
임베딩 튜닝이란?
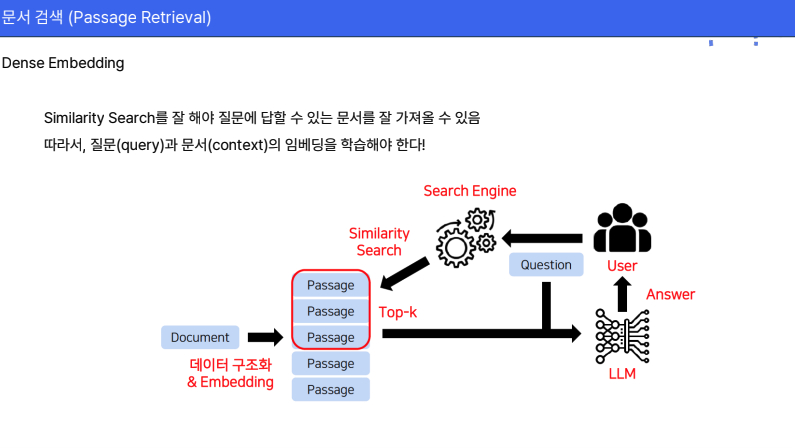
RAG는 데이터를 기반으로 AI가 사용자 질문에 맞는 적절한 답변을 생성이 가능하지만 기본적인 RAG 알고리즘만으로는 질문과 답변 청크 간 매칭 문제가 발생할 수 있습니다. 이는 특히 질문이 짧고, 답변 청크가 길 경우 더욱 두드러지게 나타납니다.
이를 해결하기 위해 임베딩 튜닝(Embedding Tuning)이 필요합니다. 임베딩 튜닝은 질문과 청크를 임베딩하는 모델의 알고리즘을 조정해 두 임베딩 간의 유사도를 극대화하는 과정입니다.
문제의 발생 : 질문과 패시지 간의 길이 차이
튜닝이 필요한 이유는 질문(Query)과 패시지(Passage)의 길이 차이에서 발생하는 문제를 해결하기 위함입니다.
- 질문(Query): 일반적으로 짧고 간결합니다. 예를 들어, “이 회사의 매출 성장률은?”과 같은 형태입니다.
- 패시지(Passage): 관련 정보를 포함한 문서로, 일반적으로 길고 상세합니다. 예를 들어, 해당 회사의 재무 보고서 일부가 될 수 있습니다.
이 두 데이터의 길이 차이로 인해 임베딩(Embedding) 공간에서 두 데이터가 적절히 매칭되지 못할 가능성이 큽니다. 질문은 간단한 형태로 임베딩되지만, Passage는 복잡하고 더 큰 임베딩 벡터로 표현되므로 유사성(Similarity) 계산에서 부정확한 결과가 발생할 수 있습니다.
임베딩 튜닝의 핵심
문서 검색 엔진 튜닝이란 질문과 Passage를 임베딩(숫자 벡터)으로 바꿔 비교할 때 오차가 생기지 않도록 검색 과정 전체(모델, 랭킹, 결과 정렬 등)를 손보는 것을 말합니다.
- 임베딩 모델의 기본 문제점 : 기본적으로 동일한 임베딩 모델을 사용해 질문과 Passage를 변환하지만, 질문(길이 짧음)과 Passage(길이 김)가 특성이 너무 달라서 동일한 모델로는 둘 사이의 차이를 제대로 반영하지 못할 수 있습니다.
- 튜닝의 역할
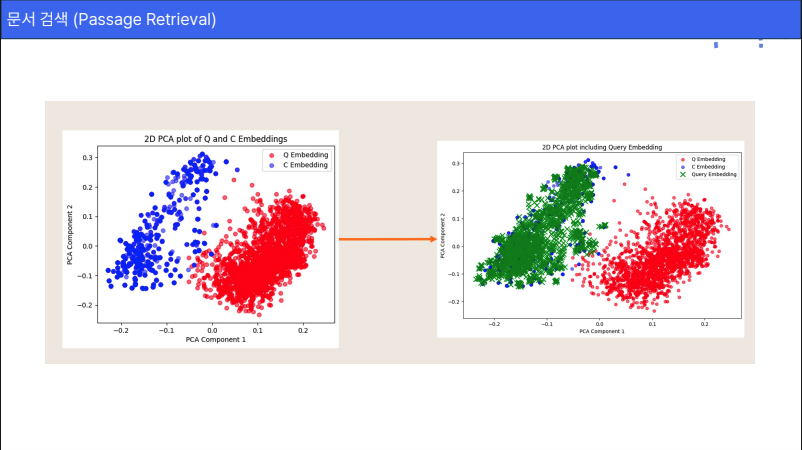
- 질문 임베딩과 Passage 임베딩의 분포 차이를 조정하여 더 나은 매칭이 이루어지도록 만듭니다. 위 그래프에 빨간 점(질문)과 파란 점(문서)이 적당히 섞여서 가깝게 보여야 좋은 검색 결과가 나오게 되는데, 임베딩 벡터 간의 거리를 학습을 통해 조정하는 ‘임베딩 튜닝’ 과정으로 분포 차이를 좁히게 됩니다.
