
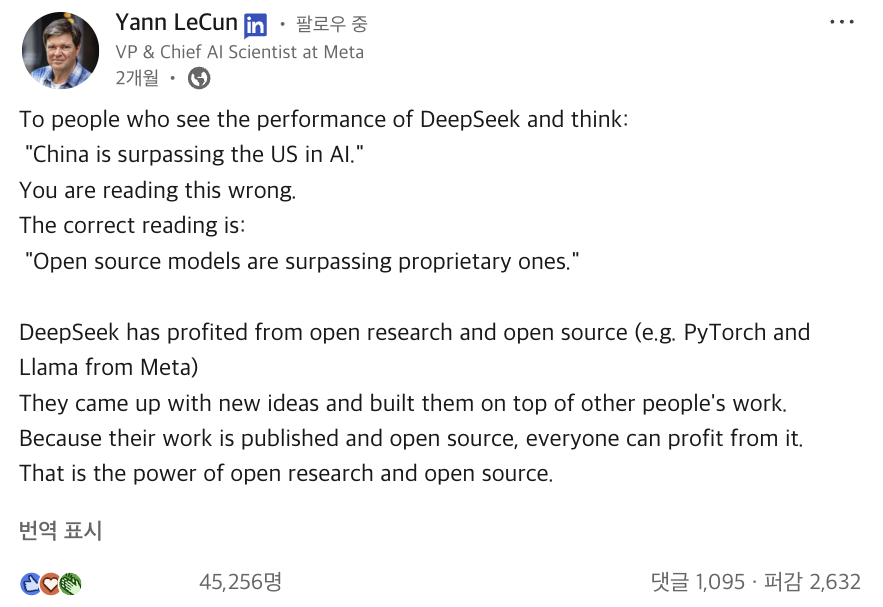
메타AI를 이끄는 얀 르쿤이 ‘딥시크 쇼크’ 당시에 올린 포스트입니다.

메타AI는 시작부터 공개된 연구를 지지해왔습니다. 그 모토에 맞에 이번에 Llama 4 시리즈를 open-weight으로 공개했는데요. 차근차근 살펴보겠습니다.
Llama 4 시리즈를 알아보자

이번 Llama 4 시리즈로 공개된 모델은 세 가지입니다.
- Llama 4 Scout: 17B active parameters, 16 experts 기반. 고성능 경량 모델
- Llama 4 Maverick: 17B active parameters, 128 experts 기반. 멀티모달+코딩 특화 범용 모델
- Llama 4 Behemoth: 288B active parameters, 총 2조 파라미터.(훈련 중, 미공개)
이 중 Behemoth는 Scout과 Maverick 모델의 '선생' 모델 역할을 수행했습니다. Behemoth는 초거대 모델로서, 훈련 과정에서 Scout과 Maverick에게 고급 추론, 코딩, 멀티모달 이해 능력을 전수했는데요. 아래에서 좀더 알아보겠습니다.
Scout과 Maverick은 오픈 가중치(Open Weights) 형태로 공개되어 누구나 다운로드해 파인튜닝하거나 응용할 수 있습니다. 단, 학습 코드와 데이터셋은 공개되지 않았기에 완전한 오픈소스라고 볼 수는 없습니다.
Llama 4 기술 이야기
1. Mixture-of-Experts (MoE) 아키텍처
Llama 4 시리즈는 Scout과 Maverick 모두 메타 처음으로 Mixture-of-Experts(MoE) 아키텍처를 채택했습니다.
Scout은 16개, Maverick은 128개의 experts를 보유하고 있습니다. 여기서 expert란, 입력에 따라 선택적으로 호출되는 작은 전문가 네트워크를 뜻하는데요. 모든 expert를 다 쓰는 대신, 입력에 따라 일부 expert만 활성화하는 방식으로 높은 효율성과 성능을 동시에 달성했습니다. 덕분에 두 모델 모두 성능 대비 계산 효율이 뛰어납니다. 또한, 단일 NVIDIA H100 GPU 서버에서도 가볍게 운용할 수 있습니다.
