
오픈AI가 최근 추론(reasoning) 모델 o3와 o4-mini를 공개했습니다. 지금까지 발표된 모델 중 가장 ‘지능적인’ 시스템으로 소개했는데요.
공식 발표에 따르면, o3와 o4-mini는 단순한 대화형 챗봇을 넘어, 웹 검색, 코드 실행, 이미지 해석, 이미지 생성까지 자율적으로 판단하고 결합해 문제를 해결하는 ‘AI 에이전트형’ 모델입니다.
하지만 '지브리 열풍'을 이끈지 얼마 되지 않아 나온 새로운 모델에 기대가 너무 컸던 걸까요? LLM의 가장 큰 고질병인 환각(hallucination) 문제가 화제입니다. 함께 알아보겠습니다.
o3와 o4-mini의 정확도와 환각률
오픈AI는 o3와 o4-mini 모델의 시스템 카드(system card)를 공개했습니다. 시스템 카드는 각 모델의 성능, 한계, 그리고 안전성 평가 결과 등을 기술적으로 정리한 문서인데요. 이 자료에 따르면 두 모델은 성능은 향상됐지만 환각률은 오히려 심하게 악화되었습니다.
아래는 PersonQA 벤치마크*로 평가한 검증 결과입니다. 새로 나온 두 모델 모두 작년 말에 출시한 o1 보다 2-3배 이상 환각 증세를 보이지요. o4-mini는 정확도도 o1 모델보다 떨어집니다.

정확도와 환각률 검사 결과, 출처: 오픈AI.
PersonQA(Person Question Answering)는 OpenAI가 내부적으로 만든 벤치마크로, AI 모델이 실존 인물에 관한 질문에 얼마나 정확하게 답하는지를 평가하기 위한 데이터셋입니다. 모델이 현실 세계 지식을 바탕으로 얼마나 신뢰성 있게 동작하는지를 평가하는 데 주로 사용됩니다.
- 예: “버락 오바마는 어느 해에 노벨 평화상을 받았나?”, “일론 머스크가 설립한 회사는?”
동시에 부정확하거나 환각된 정보도 더 많이 포함되었다.
그렇다면 왜.. 출시했을까?
정확도가 압도적으로 높아지지도, 환각률이 개선되지도 않았는데 왜 o3와 o4-mini를 출시한 걸까요?
o3: ‘더 많이 생각하는 모델’
o3는 reasoning-first 모델입니다. 질문에 즉각 반응하지 않고, 다양한 추론 전략을 시도하고 실수를 인식하며 도구를 조합해 최종 답변을 내놓지요.
오픈AI는 o3가 더 많은 주장을 하려는 성향이 있어, 정확한 주장과 환각이 함께 늘어날 수 있다고 추측합니다. 하지만 환각률은 절대적인 수를 떠나 상대적인 비율이기 때문에, 정확한 추측인지는 의문인데요. 그래도 옳은 주장도 늘었다는 건, 정답에 대한 시도도 늘었다는 의미로 해석할 수 있습니다.
o4-mini: ‘최고의 모델’이 아닌 ‘가성비 모델’
o4-mini는 처음부터 ‘최고 성능’을 최우선 목표로 한 모델이 아닙니다. 저렴하고 빠르며, 파이썬 등과 같은 도구와 병행하여 사용할 경우에 극적으로 성능이 향상되는 모델을 만들고자 한 결과지요.
o4-mini는 대량 API 요청에 적합한 경량 고속 모델로, 트래픽과 비용이 중요한 기업 환경에서 실용적 선택지가 될 수 있습니다. 즉, 성능이 부족해 보이지만 시장 내에서 나름의 역할을 고려한 전략적 제품이라고 볼 수 있습니다.
사실 두 모델은 환각률을 낮추기 위해 만든 모델은 아닙니다. 오픈AI가 강조한 바와 같이, 챗GPT 내에서 다양한 도구를 호출하여 코딩이나 이미지 해석, 수학 문제 풀이 능력 등을 ‘AI 에이전트’처럼 활용할 수 있는 모델이지요. 다만, 환각률로 인해 신뢰도가 많이 떨어질 수밖에 없습니다. 결국, AI 모델이 아무리 똑똑해져고 ‘얼마나 믿을 수 있는가’는 또 다른 문제입니다.
KG는 기존 지식 네트워크를 활용해 관계의 명확성을 확인합니다. KG에 해당 관계가 존재하는지, 이 관계는 신뢰할 수 있는지 등을 확인하지요.
