*본 내용은 셀렉트스타의 '23/24 인공지능 인사이트' 매거진에서 발췌한 것입니다.
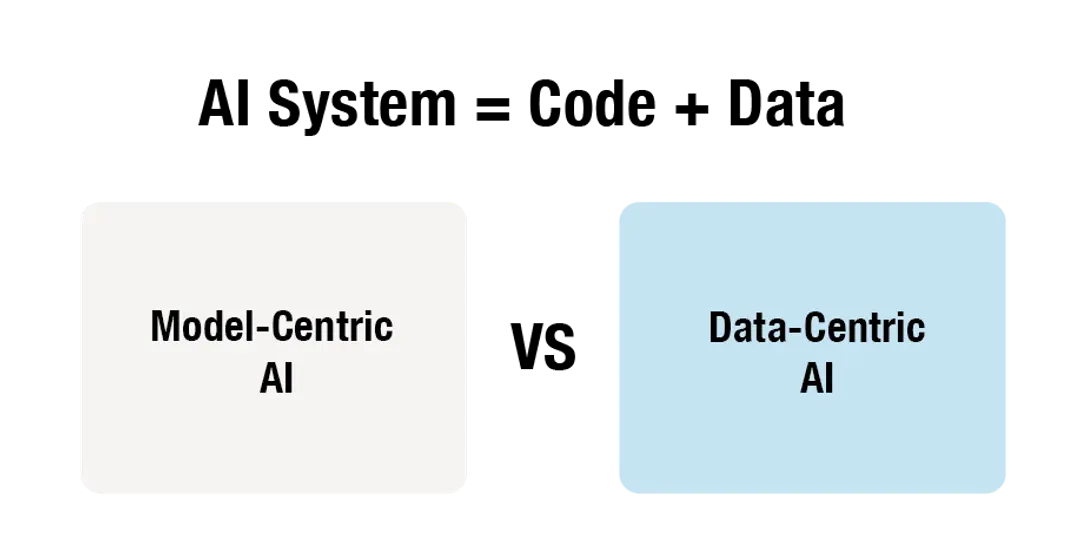
이런 다양한 솔루션들은 Model-centric AI 와 Data-centric AI, 두 가지 인공지능 모델 개발 방법론으로 요약됩니다. 모델 중심(Model-centric AI)은 알고리즘과 모델 구조 개선을 통해 AI 성능을 향상시 키는 방법이며, 데이터 중심(Data-centric AI)는 데이터 관점에서 AI 성능을 향상시키는 방법론입니다.
먼저 Model-centric AI은 모델이 훈련 데이터셋을 잘 학습할 수 있는 최적의 파라미터를 찾는 것이 목적입니다. 모델 개선을 위해 다양한 테크닉들이 적용될 수 있는데, 대표적으로는 규제(regularization), 드롭아웃(dropout), 배치 정규화(batch normalization) 등이 있습니다.
Data-centric AI에서는 먼저 훈련 데이터셋을 분석하고 데이터 품질을 향상시키는 과정이 선행됩니다. 이를 통해 데이터세트의 잠재적인 편향과 노이즈를 제거하고 데이터의 다양성을 높일 수 있습니다.
두 관점을 비교했을 때, 현시점에서는 ‘Data-Centric AI’가 업계 표준으로 여겨지고 있습니다. 인공지능이 데이터를 이해하고 처리하는 방식 및 구조(알고리즘)에 대한 연구는 이미 상당 수준 고도화 및 상향평준화 됐기 때문입니다. 이와 달리 인공지능 개발 목적에 꼭 맞는 ‘학습 데이터’를 구하는 일은 아직도 매우 어렵습니다. 데이터 허브·캐글(Kaggle) 등 기존 플랫폼에 공개된 데이터셋을 실제 상용 서비스 개발에 곧바로 적용하기는 부적절하며, 기업이 직접 데이터를 수집하고 가공하는 일에는 많은 시간과 비용이 들기 때문입니다.