2. 네이티브 멀티모달 모델
Scout과 Maverick은 처음부터 텍스트와 이미지를 함께 처리하는 멀티모달 모델로 설계되었습니다. 텍스트 토큰과 이미지 패치를 초기 융합(early fusion) 방식으로 합쳐 단일 backbone 위에서 함께 학습된 모델인데요. 텍스트와 이미지를 동시에 입력으로 받을 수 있고, 이미지 내 특정 영역에 대한 grounding, 즉 이미지 속 정확한 위치나 대상과 텍스트 질의를 연결시키는 작업도 지원합니다. 두 모델은 최대 48개의 이미지까지 입력으로 수용 가능하며, 멀티이미지 추론과 비전-언어 복합 태스크에 강합니다.
3. 10M 토큰 초장기 문맥 (Long Context)
Scout은 무려 10M tokens 길이의 초장기 문맥 처리가 가능합니다. 이는 Llama 3의 128K 토큰 대비 약 80배, Gemini 1.5 Pro(1M tokens) 대비 10배나 긴 수준입니다.
비결은 기존 RoPE(rotary positional embedding)를 확장한 iRoPE(interleaved RoPE) 구조에 있습니다. 긴 문맥에서도 정보 손실 없이 추론할 수 있도록, 포지셔널 임베딩 없이 interleaved attention layer를 적용해 일반화 성능을 강화했습니다. 이제는 수백 개 문서를 통합 요약하거나, 대형 코드베이스를 분석·검색하거나, 사용자 기록에 기반한 개인화된 추론이 가능합니다.
4. Codistillation: Behemoth로부터 지식을 이식
Scout과 Maverick은 Meta 내부 초거대 ‘선생’ 모델인 Behemoth로부터 codistillation 학습을 받았습니다. 단순히 정답만 맞추는 게 아니라, 선생 모델에 해당하는 Behemoth가 출력하는 답변을 배우는 방식인데요. 선생 모델이 예측하는 ‘soft label(확률 분포)’까지 학습에 반영하기 때문에 Scout과 Maverick은 단순 암기형 모델이 아닌, Behemoth의 깊은 추론, 코딩, 멀티모달 이해 방식을 흡수한 ‘제자’라고 볼 수 있습니다.
✋🏼여기서 잠깐!
딥시크는 Codistillation과 비슷하지만 다른 Knowledge Distillation을 사용했습니다. 더 크고 똑똑한 ‘선생’ 모델로부터 지식을 증류(distill)해서 작고 빠른 ‘제자’ 모델을 만드는 걸 주요 전략으로 삼았는데요. 딥시크는 상대적으로 선생 모델 의존을 점진적으로 줄이는 Knowledge Distillation 방식을, Llama 4는 선생 모델과 끝까지 병행하는 Codistillation 방식을 전략으로 삼았다는 차이가 있습니다.
Codistillation: Compute을 더 많이 요구하지만, 제자 모델 품질이 올라감
Knowledge Distillation: 학습 효율이 높지만, 선생 모델을 완전히 따라잡긴 어려움
Meta만의 포인트
- 편향 문제 해결
메타는 이번 Llama 4에서 편향 문제를 해결하고자 많은 노력을 기울였는데요. 논쟁적 주제에서 답변을 거부하는 비율을 Llama 3.3의 7% → 2% 이하로, 특정 관점에만 불균형적으로 답변 거부하는 현상도 1% 이하로 감소시켰습니다. 정치적 성향이 강하게 드러나는 답변 비율도 Llama 3.3 대비 절반 이하로 낮춰 중립 수준입니다. - 찾아가는 서비스
Llama 모델은 우리가 찾아가지 않아도, 우리 곁에 있습니다. 메타가 Llama 4 시리즈를 기반으로 한 Meta AI를 WhatsApp, 페이스북 메신저, 인스타그램, 그리고 Meta.ai 웹사이트에 탑재했기 때문입니다. 이제 수십억 명의 일상 속에 Llama 4가 자연스럽게 녹아들기 시작했습니다. 메타가 글로벌 플랫폼 차원의 AI 침투를 시작했다고 볼 수 있습니다.*우리나라는 아직 Meta AI가 적용되지 않습니다.
