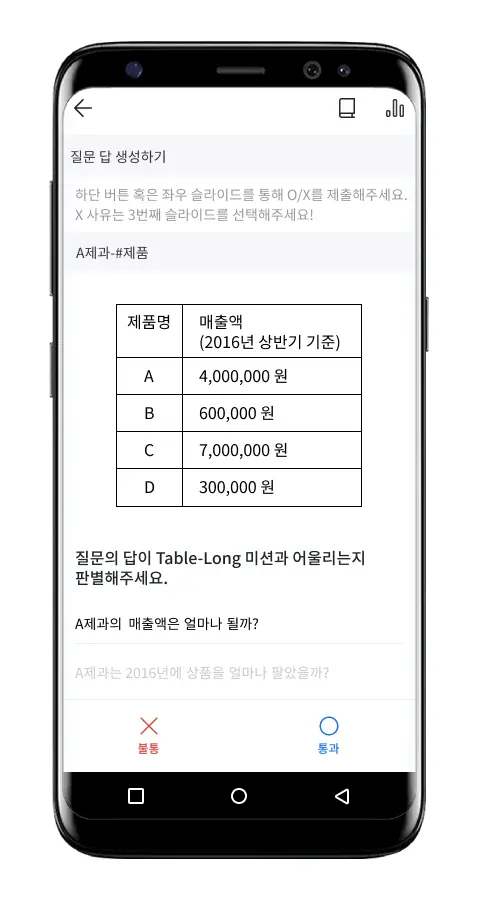
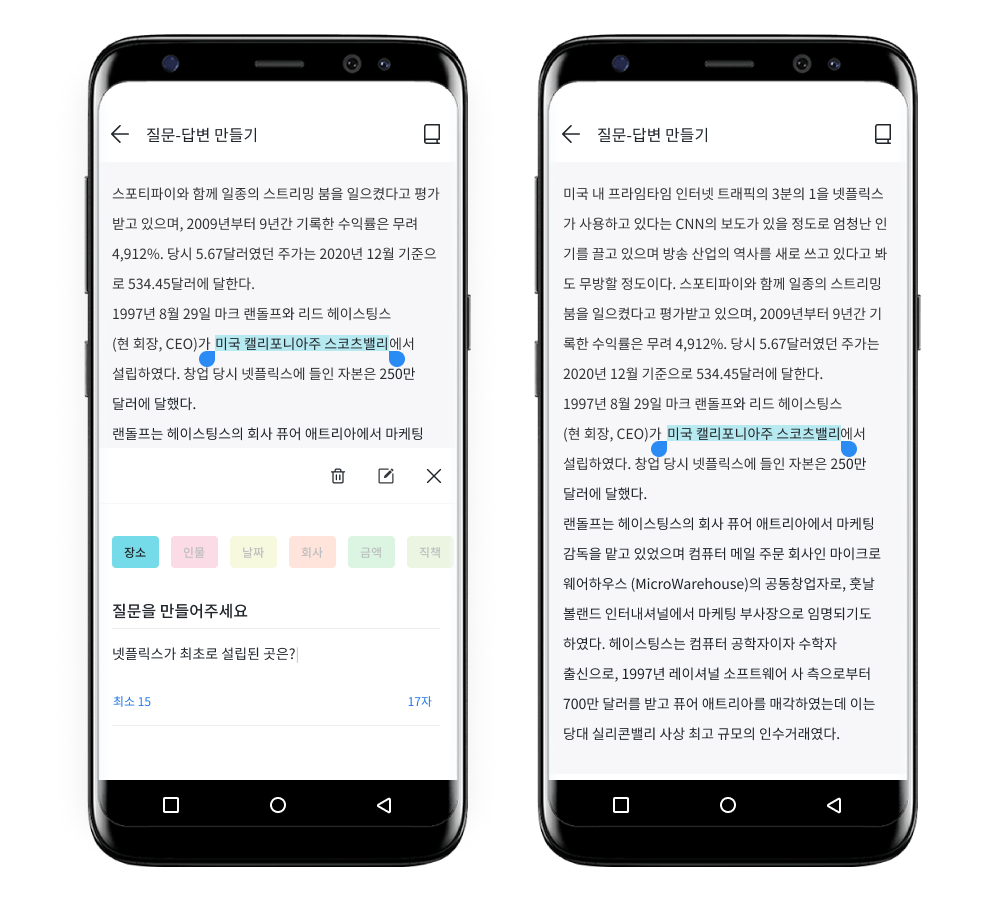
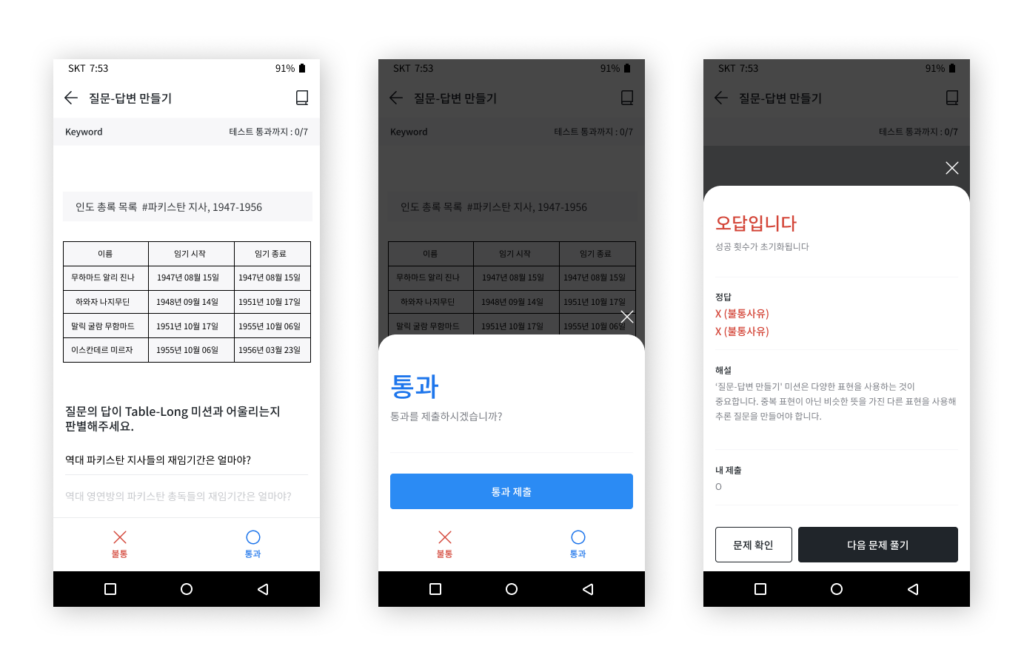
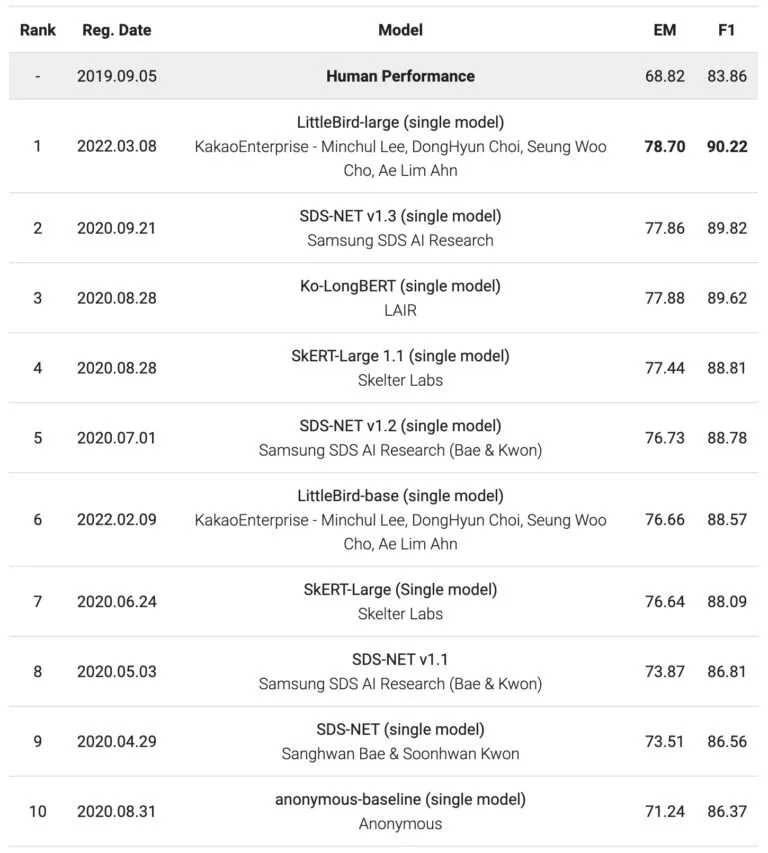
Short 답변 예시
| Short 답변 | ||||
| 구문 변형 (48.0%) | Q. 외국인들을 위해 먹는 샘물이 일시 판매되었던 년도는 언제일까? | |||
| ‧‧‧1988년 서울 올림픽 무렵 외국인들을 위하여 일시 판매를 허용했던 적이 있으나, 다시 판매를 제한하였다.‧‧‧ | ||||
| 어휘 변형 (15.4%) | Q. 2009년 시즌 도중 경질된 지바 롯데의 감독은? | |||
| ‧‧‧시즌 도중에 바비 밸러나인 감독의 해임이 발표되자 일부 팬들은‧‧‧ | ||||
