문서 검색에서 Dense Passage Retrieval(DPR) 방식은 오랜 기간 동안 효과적인 검색 메커니즘으로 자리 잡아 왔습니다. 하지만 복잡한 질문이나 대규모 문서 데이터셋에서는 그 한계가 분명하게 나타납니다. 이러한 한계를 해결하기 위해 등장한 것이 RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval) 방식입니다.
RAPTOR와 DPR 비교부터 메타데이터 필터링까지, 데이터 검색 전략의 진화에 대해 자세히 알아보겠습니다.
DPR 방식의 구조와 한계
DPR 방식은 문서를 작은 청크(chunks)로 나눈 후, 각 청크를 임베딩(벡터화)하여 질문과 유사도를 계산하는 방법입니다.
주요 과정
- 문서를 청크로 나눔.
- 각 청크를 임베딩 벡터로 변환.
- 질문을 임베딩 벡터로 변환.
- 질문과 가장 유사한 Top-k 청크를 검색.
한계
- DPR은 질문과 직접적으로 관련된 청크만 검색하기 때문에, 다른 청크와의 관계를 고려하지 못함.
- 문서 간의 연관성을 놓쳐 복합적이고 맥락적인 질문에 약한 성능을 보임.
RAPTOR 방식의 개선점
RAPTOR는 단순히 질문과 유사한 청크를 찾는 것에서 벗어나, 문서 간의 연관성을 반영하고 계층적인 검색 구조를 제공합니다. 이는 트리(tree) 구조를 활용하여, 문서와 청크를 클러스터링하고 요약하여 더 높은 수준의 정보를 제공하는 방식입니다.
주요 특징
- Clustering: 유사한 청크를 묶어 클러스터를 생성.
- Summarization: 클러스터의 내용을 요약하여 중요한 정보만 추출.
- Tree 구조: 클러스터 간의 관계를 트리로 표현하여 계층적 검색을 가능하게 함.
장점
- 다층적 정보 검색: 트리 구조를 통해 청크 간의 관계를 탐색하며, 질문에 대해 더 풍부한 컨텍스트를 제공합니다.
- 복합 질문 대응: 여러 문서를 넘나드는 질문에도 효과적으로 대처할 수 있습니다.
- 검색 정확도 향상: 기존 DPR보다 더 높은 성능을 보이며, 의미적 연관성을 유지합니다.
RAPTOR vs. DPR 비교
RAPTOR 방식은 다양한 QA(Task)에서 DPR 대비 우수한 성능을 보였습니다. RAPTOR는 단순한 청크 기반 검색을 넘어, 트리 구조 내에서 다층적 컨텍스트를 생성하고, 질문과 연관된 정보를 계층적으로 탐색합니다.
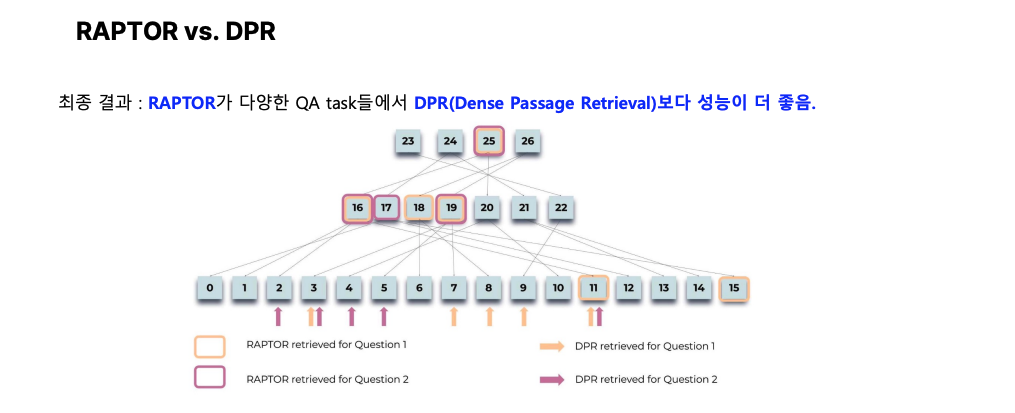
예를 들어:
- 질문 1: 신데렐라 스토리의 전체 주제는 무엇인가요?
- 질문 2: 신데렐라는 어떻게 해피 엔딩을 맞이했나요?
이 두 질문에 대해, RAPTOR는 트리 구조를 활용하여 관련 청크뿐 아니라 청크 간의 연결 정보까지 제공함으로써 더 정교한 답변을 생성합니다. 반면, DPR은 단일 청크 수준의 정보만 반환하여 맥락적으로 부족한 응답을 제공할 가능성이 큽니다.