- 이를 통해 서치 엔진은 질문에 대한 적합한 Passage를 더욱 정확하게 찾을 수 있습니다.
3. 튜닝 이후 성능 변화
튜닝 전후의 성능 차이는 데이터 분포와 매칭 정확성에서 확인할 수 있습니다.
- 튜닝 전
- 질문 임베딩과 Passage 임베딩이 적절히 매칭되지 않아 검색 결과의 신뢰도가 낮음.
- 질문과 관련 없는 Passage가 Top-k 후보로 선택될 가능성이 큼.
- 튜닝 후
- 질문 임베딩이 Passage 임베딩 분포에 적절히 매핑되면서 검색 결과가 개선됨.
- Top-k 검색 결과의 품질이 높아지고, RAG의 응답 정확도가 높아짐.
- 튜닝 전
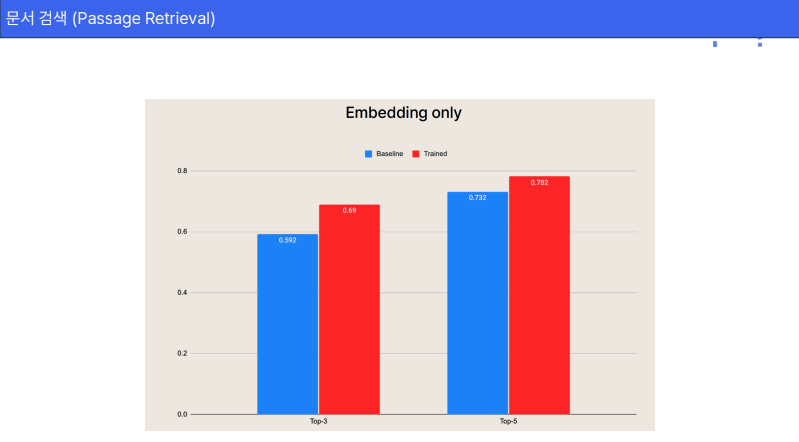
위 그래프에서 튜닝을 안한 베이스 라인(파랑)과 임베딩 모델을 튜닝한 트렌드(빨강) 그래프를 비교해보면, 임베팅 튜닝을 통해 성능을 극한으로 끌어올려 최대 10% 이상 향상 됨을 확일 할 수 있음.
- 임베딩 튜닝을 위한 데이터 준비와 학습 효과
임베딩 튜닝을 위해서는 질문과 모범적인 답변 패시지 쌍(Question-Context Pair)이 필요합니다. 예를 들면 “이 회사 매출 성장률은?”이라는 질문에 “OO회사의 연간 재무 보고서에 따르면 매출 성장률은 …”과 같은 답이 쌍을 이룬 데이터 말이죠. 이 데이터를 통해 서치 엔진을 학습시키면, 다음과 같은 결과를 기대할 수 있습니다.
- 질문과 Passage 간의 유사성 계산 정확도 향상
- 질문 특성에 맞는 Passage 선택 확률 증가
- RAG 시스템의 상한선 성능까지 도달
이처럼 문서 검색 서치 엔진 튜닝은 RAG 성능의 극한을 끌어올리기 위한 필수 단계입니다. 데이터 구조화로 기본을 다지고, 서치 알고리즘을 조정하여 질문과 Passage 간의 최적의 매칭을 구현한다면, 기업의 AI 응답 시스템은 보다 정확하고 신뢰할 수 있는 결과를 제공할 수 있습니다.