이 ‘Data-Centric AI’ 패러다임을 메인스트림으로 가져온 기념비적 발표가 있습니다. 바로 2021년 3월 딥 러닝 AI(DeepLearningAI)의 수장 앤드류 응(Andrew Ng.) 교수가 공개한 ‘A Chat with Andrew on MLOps: From Model-centric to Data-centric AI’ 세션입니다. 인공지능 분야 세계 4대 석학으로 꼽히는 앤드류 응 교수는 미국 스탠퍼드 대학교(Stanford University) 교수이자, 기업 바이두(Baidu)의 부사장 겸 수석 과학자입니다.

출처: 유튜브 “MLOps에 대한 Andrew와의 채팅: 모델 중심에서 데이터 중심 AI로”
응 교수의 발표 내용을 요약하면 이렇습니다. “결함이 있는 철판을 찾는 AI 시스템을 개발하고 있다고 가정해 봅시다. 현 시점에서 시스템은 정확도 76.2%로 결함을 찾아낼 수 있고, 개발 목표는 정확도 90.0% 달성이다. 위 문제를 풀기 위해 모델과 데이터 중 어떤 것을 개선하는 것이 좋을까?(Model- Centric AI VS Data-Centric AI)”
실험 결과 AI 모델을 중심으로 성능 개선을 시도한 경우 정확도 증가는 0%p로 전혀 나아지지 않았다고 합니다. 반면 AI 학습 데이터를 중심으로 방식으 로 시스템을 개선했더니 정확도가 무려 16.9%p만큼 올라갔습니다. 다른 AI 시스템 사례를 보아도, 데이터 중심 접근이 비교적 우수한 성능을 보였습니다.
실제 학습 데이터를 살펴보면 데이터 품질 개선을 통해 AI 성능이 어떻게 향상되는지 알 수 있습니다.
예를 들어 이구아나 이미지를 감지하는 컴퓨터 비전 AI 시스템을 만들 때는 보통 사람이 가공 한 이미지 데이터가 필요합니다. 인공지능이 주변 사물과 이구아나를 정확히 구별할 수 있도록, 무엇이 이구아나고 무엇이 카멜레온인지 사람이 미리 분 류하고 표기해 놓은 라벨링 데이터요.

그렇다면 우리는 데이터 라벨러에게 3000장의 이구 아나 이미지를 보내, 이구아나가 있는 영역을 박스 로 표시해 달라고 요청할 수 있습니다. 작업자는 ‘ 이구아나가 위치한 영역을 박스로 표시해 주세요‘라 는 지시문을 읽고,사진속에서 두마리의 이구아나를 보게 됩니다. 하지만 이처럼 지시 사항이 간단하 다면 작업자마다 다른 기준을 적용할 위험이 있습니다.
먼저 라벨러A는 사진1처럼 이구아나 영역을겹치지않게각각따로바운딩박스를 그릴 수 있고, 라벨러 B는 사진2 처럼 왼쪽 이구아나 꼬리 까지 포함하는 긴 바운딩 박스 그린 다음 오른쪽 이구아나를 별도로 표시할 수 있습니다. 뿐만 아니라 라벨러 C는 사진3 처럼 이구아나를 구분하지 않고 두 마리 이구아나 영역을 박스 하나로 표시할 수도 있습니다.
위 예시는 학습 데이터의 일관성(consistency)이 부 족한 사례로, 머신러닝 알고리즘 성능에 치명적으로 작용합니다. 라벨러 A, B, C가 작업한 3가지 라벨링 데이터가 모두 잘못된 건 아닙니다. 다만 라벨러 3명 이 각각 다른 기준을 적용해 학습 데이터를 가공했 다는 점은 문제 될 수 있습니다. 학습 데이터에 일관성이 없다는 말은, 곧 해당 데이터를 학습한 AI 시스템이 일관성 없다는 뜻입니다.
알고리즘은 학습 데이터의 불량과 편향이 있으면, 그 불량과 편향까지 학습하여 결과물에 반영하게 되니까요. 각종 혐오 발언과 차별주의를 학습한 AI 시스템이, 윤리적 이슈로 서비스 중단된 사례는 어렵지 않게 찾아볼 수 있습니다.
앤드류 응 교수는 이처럼 AI 시스템에서 이슈가 발생 했을 때 많은 머신러닝 엔지니어들이 코드를 들여다 보며 문제를 찾고 해결하려 한다고 지적하며, 효율적인 해결을 위해선 데이터의 일관성을 높이고 라벨링 작업을 체계화해야 한다고 설명했습니다.