성능 비교 결과
RAPTOR는 다양한 QA(Task)에서 DPR 대비 다음과 같은 성능 개선을 입증했습니다
- 더 높은 정확도와 F1 점수.
- Sparse 및 Dense Embedding 환경에서도 향상된 검색 품질.
메타데이터 필터링: 효율적인 검색 공간 축소 전략
현대 데이터 검색 시스템에서 방대한 양의 데이터를 효과적으로 다루기 위해, 메타데이터 필터링은 필수적인 전략으로 자리 잡고 있습니다. 메타데이터 필터링은 제목, 조건, 카테고리와 같은 부가 정보를 활용해 검색 공간을 제한하고, 더욱 정확하고 빠른 검색 결과를 제공하는 방법입니다.
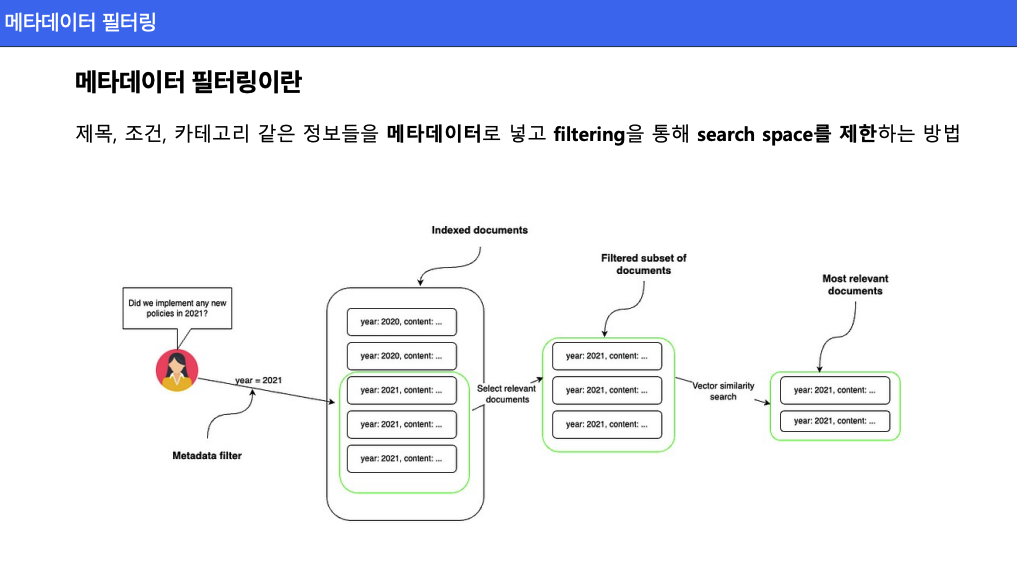
메타데이터 필터링의 작동 원리
- 검색 쿼리 분석
- 사용자가 입력한 질문에서 키워드 또는 조건을 추출합니다. 예를 들어, 사용자가 "2021년에 새로운 정책을 시행했나요?"라는 질문을 한다면, "2021년"이라는 메타데이터가 필터링의 기준이 됩니다.
- 메타데이터 기반 필터링
- 문서 데이터베이스에 저장된 메타데이터(예: 연도, 카테고리, 서비스명)를 기준으로, 관련된 문서만 필터링하여 검색 공간을 축소합니다.
- 유사도 기반 검색
- 필터링된 문서 집합에서 벡터 유사도 검색을 통해 최적의 문서를 추출합니다.

