원천 데이터를 컴퓨터가 이해할 수 있는 숫자(벡터)로 바꾸는 과정에는 대표적으로 인코딩과 임베딩이 있습니다.
*본 내용은 셀렉트스타의 '23/24 인공지능 인사이트' 매거진에서 발췌한 것입니다.
퍼셉트론과 심층신경망, 그리고 인공지능 ‘학습’에 대해 순차적으로 설명해 봤습니다. 한데 수를 처리 하던 퍼셉트론은 어떻게 이구아나를 탐지하는 AI 시스템으로 발전할 수 있었을까요? 인공 지능은 어떻게 텍스트와 이미지, 오디오 데이터를 이해하고 처리할까요? 원천 데이터를 컴퓨터가 이해할 수 있는 숫자(벡터)로 바꾸는 과정에는 대표적으로 인코딩과 임베딩이 있습니다. 인코딩(Encoding)은 정보를 일정한 규칙에 따라 문자나 숫자로 변환하는 과정입니다. 문자를 바이트(byte)로 변환하는 유니코드(Unicode), ASCII 등 철자 인코딩(Character Encoding)이 대표적입니다. 임베딩은 이보다 한 발 나아가 데이터를 벡터 공간 상의 저차원 공간에 나타내는 것을 목적으로 합니다.
벡터의 차원 수는 벡터의 구성 요소 수를 뜻합니다. 예를 들어 2차원 벡터는 두 개의 구성 요소(x, y)로 이루어져 있으며, 3차원 벡터는 세 개의 구성 요소 (x, y, z)로 이루어져 있습니다. 임베딩을 사용하면 비교적 적은 수를 활용해 효율적으로 벡터화할 수 있습니다. 임베딩을 통해 단어 간의 유사도를 계산하거나, 단어들의 관계를 파악할 수도 있습니다. 예를 들어 ‘사과-애플’처럼 서로 표기가 다르고 의미가 같은 두 단어가 있다면, 두 단어 주변에는 유사한 단어가 분포할 것입니다. 이렇듯 자연어 처리 분야에서 는 텍스트 내 각 토큰(token, 최소 의미 단)의 의미와 위치 정보를 벡터 생성에 활용하곤 합니다.
요즘은 임베딩에 GPT처럼 사전 학습된 언어 모델 (pretrained language model)을 사용하는 게 일반적 입니다. 사전 학습(pre-trained)은 말 그대로 대량의 데이터셋으로 인공지능 모델을 먼저 학습시키는 방법을 의미합니다. 사전 학습된 모델은 기본적인 언어 이해 능력을 갖춘 범용 모델이 되며, 이후에 추가 학습이나 파인 튜닝(fine-tuning)을 통해 ChatGPT처 럼 특정한 작업을 수행하는 모델로 발전시킬 수 있 습니다(ChatGPT는 사전학습된 GPT-3 모델에 인간 피드백 강화 학습(HFRL)을 더해 만들어 졌습니다.).
시각 데이터를 처리하는 컴퓨터 비전 (computer vision) 분야에서 임베딩은 이미지를 숫자로 표현하는 기술입니다. 이미지는 텍스트와 달리 원천 데이터가 그 자체로 밀집행렬(Dense Matrix)라 고 볼 수 있습니다. 예를 들어 빨강(Red), 초록(Green), 파랑(Blue) 세 가 지 색을 합쳐 다양한 색상을 표현하는 RGB 환경에 서는,각픽셀 색깔이 숫자 세 개로 표현됩니다. 빨간 색(255, 0, 0) 초록색(0, 255, 0) 파란색(0, 0, 255) 등 색마다 고유한 값이 있죠.
하지만 모든 픽셀을 RGB 숫자로 표현하려면 지나치게 고차원·고밀도 데이터가 만들어집니다. 픽셀하나에숫자3개가필요하니까요.사진한장 을 표현하기 위해서는 엄청난 규모의 숫자 배열을 사용하기에, 매우 비효율적으로 데이터를 처리하고 연산하게 됩니다. 하여 이미지는 특징(feature)을 추 출하는 딥러닝 기술을 이용하여 벡터 형태로 변환합니다.
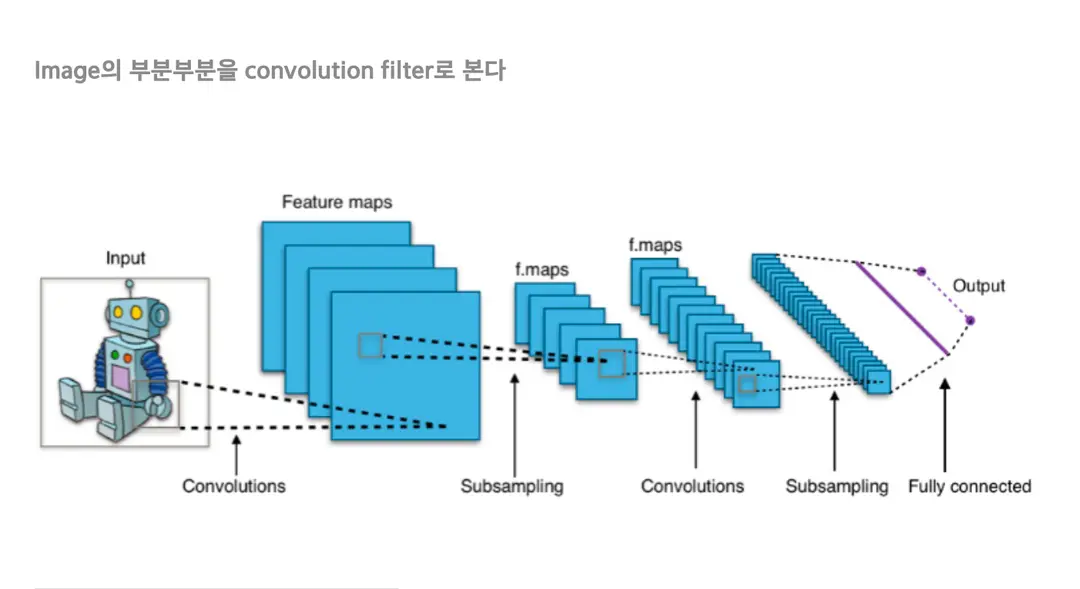
Image의 부분부분을 convolution filter로 본다
이미지 특징을 활용하는 가장 일반적인 방법 중 하나는 합성곱 신경망(Convolutional Neural Network, CNN)입니다. CNN은 풀링(pooling)과정과 컨볼루션 (convolution)과정을 이용하여 이미지의 특징을 추 출하고, 이를 고정 크기의 벡터로 변환합니다. 이러 한 방식으로 추출된 이미지 임베딩 벡터는 다양한 이미지 분류 및 검색 등에 활용될 수 있습니다.
VIT(Vision Transformer) 방식도 널리 쓰입니다. NLP 분야의 대표적인 모델 트랜스포머(Transformer)를 비전 분야 적용한 모델입니다. CNN과 달리 입력 이 미지에서 직접 특징을 추출하지 않고, 이미지를 패 치(Patch)라는 작은 부분으로 나눈 다음, 그 각각을 1차원 벡터 형태로 변환하고, 패치 사이의 관계를 학 습하여 이미지의 특징을 추출합니다.