| 여러 문장 종합적 활용 (8.0%) | Q. 'Don't Cha'는 한국 휴대전화 기기 제조사의 휴대전화 CM송으로도 사용되었는데 그 제조사는 어디인가? | |||
| ‧‧‧첫 싱글 'Don't Cha'는 영국, 오스트레일리아, 캐나다 등의 나라에서 1위에‧‧‧ 또한 이 노래는 한국의 휴대전화 기기 제조사 SKY의 휴대전화 CM송으로 쓰여‧‧‧ | ||||
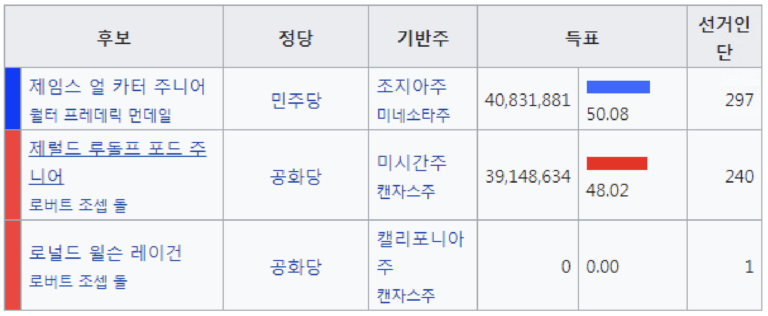
| 표/리스트 (27.7%) | Q. 득표율 2위를 한 사람은 어느 정당 소속인가? | |||
 | ||||
| 기타 출제 오류 (0.9%) | Q.꽃가루가 식물에 전이되어 수정을 거쳐 유성 생식에 이를 수 있게 하는 과정을 일으키는 말은? (지문에서 관련 설명을 찾을 수 없음) | |||
| ‧‧‧이것으로 파리를 불러들여 수분(꽃가루받이)을 한다고 한다. 꽃덮이조각은‧‧‧ | ||||