메타데이터 필터링 파이프라인
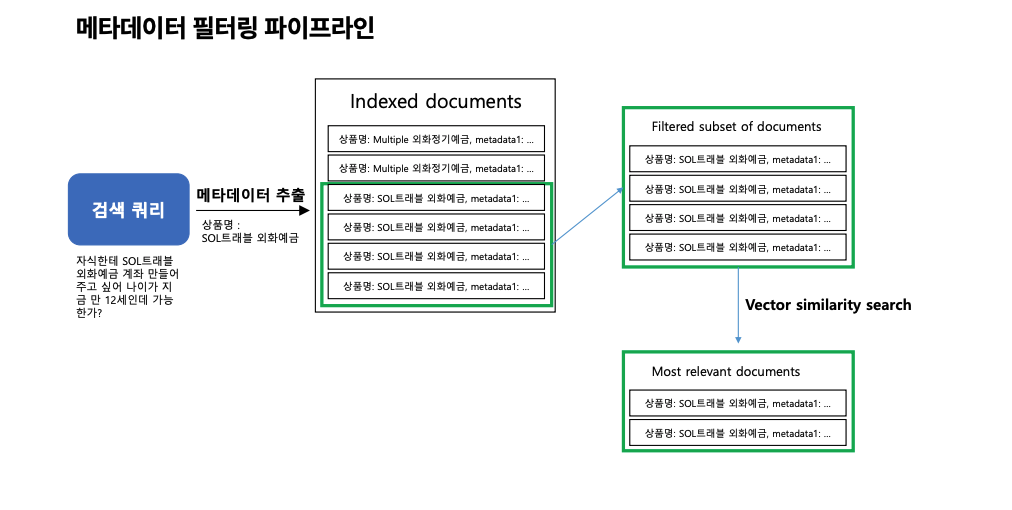
- Indexed Documents: 데이터베이스에 저장된 문서와 메타데이터.
- Filtered Subset of Documents: 메타데이터 필터링을 통해 조건에 맞는 문서들만 추려냄.
- Most Relevant Documents: 필터링된 문서 중 가장 관련성이 높은 문서를 유사도 기반 검색으로 최종 선택.
메타데이터 필터링의 장점
- 검색 속도 향상
- 전체 문서가 아닌, 필터링된 소규모 데이터 집합에서 검색을 수행하기 때문에 응답 속도가 대폭 향상됩니다.
- 검색 정확도 개선
- 불필요한 데이터가 배제되어, 사용자가 원하는 정보에 더 빠르게 도달할 수 있습니다.
- 성능 최적화
- Sparse, Dense, Hybrid 세 가지 모델 모두에서 메타데이터 필터링이 적용된 경우 성능이 향상되는 것으로 나타났습니다.
- 아래 성능 비교 그래프를 통해 메타데이터 필터링의 효율성을 확인할 수 있습니다.
메타데이터 필터링의 성능 비교
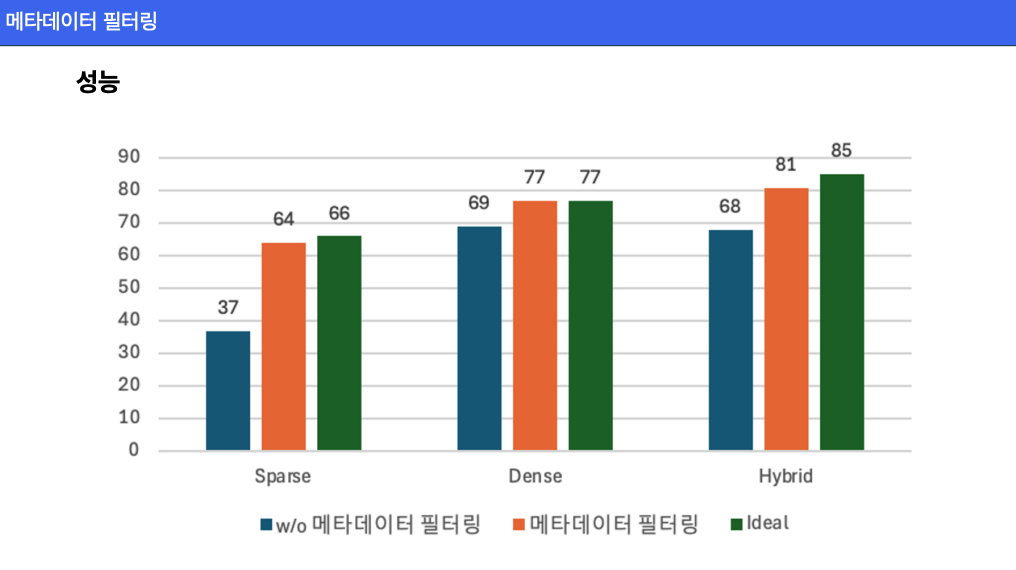
- 메타데이터 필터링을 적용하지 않은 경우와 적용한 경우를 비교했을 때, 검색 정확도와 속도가 눈에 띄게 향상됨.
- 특히, Hybrid 모델에서 필터링 적용 시 이상적인 결과(85점)에 가까운 성능을 달성.
