 입력한 3D 렌더링 결과
Video - Phenaki
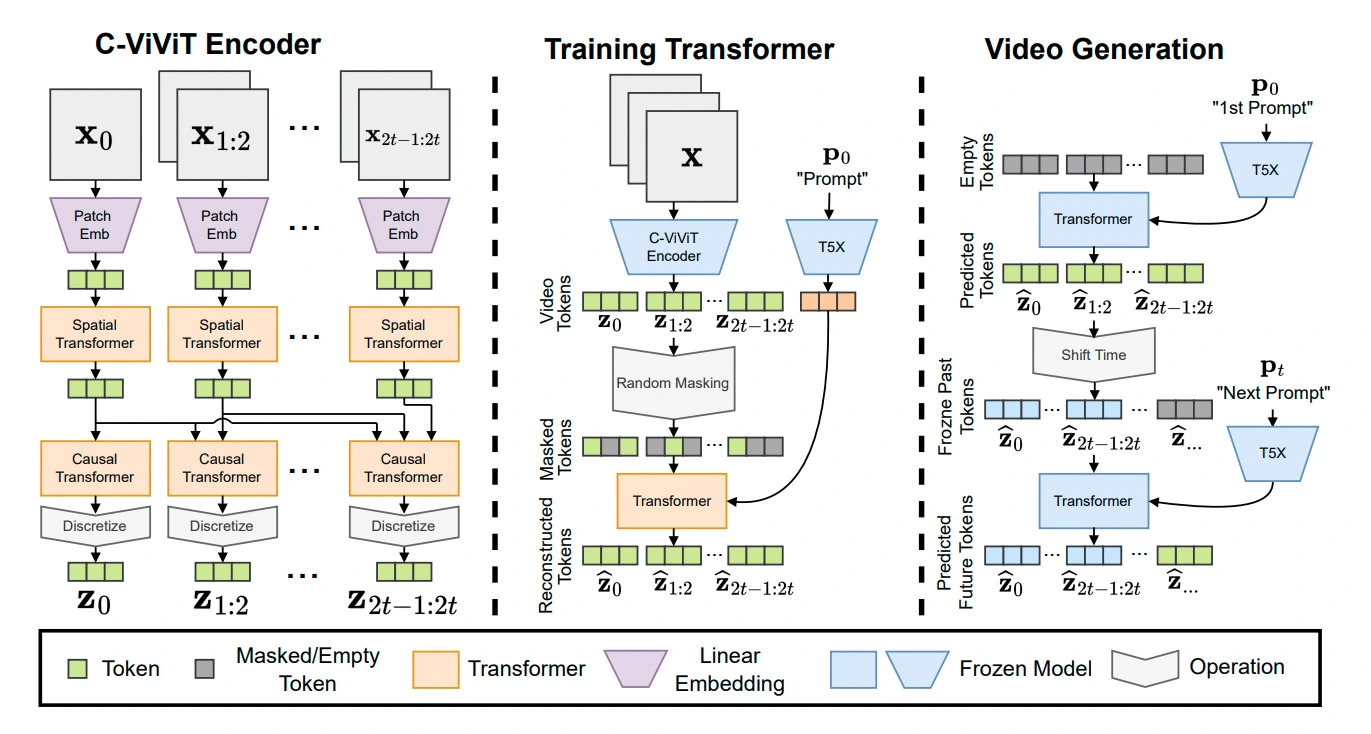
Phenaki (Villegas, 2022)
드디어 상상하는 대로 영상을 만들 수 있는 시대가 온 걸까요? 구글이 텍스트 설명에 알맞은 영상을 생성하는 모델 Phenaki를 선보였습니다.
영상은 이미지보다 생성하기 어렵습니다. 이미지에 비해 용량이 훨씬 크기 때문입니다. 통상 1초짜리 영상에 30장의 이미지가 포함되어 있으니까요. 텍스트로 영상을 생성할 때도 비슷한 어려움을 겪게 됩니다. 용량이 큰 영상은 이미지 및 텍스트와 일대일로 대응시키기 어렵습니다. 그래서 Phenaki는 비디오를 생성할 수 있는 작은 토큰을 만들어 압축하고 이를 복원하는 방식으로 학습을 진행합니다.
Phenaki는 영상을 작은 개별 토큰으로 압축하는 인코더와 압축된 토큰을 영상으로 복원하는 디코더로 구성돼 있습니다. 우선 인코더에서는 Autoregressive 방식으로 이미지와 비디오 패치 토큰을 인코딩합니다. 앞서 생성된 토큰이 다음 토큰에 반영되기 때문에 인과관계가 있는 Causal Transformer라고 합니다. 이후 인코딩된 이미지 토큰에 텍스트 정보를 결합합니다. 인코딩한 토큰의 일부를 가린 다음, 텍스트 토큰을 더해 원래 인코딩한 토큰을 예측하는 방식입니다.
프롬프트를 입력 받은 Phenaki가 생성한 영상 예시.

디코더에서는 인코더에서 생성한 토큰을 복원하며 영상을 생성합니다. Phenaki는 디코더 과정에서 이미지의 연속성을 부여하기 위해 이전 시점까지의 토큰은 고정시킨 후 다음 토큰을 생성합니다. 프롬프트의 내용이 이전과 달라진다고 하더라도(즉 스토리가 달라진다고 하더라도) 자연스러운 영상을 생성하기 위함입니다.
이렇듯 짧은 프롬프트로 2분짜리 영상도 만들 수 있습니다. 물론 아직은 상업적 이용이 가능한 수준은 아닙니다. 화질도 개선돼야 하고, 장면 간의 연결은 더욱 자연스러워야 합니다. 그럼에도 텍스트를 이해하고 이러한 수준의 영상이 생성된다는 점은 놀랍네요.
마치며
올해는 Generative AI의 해가 아닌가 싶을 정도로 뛰어난 생성 AI가 많이 등장했습니다. 멋진 모델 하나가 만들기 위해 다수의 모델이 종합적으로 활용되고 있었습니다. 특히 Transformer, Diffusion, NeRF 기반 모델들은 이전에 비해 훨씬 뛰어난 성능을 보이며 주류를 차지하고 있습니다. 새로운 기초 모델이 등장해 Generative AI 분야에 다시 한번 혁신을 가져올 수도 있겠습니다. 지금까지 구글의 Generative AI를 알아보았습니다.
*본 콘텐츠는 deep daiv. 와의 제휴로 구성 되었습니다.
참고자료
dreamfusion3d.github.io
parti.research.google
phenaki.video


