
오픈AI가 GPT-4.1 모델 시리즈를 정식으로 발표했습니다.
GPT-4.1, GPT-4.1 Mini, GPT-4.1 Nano로 구성된 이번 라인업은 단순한 성능 개선을 넘어, AI의 실용성과 응답성을 크게 끌어올린 모델군입니다. 특히 코딩 정확도, 지시 이행 능력, 초장문(1백만 토큰) 문맥 이해 측면에서 GPT-4o 및 GPT-4.5를 능가하며, 현실적인 응용 분야에 강한 초점을 두고 설계되었습니다.
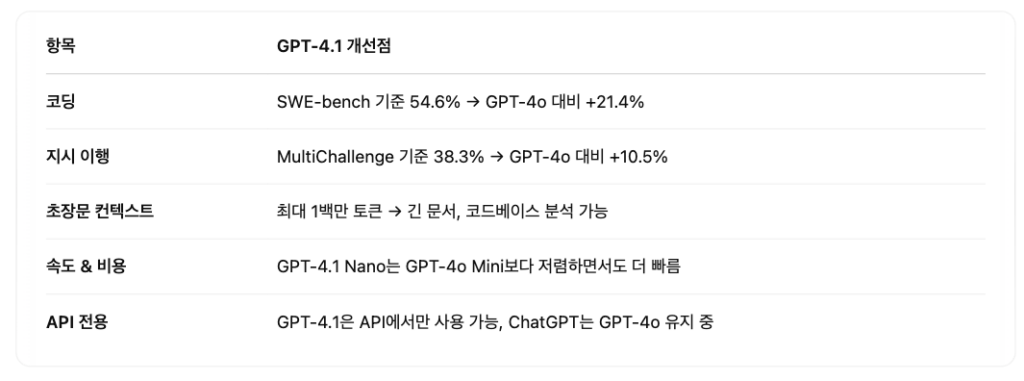
GPT-4.1 모델 시리즈는 API를 통해서만 제공되며, ChatGPT에서는 아직 사용할 수 없습니다. 현재 ChatGPT는 여전히 GPT-4o 기반입니다. 다만, GPT-4.1에서 훈련된 기능 일부는 추후 ChatGPT에 점진적으로 반영될 예정입니다.
달라진 GPT-4.1을 소개합니다
코딩: 실무에서 강해지다
GPT-4.1은 단순히 코드를 "잘 짜는" 수준을 넘어, 실제 개발 현장에 필요한 코드 리뷰, diff 포맷 적용, 프론트엔드 작성 등에서 의미 있는 개선을 보여줍니다.
SWE-bench Verified에서 54.6% 달성 (GPT-4o는 33.2%)
Aider polyglot diff benchmark에서 GPT-4.5보다도 더 높은 점수
불필요한 코드 수정 비율 9% → 2%로 감소
프론트엔드 앱 생성에서 GPT-4o보다 더 높은 미적 완성도 및 기능 구현 능력
특히 diff 포맷에 특화된 훈련은, 파일 전체를 재작성하지 않고 필요한 부분만 효율적으로 수정하는 데 큰 도움을 줍니다. 이는 대규모 코드베이스에서의 생산성 향상으로 직결됩니다.
지시 이행: 복잡하고 섬세한 지시도 가능
GPT-4.1은 단순한 ‘지시 따르기’를 넘어, 다음과 같은 복합 조건을 더 정확히 이해합니다:
형식 지시 (예: Markdown, YAML, XML 등)
부정 명령어 이해 (“지원팀에 연락하라고 하지 마세요”)
순서 의존 지시
정보 포함 필수 조건
오버컨피던스 방지 (“모르면 모른다고 말하라”)
OpenAI의 내부 평가에서 GPT-4.1은 복잡한 지시 세트(hard subset)에서 GPT-4o보다 20%포인트 가까이 향상된 성능을 기록했습니다. 실제 사례에서는 Blue J의 복잡한 세금 규정 처리 정확도가 53% 향상, Hex의 SQL 정확도 2배 증가 등이 있었습니다.
초장문 이해: 최대 100만 토큰까지
기존 GPT-4o가 128,000 토큰까지였던 것에 비해, GPT-4.1은 1,000,000 토큰 컨텍스트 윈도우를 제공합니다. 이건 무려 React 전체 코드베이스 8개 분량 이상을 한 번에 처리할 수 있는 수준입니다.
‘Needle-in-a-haystack’ 실험에서 GPT-4.1은 어떤 위치에 숨겨진 정보든 정확히 찾아냄
‘Graphwalks’ 벤치마크에서도 GPT-4o 대비 월등한 성능
법률 문서, 재무 데이터, 멀티문서 분석 등에서 실제 기업들이 의미 있는 향상을 경험
특히 Thomson Reuters와 Carlyle은 GPT-4.1을 통해 문서 간 논리적 연결성 유지, 다단계 추론에서 눈에 띄는 성능 향상을 얻었다고 밝혔습니다.
비전(Vision) 및 멀티모달 능력도 강화
GPT-4.1 Mini는 GPT-4o보다 시각 정보 이해력에서도 향상된 성능을 보여줍니다:
MathVista (시각 수학 문제): GPT-4.1 > GPT-4o
CharXiv Reasoning (과학 논문 차트 해석): GPT-4.1 > GPT-4o
Video-MME (자막 없는 긴 영상 이해): GPT-4.1 72.0% > GPT-4o 65.3%
이는 긴 영상 분석, 차트 기반 의사결정, 멀티모달 도큐먼트 자동화 등에 활용될 수 있습니다.
GPT-4.1은 단순히 더 똑똑한 모델이라기보다, 더 실용적이고 신뢰할 수 있는 파트너로 설계된 모델입니다. 특히 개발자와 기업이 요구하는 구체적인 사용성에 초점을 맞춘 구조는 실질적인 개발 워크플로우 개선으로 이어질 가능성이 큽니다.
지금까지 GPT 모델의 발전이 ‘무엇을 할 수 있는가’였다면, GPT-4.1은 ‘실제로 어떻게 쓸 것인가’에 대한 가장 구체적인 대답이라 할 수 있습니다.