메타데이터 필터링은 방대한 데이터 속에서 원하는 정보를 효율적으로 찾는 데 있어 필수적인 기술입니다. 검색 공간을 제한함으로써 응답 속도와 정확도를 동시에 향상시키는 이 전략은, 특히 대규모 데이터 환경에서 더욱 중요한 역할을 합니다. 앞으로 메타데이터 필터링과 같은 기술이 데이터 검색의 핵심으로 자리 잡으며, 다양한 분야에 적용될 것으로 기대됩니다.
전 세계적으로 의과대학은 왜 유독 과정이 길까요?
아마도 공부해야 할 양이 상당하기 때문일 텐데요. 의료는 복잡한 관계와 수많은 변수를 다루며, 그 안에서 정확하고 신뢰할 수 있는 결정(decision)을 내려야 합니다. 게다가 의료 정보는 방대할 뿐만 아니라 서로 다른 논문과 데이터베이스에 흩어져 있습니다. 필요한 정보를 찾고, 그 관계를 검증하며, 신뢰할 수 있는 결론을 도출하는 것은 결코 쉬운 일이 아닙니다.
이 문제를 해결하기 위해 하버드 대학을 포함한 연구진은 KGARevion 에이전트를 개발했습니다. KGARevion은 정보를 단순히 검색하는 것을 넘어, 관계를 명확히 검증하고 오류를 수정하며 신뢰할 수 있는 답변을 제공하는데요. 어떻게 문제를 해결하는지 살펴볼까요?
KGARevion 연구: 왜 필요했을까?
RAG의 한계
- 기존 RAG(Retrieval-Augmented Generation)는 문서를 찾아 답변을 생성하지만, 복잡한 관계를 명확히 설명하는 데 한계가 있습니다. 연관성으로 묶인 정보가 아닌, 독립된 정보 조각(chunk)을 검색하는 형식이기 때문인데요. 특히 의료처럼 복잡한 관계와 명확한 검증이 필요한 분야에서는 오류가 발생할 가능성이 큽니다.
LLM의 한계
- 지난 레터에서 본 것처럼, LLM은 환각이나 잘못된, 또는 깊이가 부족한 추론을 할 수 있습니다. 복잡한 논리를 따라가기에는 다소 어려움이 있습니다.
KG의 한계
- 지식 그래프(KG)는 명확한 관계 정보를 제공하지만, 자체적으로 질문에 답변을 생성할 수 없습니다. 찾는 정보 간의 관계를 알려줄 뿐이지요.
이 세 가지 문제에 대한 해결사를 자처한 KGARevion은 어떻게 작동할까요?
KGARevion이 일하는 방식
1. Generate (생성)
- (A) HSPA8
- (B) CRYAB
- (C) Heat Shock Protein 70
- 예시 Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
- (A) 예
- (B) 아니오
- 예시 Triplet: (Retinitis Pigmentosa 59, 관련 있음, HSPA8)
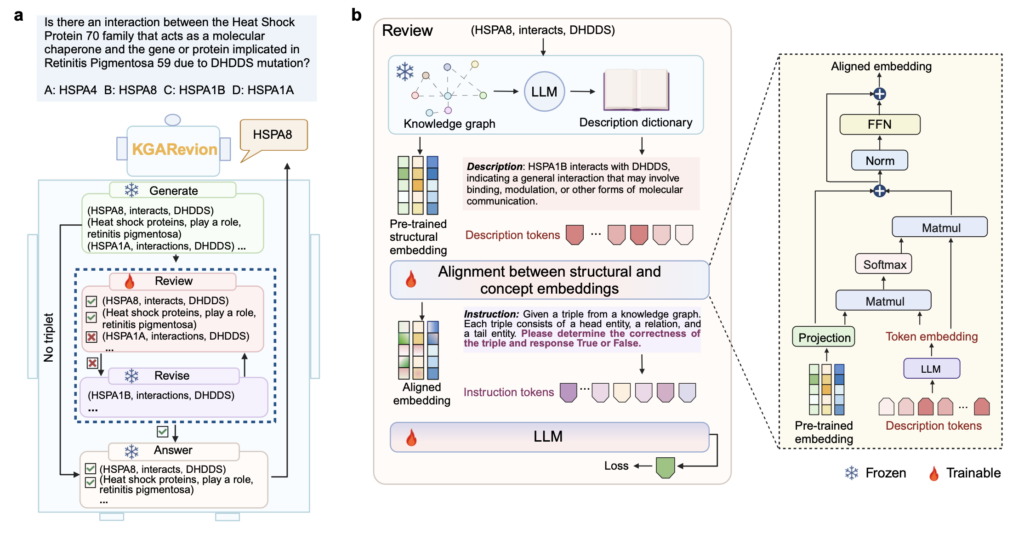
a) KGARevion 개요와 b) Review 단계에서의 파인튜닝 구조: KG는 구조적 임베딩을, LLM은 개념 임베딩을 제공.