인스타그램에서 사용 가능한 Meta AI. 출처: Plannthat.com
얼마 전 샘 올트먼이 올린 트윗입니다:
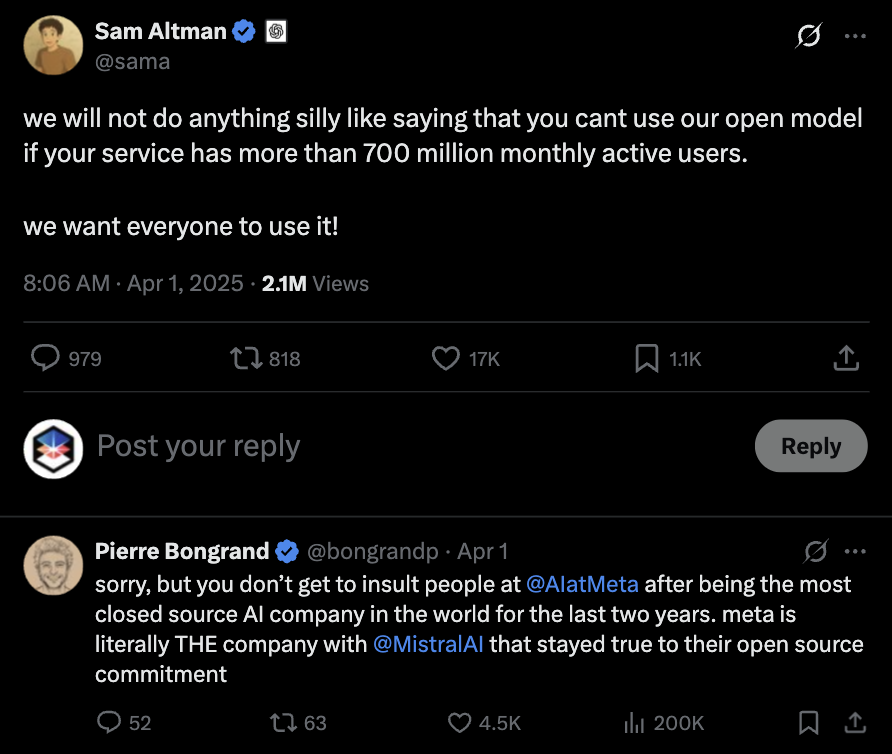
우리는 서비스 월간 활성 사용자 수(MAU)가 7억 명을 넘는다고 해서, 오픈 모델 사용을 막는 어이없는 일은 하지 않을 거야.
우리는 모두가 자유롭게 쓰길 바라거든!
7억 MAU 이상의 기업은 Llama 사용시 별도 허가가 필요한 메타의 방침을 겨냥하는 말입니다. 이에 한 사용자가 답합니다:
미안하지만, 지난 2년 동안 세계에서 가장 폐쇄적인 AI 회사를 운영한 당신은 메타AI를 모욕할 자격 없어.
메타야말로 Mistral AI와 함께 오픈소스 약속을 진정으로 지켜온 회사라고.
빨리 가려면 혼자 가고, 멀리 가려면 함께 가라는 말이 있습니다. 오픈AI는 현재 생성형 AI에서 단연 선두입니다. 하지만 메타가 다양한 정보를 공개함으로써 업계 자체의 발전을 돕는다는 사실은 부정할 수 없습니다. 기업이 자신의 영업기밀에 해당하는 정보를 굳이 공개할 필요는 없습니다. 하지만 시간이 지나면 누가, 어떤 숲을 보고 있었는지 드러날 것입니다.