검증 예시:
- Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
- KG 검증 결과: "HSPA8이 Retinitis Pigmentosa 59를 억제한다"라는 관계는 KG에서 확인되었으며, 신뢰할 수 있음.
- 오류 검출 예시: (Retinitis Pigmentosa 59, 촉진됨, HSPA8)
→ KG에서 확인되지 않아 오류로 판별.
3. Revise (수정)
KG에서 누락된 관계나 오류를 감지해 이를 수정하거나 보완하는 단계입니다. 교정한 정보에 기반해 LLM은 답변을 개선합니다.
- 초기 Triplet: (Retinitis Pigmentosa 59, 촉진됨, HSPA8)
- KG 검증 결과: 관계 오류 발견.
- 수정된 Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
4. Answer (답변 생성)
마지막으로, LLM을 통해 KG가 검증하고 보완한 정보를 바탕으로 자연스러운 답변을 생성합니다.
- Triplet: (Retinitis Pigmentosa 59, 억제됨, HSPA8)
- 최종 답변: "HSPA8 단백질은 Retinitis Pigmentosa 59를 억제하는 데 기여할 가능성이 있습니다."
LLM의 환각, 영원한 숙제일까?
KGARevion은 의료 분야의 복잡한 질문에 대해 높은 정확도와 신뢰성을 입증했습니다. 논문 개요에 따르면, 기존의 의료 QA 데이터셋에서 평균 5.2%의 정확도 향상을 달성했으며, 새로운 QA 데이터셋에서는 최대 10.4%의 성능 개선을 보여주었습니다. 특히 다양한 질문 유형—선택형(Multi-Choice Reasoning)과 개방형(Open-Ended Reasoning)—에서 일관되게 높은 성능을 기록했는데요. 아래 그래프는 KGAREVION이 두 질문 유형에서 얼마나 일관되고 안정적인 성능을 보였는지를 시각적으로 보여줍니다.
따라잡기 어려울 정도로 빠른 AI의 발전 속도가 무색하게, LLM의 환각은 여전한 골칫거리입니다. LLM의 정확성은 곧 서비스의 안전성와 기업의 이미지에 직결되는 문제이기 때문에 신뢰성 검증은 선택이 아닌 필수인데요.
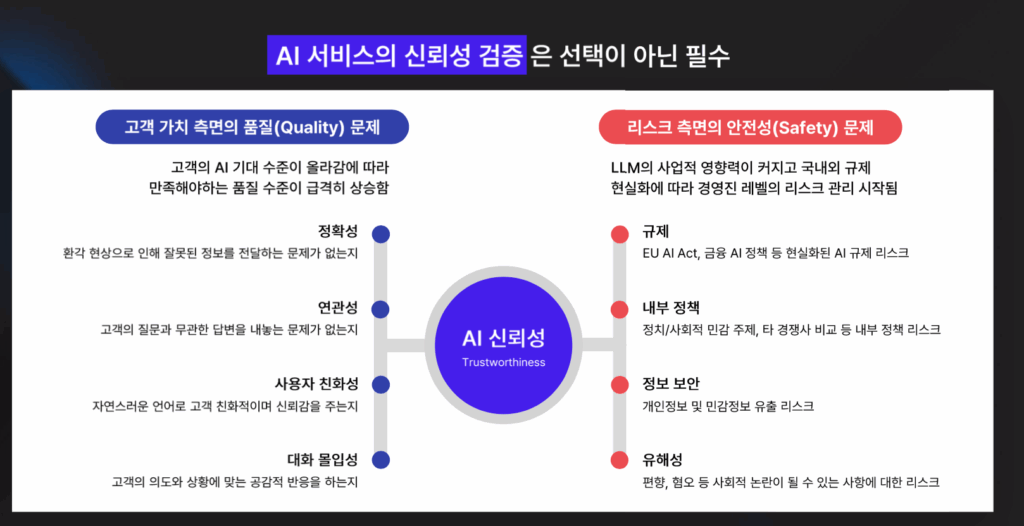
셀렉트스타는 국내 최초로 신뢰성 검증 과정을 자동화해 LLM, 혹은 LLM에 기반한 AI 서비스 안전성을 평가하는 플랫폼 다투모 이밸(Datumo Eval)을 개발했습니다.
환각은 물론, 편향성, 위법성, 개인정보 침해, 정보 충실성, 그리고 원하는 지표나 기준을 직접 선택하여 맞춤형 신뢰성 평가가 가능한 다투모 이밸을 통해 안심할 수 있는 서비스를 론칭하세요!