2. Review (검증)

KG는 기존 지식 네트워크를 활용해 관계의 명확성을 확인합니다. KG에 해당 관계가 존재하는지, 이 관계는 신뢰할 수 있는지 등을 확인하지요.
검증 예시:
- Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
- KG 검증 결과: "HSPA8이 Retinitis Pigmentosa 59를 억제한다"라는 관계는 KG에서 확인되었으며, 신뢰할 수 있음.
- 오류 검출 예시: (Retinitis Pigmentosa 59, 촉진됨, HSPA8)
→ KG에서 확인되지 않아 오류로 판별.
3. Revise (수정)
KG에서 누락된 관계나 오류를 감지해 이를 수정하거나 보완하는 단계입니다. 교정한 정보에 기반해 LLM은 답변을 개선합니다.
- 초기 Triplet: (Retinitis Pigmentosa 59, 촉진됨, HSPA8)
- KG 검증 결과: 관계 오류 발견.
- 수정된 Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
4. Answer (답변 생성)
마지막으로, LLM을 통해 KG가 검증하고 보완한 정보를 바탕으로 자연스러운 답변을 생성합니다.
- Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
- 최종 답변: "HSPA8 단백질은 Retinitis Pigmentosa 59를 억제하는 데 기여할 가능성이 있습니다."
KGARevion, 얼마나 더 정확할까?
KGARevion은 의료 분야의 복잡한 질문에 대해 높은 정확도와 신뢰성을 입증했습니다. 논문 개요에 따르면, 기존의 의료 QA 데이터셋에서 평균 5.2%의 정확도 향상을 달성했으며, 새로운 QA 데이터셋에서는 최대 10.4%의 성능 개선을 보여주었습니다. 특히 다양한 질문 유형—선택형(Multi-Choice Reasoning)과 개방형(Open-Ended Reasoning)—에서 일관되게 높은 성능을 기록했는데요. 아래 그래프는 KGAREVION이 두 질문 유형에서 얼마나 일관되고 안정적인 성능을 보였는지를 시각적으로 보여줍니다.
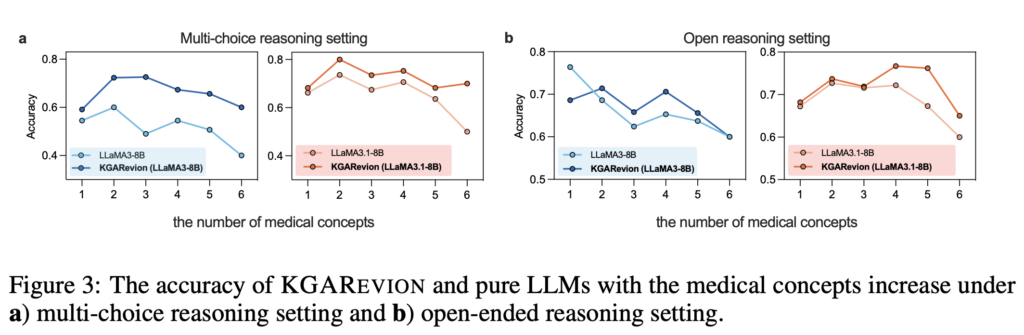
선택형(Multi-Choice) 및 b) 개방형(Open-Ended) 질문에 따른 KGARevion과 LLM의 정확도 비교.
기존 LLM이나 RAG 기반 모델들이 해결하기 어려웠던 다단계 추론 문제와 검증 오류를 KGARevion이 효과적으로 보완했다고 볼 수 있겠지요?
KGARevion은 복잡하고 신뢰성이 중요한 의료 분야에서 기존 LLM과 RAG의 한계를 뛰어넘는 에이전트입니다. 질문 유형에 따라 최적화된 Triplet을 생성한 뒤, 명확한 관계 검증과 오류 수정을 거쳐 정확하고 신뢰할 수 있는 답변을 제공하지요. 논문을 보면 다양한 의료 QA 데이터셋에서 성능을 개선한다는 결과를 볼 수 있는데요. 그만큼 무한한 잠재력을 가지고 있습니다.
올해 AI업계의 주요 키워드 중 하는 단연 '에이전트'라고 보는 눈이 많습니다. 다양한 에이전트의 출현과 활약을 더욱이 기대하게 만드는 KGARevion입니다.